今天和大家简单介绍 JAVA 中常见的 Map 类型,可以根据业务场景选择适合自己的 Map,每种 Map类型的详细用法请参考 JDK 文档。
1.HashMap
查找效率高,但容器内部的元素是无序的,在取出的时候无法保证其插入顺序。
public static void main(String[] args) {
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Tom", 1);
hashMap.put("Bob", 2);
hashMap.put("Jack", 3);
hashMap.put("Andy", 4);
hashMap.put("Lucy", 5);
Set<String> strings = hashMap.keySet();
for (String str : strings) {
System.out.println(str + " " + hashMap.get(str));
}
}
Tom 1
Bob 2
Lucy 5
Jack 3
Andy 4
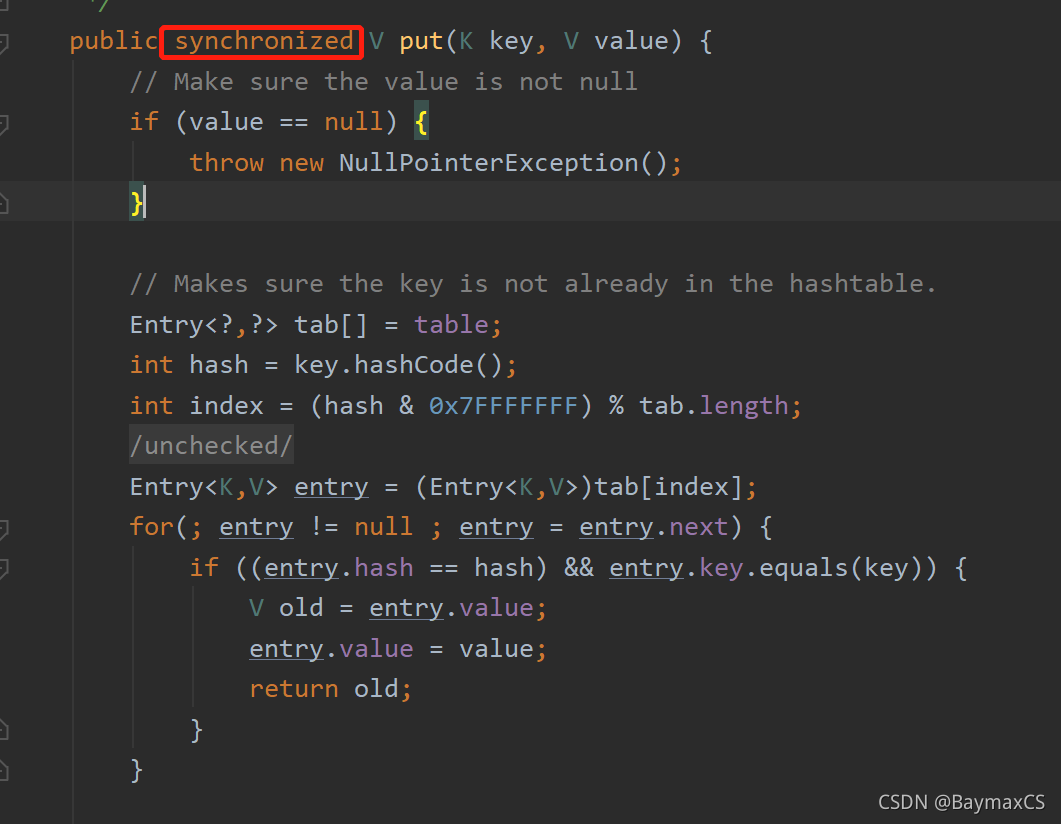
2.HashTable
HashTable 用法与 HashMap 基本一致,是 JDK 早期提供的 Hash 算法容器结构,其内部的方法都实现了同步机制,在性能上不及 HashMap 。当不需要考虑线程安全的前提下,更推荐使用 HashMap 。
public static void main(String[] args) {
Hashtable<String, Integer> hashtable = new Hashtable<>();
hashtable.put("Tom", 1);
hashtable.put("Bob", 2);
hashtable.put("Jack", 3);
hashtable.put("Andy", 4);
hashtable.put("Lucy", 5);
Set<String> strings = hashtable.keySet();
for (String str : strings) {
System.out.println(str + " " + hashtable.get(str));
}
}
Bob 2
Andy 4
Lucy 5
Tom 1
Jack 3
3.TreeMap
TreeMap 可以保证遍历时根据 Key 来排序,Key 必须实现 Comparable 接口,下例中的 String 已经默认实现了 Compare 接口。
public static void main(String[] args) {
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Tom", 1);
treeMap.put("Bob", 2);
treeMap.put("Jack", 3);
treeMap.put("Andy", 4);
treeMap.put("Lucy", 5);
Set<String> strings = treeMap.keySet();
for (String str : strings) {
System.out.println(str + " " + treeMap.get(str));
}
}
Andy 4
Bob 2
Jack 3
Lucy 5
Tom 1

4.LinkedHashMap
LinkedHashMap 可以保证元素的插入顺序,遍历效率高,但在插入方面的性能不及 HashMap。
public static void main(String[] args) {
LinkedHashMap<String, Integer> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("Tom", 1);
linkedHashMap.put("Bob", 2);
linkedHashMap.put("Jack", 3);
linkedHashMap.put("Andy", 4);
linkedHashMap.put("Lucy", 5);
Set<String> strings = linkedHashMap.keySet();
for (String str : strings) {
System.out.println(str + " " + linkedHashMap.get(str));
}
}
Tom 1
Bob 2
Jack 3
Andy 4
Lucy 5
5.IdentityHashMap
IdentityHashMap 使用 == 来比较 key 是否重复(比较内存地址),而其他的 Map 是比较 equals() 和 hashCode() 的返回值,两个方法返回值相同,才认为元素相等。
下例中重写了 Fruit 的 equals() 和 hashCode(),名字相同的对象则认为相等,故 HashMap 中无法放入名字相同的 Fruit,而 IdentityHashMap 使用 == 比较内存地址,故不受此影响。
public class MapDemo {
private static class Fruit {
private int id;
private String name;
public Fruit(int id, String name) {
this.id = id;
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
//名字相等则认为对象相等
Fruit fruit = (Fruit) obj;
return getName().equals(fruit.getName());
}
@Override
public int hashCode() {
//重新方法,相同的名字返回相同的hash值
int result = 17;
result = 31 * result + getName().hashCode();
return result;
}
}
public static void main(String[] args) {
Fruit f1 = new Fruit(1, "apple");
Fruit f2 = new Fruit(2, "apple");
HashMap<Fruit, String> hashMap = new HashMap<>();
hashMap.put(f1, f1.getName());
hashMap.put(f2, f2.getName());
System.out.println(hashMap);
IdentityHashMap<Fruit, String> identityHashMap = new IdentityHashMap<>();
identityHashMap.put(f1, f1.getName());
identityHashMap.put(f2, f2.getName());
System.out.println(identityHashMap);
}
}
{
mtn.baymax.charpter17.MapDemo$Fruit@58b8569=apple}
{
mtn.baymax.charpter17.MapDemo$Fruit@58b8569=apple, mtn.baymax.charpter17.MapDemo$Fruit@58b8569=apple}
6.WeakHashMap
WeakHashMap 中的 key 是弱引用,当其引用的 key 被置为 null 后,一旦垃圾回收机制触发,其内部存储的弱引用 key 就会被自动移除,WeakHashMap 适合用作缓存。
public static void main(String[] args) {
String a = new String("A");
String b = new String("B");
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put(a, 1);
hashMap.put(b, 2);
System.out.println(hashMap);
WeakHashMap<String, Integer> weakHashMap = new WeakHashMap<>();
weakHashMap.put(a, 1);
weakHashMap.put(b, 2);
System.out.println(weakHashMap);
hashMap.remove(a);
a = null;
//手动执行垃圾回收
System.gc();
System.out.println(weakHashMap);
}
{
A=1, B=2}
{
B=2, A=1}
{
B=2}
本次分享至此结束,希望本文对你有所帮助,若能点亮下方的点赞按钮,在下感激不尽,谢谢您的【精神支持】。
若有任何疑问,也欢迎与我交流,若存在不足之处,也欢迎各位指正!