1. 基本介绍
贝叶斯分类是基于贝叶斯定理和属性特征条件独立性的分类方法。
大学《概率论与数理统计》课程中,条件概率的表达式:
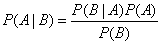
2. scikit-learn示例
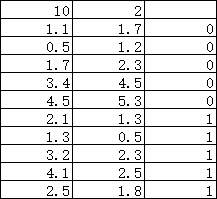
10个训练样本,二分类0/1
2.1 模块导入
import csv
import numpy as np
from sklearn.naive_bayes import GaussianNB
import matplotlib.pyplot as plt
2.2 文本数据加载
def load_data():
'''
load file data
'''
with open('F:/study/AI/src/ml/sklearn/bayes.csv') as csv_file:
data = csv.reader(csv_file)
first_row = next(data)
n_sample = int(first_row[0])
n_feature = int(first_row[1])
train_sets = np.empty((n_sample, 2), dtype=np.float64)
target_sets = np.empty((n_sample), dtype=np.int)
for i, ir in enumerate(data):
train_sets[i] = np.asarray(ir[:-1], dtype=np.float64)
target_sets[i] = np.asarray(ir[-1], dtype=np.int)
return n_sample, n_feature, train_sets, target_sets
2.3 Test
if __name__ == '__main__':
n_sample, n_feature, train_sets, target_sets = load_data()
print("样本数:",n_sample)
print("特征数:",n_feature)
print("训练数据集:\n", train_sets)
print("样本数据对应的分类:\n", target_sets)
bayes = GaussianNB().fit(train_sets, target_sets).predict([[3.0, 4.0]])
print("预测样本[3.0,4.0]的分类结果:", bayes)
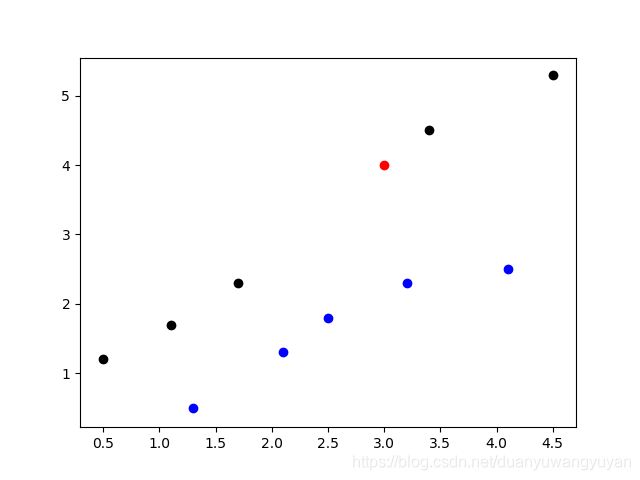
plt.scatter(train_sets[:5,0], train_sets[:5,1], color = 'black')
plt.scatter(train_sets[5:,0], train_sets[5:,1], color = 'blue')
plt.scatter([3.0], [4.0], color='red')
plt.show()
2.4 结果打印
样本数: 10
特征数: 2
训练数据集:
[[1.1 1.7]
[0.5 1.2]
[1.7 2.3]
[3.4 4.5]
[4.5 5.3]
[2.1 1.3]
[1.3 0.5]
[3.2 2.3]
[4.1 2.5]
[2.5 1.8]]
样本数据对应的分类:
[0 0 0 0 0 1 1 1 1 1]
预测样本[3.0,4.0]的分类结果: [0]
2.5 结果图示
3. 基本算法示例
此例子,参考博客:https://blog.csdn.net/qq_25948717/article/details/81744277。谢谢博主的分享。示例稍作改变,将组合进行了去重。
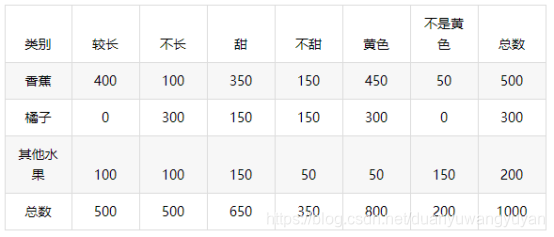
3.1 样本数据
3.2 条件概率公式
针对以下条件的概率公式
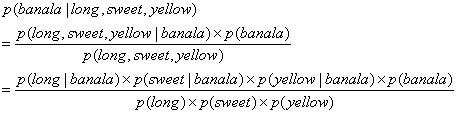
3.3 代码
3.3.1 特征组合
这里做了稍微的改变,原博客的特征组合有重复的。
#!/usr/bin/python
# encoding: utf-8
from functools import reduce
def gen_features(data_list, code=''):
def zuhe(list1,list2):
return [(i+code+j) for i in list1 for j in list2]
return reduce(zuhe, data_list)
def get_feats(data_list):
res = gen_features(data_list, ',')
res_list = []
for value in res:
res_list.append(value.split(','))
return res_list
if __name__ == '__main__':
data = [['long', 'not_long'], ['sweet', 'not_sweet'], ['yellow', 'not_yellow']]
print(get_feats(data))
3.3.2 条件概率计算
# !usr/bin/python
# encoding : utf-8
datasets = {'banala':{'long':400,'not_long':100,'sweet':350,'not_sweet':150,'yellow':450,'not_yellow':50},
'orange':{'long':0,'not_long':300,'sweet':150,'not_sweet':150,'yellow':300,'not_yellow':0},
'other_fruit':{'long':100,'not_long':100,'sweet':150,'not_sweet':50,'yellow':50,'not_yellow':150}
}
def calcu_fruit_total(data):
'''
calculate number for every fruit, and calculate
only calculate the sum of "long" and "not_long" for fruit.
Paras:
data: trained data sets
Result:
total_num = 1000 #fruit total number
fruit_count = {'banala':500, 'orange':300, 'other_fruit':200}
'''
total_num = 0
fruit_count = {}
for fruit in data:
fruit_count[fruit] = data[fruit]['long'] + data[fruit]['not_long']
total_num += fruit_count[fruit]
return total_num, fruit_count
def feature_prob(data):
'''
calculate probability of every feature.
Paras:
data: trained data sets
Result:
feature_count = {'not_long':0.5, 'not_sweet':0.35, 'not_yellow':0.2,
'sweet':0.65, 'yellow':0.8, 'long':0.5}
'''
feature_count = {}
flag = True
total_num, fruit_count = calcu_fruit_total(data)
feature_list = data['banala'].keys()
for feature in feature_list:
number = 0
for fruit in data:
number += int(data[fruit][feature])
feature_count[feature] = number/total_num
# for feature in feature_count:
# print("feature : ", feature, ', num : ', feature_count[feature])
return feature_count
def feature_cond_prob(data):
'''
calculate every feature probability for known fruit.
Paras:
data: trained data sets
Results:
res = {'banala':{'long':0.8,'not_long':0.2,'sweet':0.7,'not_sweet':0.3,'yellow':0.9,'not_yellow':0.1},
'orange':{'long':0.0,'not_long':1.0,'sweet':0.5,'not_sweet':0.5,'yellow':1.0,'not_yellow':0.0},
'other_fruit':{'long':0.5,'not_long':0.5,'sweet':0.75,'not_sweet':0.25,'yellow':0.25,'not_yellow':0.75}
}
'''
res = {}
total_num, fruit_count = calcu_fruit_total(data)
for fruit in data:
res[fruit] = {}
features = data[fruit]
for key in features:
res[fruit][key] = features[key]/fruit_count[fruit]
# print(fruit, key, res[fruit][key])
return res
def fruit_prob(data):
'''
calculate every fruit probability.
Paras:
data: trained data sets
Result:
res = {'banala':0.5, 'orange':0.3, 'other_fruit':0.2}
'''
res = {}
total_num, fruit_count = calcu_fruit_total(data)
for fruit in fruit_count:
res[fruit] = fruit_count[fruit]/total_num
# for key, value in res.items():
# print(key, value)
return res
class Bayes_Classify():
'''
Bayes Classify class
'''
def __init__(self, data = datasets):
'''
init datasets,feature_prob,feature_cond_prob,fruit_prob
'''
self.data = datasets
self.feature_prob = feature_prob(self.data)
self.feature_cond_prob = feature_cond_prob(self.data)
self.fruit_prob = fruit_prob(self.data)
self.fruit_list = [key for key in self.data.keys()]
def get_fruit_cond_prob(self, features_combination):
'''
get fruit classify result for known feature condition.
Paras:
features_combination: A combination of features.
For example: ['not_long', 'not_sweet', 'not_yellow']
Result:
res: a dictionary that every fruit prob for particular feature combination.
For example: {'orange': 0.0, 'banala': 0.08571428571428573, 'other_fruit': 0.5357142857142858}
'''
res = {}
for fruit in self.fruit_list:
prob = self.fruit_prob[fruit]
for features_comb in features_combination:
prob *= self.feature_cond_prob[fruit][features_comb]\
/self.feature_prob[features_comb]
res[fruit] = prob
# print(fruit, prob)
return res
if __name__ == '__main__':
# total_num, fruit_count = calcu_fruit_total(datasets)
# print('total_num = ', total_num)
# for key in fruit_count:
# print("key ", key, " = ", fruit_count[key])
# feature_count = feature_prob(datasets)
# res = fruit_prob(datasets)
# res = feature_cond_prob(datasets)
# features_combination = ['long', 'sweet', 'yellow']
# classifer = Bayes_Classify()
# classifer.get_fruit_cond_prob(features_combination)
print("bayes_comp test end")
3.3.3 测试
# !/user/bin/python
# encoding : utf-8
from bayes_comp import Bayes_Classify
from generate_features import get_feats
features_combination = [['long', 'not_long'], ['sweet', 'not_sweet'], ['yellow', 'not_yellow']]
def main():
feat_combs = get_feats(features_combination)
classifer = Bayes_Classify()
for zuhe in feat_combs:
print("特征值:",end='\t')
print(zuhe)
print("预测结果:", end='\t')
res = classifer.get_fruit_cond_prob(zuhe)
print(res)#预测属于哪种水果的概率
print('水果类别:',end='\t')
#对后验概率排序,输出概率最大的标签
print(sorted(res.items(), key=lambda d:d[1], reverse=True)[0][0])
print('\n')
if __name__ == '__main__':
main()
3.3.4 结果
特征值: ['long', 'sweet', 'yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.07211538461538461, 'banala': 0.9692307692307693}
水果类别: banala
特征值: ['long', 'sweet', 'not_yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.8653846153846153, 'banala': 0.4307692307692308}
水果类别: other_fruit
特征值: ['long', 'not_sweet', 'yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.04464285714285715, 'banala': 0.7714285714285716}
水果类别: banala
特征值: ['long', 'not_sweet', 'not_yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.5357142857142858, 'banala': 0.3428571428571429}
水果类别: other_fruit
特征值: ['not_long', 'sweet', 'yellow']
预测结果: {'orange': 0.5769230769230769, 'other_fruit': 0.07211538461538461, 'banala': 0.24230769230769234}
水果类别: orange
特征值: ['not_long', 'sweet', 'not_yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.8653846153846153, 'banala': 0.1076923076923077}
水果类别: other_fruit
特征值: ['not_long', 'not_sweet', 'yellow']
预测结果: {'orange': 1.0714285714285714, 'other_fruit': 0.04464285714285715, 'banala': 0.1928571428571429}
水果类别: orange
特征值: ['not_long', 'not_sweet', 'not_yellow']
预测结果: {'orange': 0.0, 'other_fruit': 0.5357142857142858, 'banala': 0.08571428571428573}
水果类别: other_fruit