原理:hashMap是以key-value键值对的形式存在着的,大致逻辑为进行put时,根据key值,进行hashing,生成hashcode,对应到bucket的位置然后在当前位置进行key-value存储。
HASH算法?
根据key值对应的每个字符的阿斯克码的和再取模于的map长度得出的值都是固定的对应的下标值
存储过程中 发生hash碰撞会怎么处理?
hash碰撞指的就是可能不同的key值 进行hashing所生成的hashcode是相同的,也就意味着 bucket的位置也会相同,这个时候hashmap中的key-value对象会以链表的数据结构存储。
链表的长度过长 每次取值都要挨个用key值 进行equals 比对 查询效率低下,怎么处理?
JDK1.8之后 hashMap 采用 数组 + 链表 + 红黑树的 数据结构 ,如果链表的长度 大于8 ,该链表将会转为红黑树的数据结构进行存储 大大提高查询效率, 如果当前数据长度小于6时 红黑树 又会转为链表的形式进行存储
存储过程中 hashMap bucket位置不够了怎么处理?
hashMap在put的时候会进行判断 当前map中的长度 如果要存储的长度大于 当前长度*0.75 时 会进行扩容 扩容的长度为当前的长度*2 (当前长度为16 * 0.75 = 12 比如要存13时 会触发扩容机制 扩容后的长度为32),扩容后的数据 会进行重新hash 放到新的bucket位置
扩容存在的问题 JDK1.7之前采用的头插法 在多线程情况下 会产生死循环的情况 1.7之后 改为尾插法 解决了这个问题 多线程 情况下 还是不要用hashMap
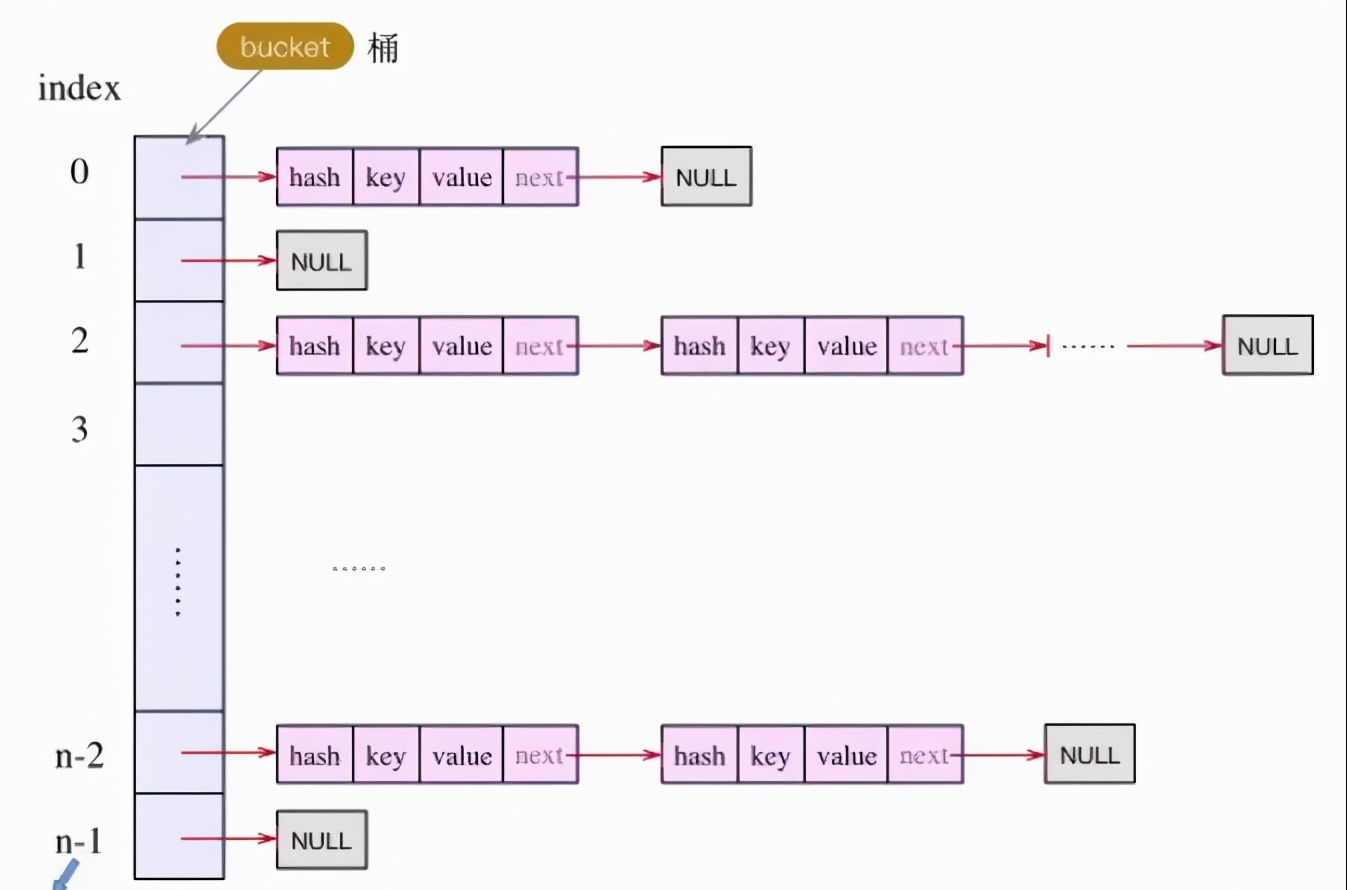
1.7 以前的数据结构
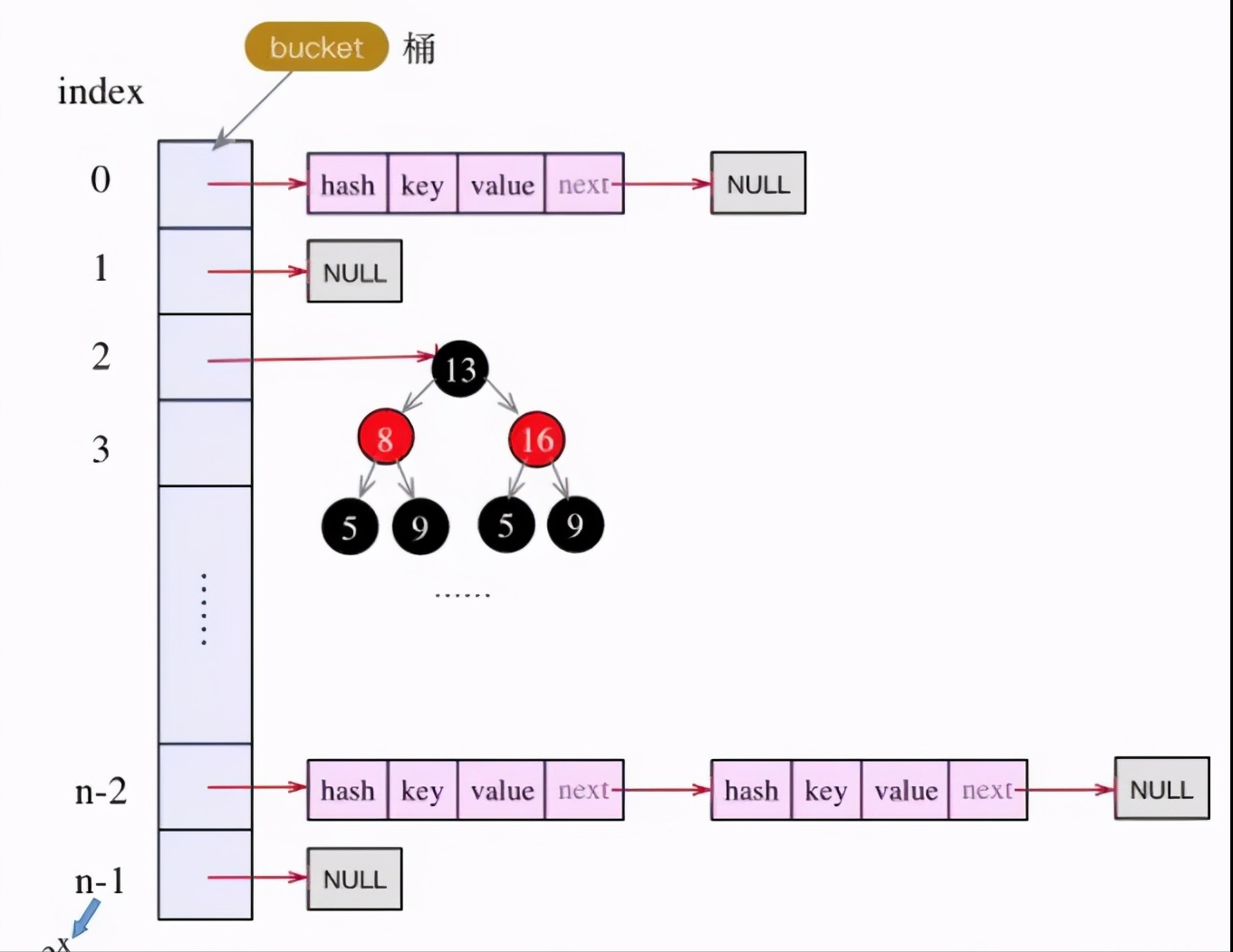
1.8的数据结构