树的定义与基本术语
树型结构是一类重要的非线性数据结构,其中以树和二叉树最为常用,是以分支关系定义的层次结构。树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构;在计算机领域中也有广泛应用,如在编译程序中,可用树来表示源程序的语法结构;在数据库系统中,树型结构也是信息的重要组织形式之一;在机器学习中,决策树,随机森林,GBDT等是常见的树模型。
树(Tree)是n(n≥0)个结点的有限集。在任意一棵树中:(1)有且仅有一个特定的称为根(Root)的节点;(2)当n>1n>1时,其余节点可分为m(m>0)m(m>0)个互不相交的有限集T1,T2,...,Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
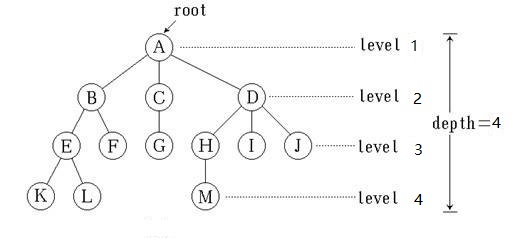
在图1,该树一共有13个节点,其中A是根,其余节点分成3个互不相交的子集:T1={B,E,F,K,L},T2={C,G},T3={D,H,I,J,M};T1,T2和T3都是根A的子树,且本身也是一棵树。例如T1,其根为B,其余节点分为两个互不相交的子集;T11={E,K,L},T12={F}。T11和T12都是B的子树。而在T11中E是根,{K}和{L}是E的两棵互不相交的子树,其本身又是只有一个根节点的树。
接下来讲一下树的基本术语。
树的结点包含一个数据元素及若干指向其子树的分支。节点拥有的子树数量称为节点的度(Degree)。在图1中,A的度为3,B的度为2,C的度为1,F的度为0。度为0的结点称为叶子(Leaf)结点。在图1中,K,L,F,G,M,I,J都是该树的叶子。度不为0的结点称为分支结点。树的度是指树内个结点的度的最大值。
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)。在图1,中,D是A的孩子,A是D的双亲。同一个双亲的孩子之间互称兄弟(Sibling)。在图1中,H,I,J互为兄弟。结点的祖先是从根到该结点所经分支上的所有结点。在图1中,M的祖先为A,D,H。对应地,以某结点为根的子树中的任一结点都称为该结点的子孙。在图1中,B的子孙为E,F,K,L。
树的层次(Level)是从根开始,根为第一层,根的孩子为第二层等。双亲在同一层的结点互为同兄弟,在图1中,K,L,M互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度,在图1中,树的深度为4。
如果将树中结点的各子树看成从左到右是有次序的(即不能交换),则称该树为有序树,否则为无序树。
森林(Forest)是m(m≥0)m(m≥0)棵互不相交的树的集合。对树中每个结点而言,其子树的集合即为森林。在机器学习模型中,决策树为树型结构,而随机森林为森林,是由若干决策树组成的森林。
二叉树的定义与基本性质
二叉树(Binary Tree)是一种特殊的树型结构,它的特点是每个结点至多有两棵子树(即二叉树中不存在度大于2的结点),且二叉树的子树有左右之分,其次序不能任意颠倒(有序树)。
根据二叉树的定义,其具有下列重要性质:(这里不给出证明,证明细节可参考清华大学出版社 严蔚敏 吴伟民的《数据结构(C语言版)》)
一颗深度为k的二叉树,最du多有(2^k)-1个节点,第zhik层最大节点数为dao2^(k-1)次方。
性质1:二叉树的第i层上至shu多有2i-1(i≥1)个节点。
性质2:深度为h的二叉树中至多含有2h-1个节点。
性质3:若在任意一棵二叉树中,有n0个叶子节点,有n2个度为2的节点,则必有n0=n2+1。
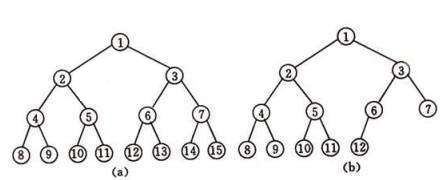
一棵深度为k且有(2^k)-1个结点的二叉树称为满二叉树。深度为k,结点数数n的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号为1至n的结点一一对应时,称之为完全二叉树。在下图2中,(a)为满二叉树,(b)为完全二叉树。
下面介绍完全二叉树的两个特性:
性质4:具有n个节点的完全二叉树深为log2x+1(其中x表示不大于n的最大整数)。
性质5)如果对一棵有n个结点的完全二叉树的结点按层序编号(从第一层到最后一层,每层从左到右),则对任一结点i(1≤i≤n),有:
(1)如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲结点为[1/2]。
(2)如果2i>n,则结点i无左孩子;否则其左孩子是结点2i。
(3)如果2i+1>n,则结点i无右孩子;否则其右孩子是结点2i+1。
介绍完了二叉树的定义及基本性质,接下来,我们需要了解二叉树的遍历。所谓二叉树的遍历,指的是如何按某种搜索路径巡防树中的每个结点,使得每个结点均被访问一次,而且仅被访问一次。对于二叉树,常见的遍历方法有:前序遍历,中序遍历,后序遍历,层序遍历。这些遍历方法一般使用递归算法实现。
前序遍历的操作定义为:若二叉树为空,为空操作;否则(1)访问根节点;(2)先序遍历左子树;(3)先序遍历右子树。
中序遍历的操作定义为:若二叉树为空,为空操作;否则(1)中序遍历左子树;(2)访问根结点;(3)中序遍历右子树。
后序遍历的操作定义为:若二叉树为空,为空操作;否则(1)后序遍历左子树;(2)后序遍历右子树;(3)访问根结点。
层序遍历的操作定义为:若二叉树为空,为空操作;否则从上到下、从左到右按层次进行访问。
其中,前序遍历、中序遍历、后续遍历都属于深度优先遍历,层序遍历属于广度优先遍历。
下面对下图简单的二叉树进行创建和遍历:


# !/usr/bin/env python
# -*-encoding: utf-8-*-
class TreeNode(object):
res = []
def __init__(self, data, left=None, right=None):
self.data = data
self.left = left
self.right = right
def get_data(self):
if self.data is not None:
print(self.data)
return self.data
print(None)
return None
def get_left(self):
if self.left is not None:
return self.left.get_data()
print(None)
return None
def get_right(self):
if self.right is not None:
return self.right.get_data()
print(None)
return None
def pre_order(self, start_node):
"""前序遍历,根—左—右,先访问根节点,再先序遍历左子树,然后再先序遍历右子树"""
if start_node is None:
return
self.res.append(start_node.data)
self.pre_order(start_node.left)
self.pre_order(start_node.right)
def in_order(self, start_node):
"""中序遍历,左—根—右,先中序访问左子树,然后访问根,最后中序访问右子树"""
if start_node is None:
return
self.in_order(start_node.left)
self.res.append(start_node.data)
self.in_order(start_node.right)
def back_order(self, start_node):
"""后续遍历,左—右—根,先后序访问左子树,然后后序访问右子树,最后访问根"""
if start_node is None:
return
self.back_order(start_node.left)
self.back_order(start_node.right)
self.res.append(start_node.data)
def bfs(self, start_node):
"""层次遍历,广度优先遍历,利用队列,先将根入栈,再将根出栈,并将根的左子树,右子树存入队列,按照队列的先进先出规则来实现层次遍历"""
if start_node is None:
return
que = []
que.append(start_node)
while que:
cur_node = que.pop(0)
self.res.append(cur_node.data)
if cur_node.left:
que.append(cur_node.left)
if cur_node.right:
que.append(cur_node.right)
def bfs_res_by_level(self, start_node):
"""层次遍历,广度优先遍历,利用队列,先将根入栈,再将根出栈,并将根的左子树,右子树存入队列,按照队列的先进先出规则来实现层次遍历"""
if start_node is None:
return
que = []
que.append(start_node)
res_all = []
while que:
res_level = []
for _ in range(len(que)):
cur_node = que.pop(0)
if cur_node:
res_level.append(cur_node.data)
if cur_node.left:
que.append(cur_node.left)
if cur_node.right:
que.append(cur_node.right)
if res_level:
res_all.append(res_level)
print(res_all)
def dfs(self, start_node):
"""深度优先遍历,利用栈,先将根入栈,再将根出栈,并将根的右子树,左子树存入栈,按照栈的先进后出规则来实现深度优先遍历。"""
if start_node is None:
return
stack = []
stack.append(start_node)
while stack:
cur_node = stack.pop()
self.res.append(cur_node.data)
if cur_node.right:
stack.append(cur_node.right)
if cur_node.left:
stack.append(cur_node.left)
if __name__ == "__main__":
print("===========创建二叉树==============")
A = TreeNode('A')
B = TreeNode('B')
C = TreeNode('C')
D = TreeNode('D')
E = TreeNode('E')
F = TreeNode('F')
G = TreeNode('G')
H = TreeNode('H')
A.left = B
A.right = C
B.left = D
B.right = E
C.left = F
C.right = G
D.left = H
print("===========打印D节点的值和其孩子==============")
D.get_data()
D.get_left()
D.get_right()
print("===========前序遍历,根—左—右,先访问根节点,再先序遍历左子树,然后再先序遍历右子树==============")
A.res.clear()
A.pre_order(A)
print(A.res)
print("===========中序遍历,左—根—右,先中序访问左子树,然后访问根,最后中序访问右子树==============")
A.res.clear()
A.in_order(A)
print(A.res)
print("===========后续遍历,左—右—根,先后序访问左子树,然后后序访问右子树,最后访问根==============")
A.res.clear()
A.back_order(A)
print(A.res)
print("===========广度优先遍历,利用队列,先将根入栈,再将根出栈,并将根的左子树,右子树存入队列,按照队列的先进先出规则来实现层次遍历==============")
A.res.clear()
A.bfs(A)
print(A.res)
print("===========广度优先遍历,按层返回==============")
A.bfs_res_by_level(A)
print("===========深度优先遍历,利用栈,先将根入栈,再将根出栈,并将根的右子树,左子树存入栈,按照栈的先进后出规则来实现深度优先遍历==============")
A.res.clear()
A.dfs(A)
print(A.res)
print("===========深度优先遍历,从B节点开始==============")
A.res.clear()
A.dfs(B)
print(A.res)