一、Map集合
由于Map集合的每一个元素是由键和值组成的,所以他具有将对象映射到对象的能力。
- containsKey()——查看集合中是否包含某键值。
- containsValue()——查看是否包含某个值。
- keySet()——获取所有键
- values()——获取所有值
- get()——获取指定键对应的值
Map可以很容易被扩展为多维:
Map<Person,List<String>> map=new HashMap<Person,List<String>>();//可以存储每个人拥有多少本书
import java.util.*;
public class Box{
public static void main(String[] args){
Map<String,List<String>> map=new HashMap<String,List<String>>();
map.put("Luck",Arrays.asList("A_Book","B_Book","C_Book"));
map.put("Kate",Arrays.asList("D_Book","E_Book","F_Book"));
map.put("Dawn",Arrays.asList("Q_Book","X_Book","Y_Book"));
map.put("Marry",Arrays.asList("G_Book","H_Book","I_Book"));
System.out.println("map: "+map);
//判断集合中是否包含某个键
System.out.println("containsKey: "+map.containsKey("Luck"));
//判断集合中是否包含某个值
System.out.println("containsValue: "+map.containsValue(22));
//获取集合中的所有键
for(String people:map.keySet()){
System.out.println("Name: "+people);
}
//获取集合中的所有值
for(List<String> list:map.values()){
System.out.println("AllBooks"+list);
}
//获取指定键对应的值
for(String people:map.keySet()){
System.out.println("Name: "+people);
System.out.println("---"+map.get(people));
}
}
}
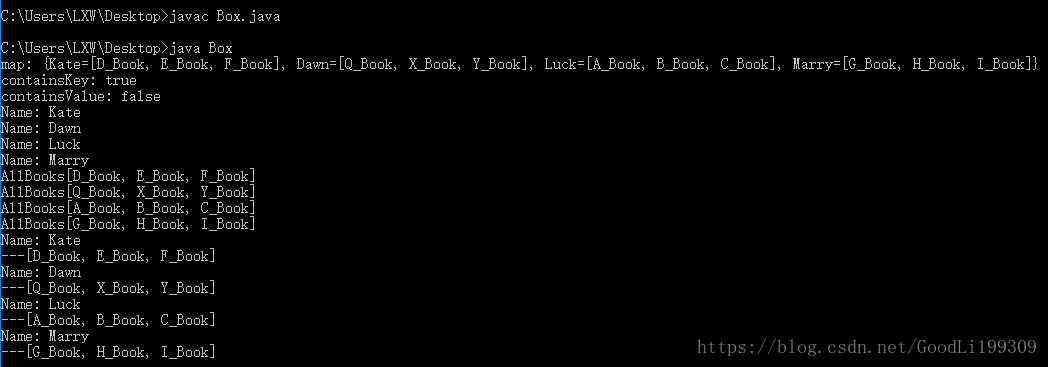
从我们的例子可以发现,Map集合是不能直接使用迭代器的,因为迭代器是针对单列集合设计的。在实际使用中,可以使用foreach进行遍历,或者将Map集合转换成Set集合然后使用迭代器进行遍历。
eg2:
import java.util.*;
public class Box{
public static void main(String[] args){
for(Map.Entry entry:System.getenv().entrySet()){
System.out.println(entry.getKey()+"-----"+entry.getValue());
}
}
}
运行结果:
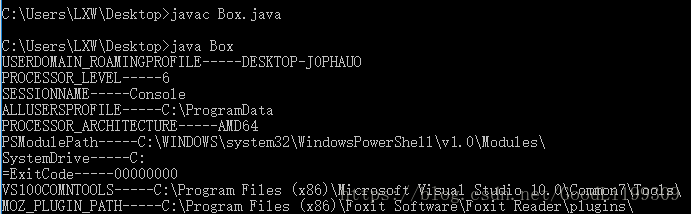
System.getenv()返回的是一个存储电脑所有环境变量的Map集合。Map.entrySet()返回的是一个Set<Map.Entry<K,V>>,Map.Entry 是Map中的一个接口,他的用途是表示一个映射项(里面有Key和Value),而Set<Map.Entry<K,V>>表示一个映射项的Set。Map.Entry里有相应的getKey和getValue方法,即JavaBean,让我们能够从一个项中取出Key和Value。Map也是通过这个方法使用迭代器的。
二、Queue(队列)
——队列是一种先进先出(FIFO)的容器。即从容器的一端放入,从另一端取出,且存放的顺序与取出的顺序是一致的。队列在并发编程中特别重要,因为它们以可安全的将对象从一个任务传输给另一个任务。
LinkedList集合提供了支持队列的方法,并实现了Queue接口,因此LinkedList可以作为Queue的一种实现。在实际使用中一般会将LinkedList向上转型为Queue。
- offer()——在允许的情况下,将一个元素插入到队尾,或者返回false;
- peek()——在不移除元素的情况下返回队头,当对列为空时返回null;
- element()——在不移除元素的情况下返回队头,当队列为空时抛出NoSuchElementException异常;
- poll()——移除元素并返回队头,在队列为空时返回null;
- remove()——移除元素后返回队头,在队列为空时抛出NoSuchElementException异常;
注:之所以在使用LinkedList实现队列时我们采用向上转型,是为了窄化LinkedList,以避免有一些不必要的功能。
小例子:
import java.util.*;
public class Box{
public static void main(String[] args){
Queue<Character> queue=new LinkedList<Character>();
//向队列中存储一组字符
for(char c:"hellojava!".toCharArray()){
queue.offer(c);
}
System.out.print(queue);
System.out.println();
while(queue.peek()!=null){
System.out.print(queue.peek()+"---");
//System.out.print(queue.remove());
System.out.print(queue.poll());
System.out.println();
}
System.out.println();
System.out.print(queue);
}
}
运行结果:

从运行结果可以看出peek()每次返回的和remove()删除的是同一个元素,而且是先进先出的。
——PriorityQueue(优先级队列)
声明下一个弹出元素是最需要的元素,即具有最高优先级的元素。一旦加入优先级这个因素,那么处理的先后顺序将与到达时间无关。所以在PriorityQueue中调用peek()、poll()、remove()方法时,获取的元素都是列表中优先级最高的元素。PriorityQueue可以很容易的和Integer、String、Character一起使用,因为这些类都内建了自然排序,如果我们想在PriorityQueue中使用自己的类,需要建立额外的功能以产生自然排序,或者必须提供自己的Comparator。
import java.util.*;
public class Box{
public static void main(String[] args){
String str=" Hello java and j2ee!";
List<String> list=Arrays.asList(str.split(""));
//按自然排序进行存储
PriorityQueue<String> queue1=new PriorityQueue<String>(list);
System.out.print(queue1);
System.out.println();
//按照自然排序的反序进行存储
PriorityQueue<String> queue=new PriorityQueue<String>(list.size(),Collections.reverseOrder());
queue.addAll(list);
System.out.print(queue);
}
}
三、迭代器
迭代器(一种设计模式)——是一个对象,其可以遍历并选择序列中的对象,因为创建其需付出的代价很小,所以被称为轻量级对象。迭代器可以将遍历序列的操作与序列底层的结构分离,所以其可以统一对容器的访问方式。
*Java中提供了Iterator迭代器——
- 使用Iterator()方法要求容器返回一个Iterator。Iterator将准备好返回序列的第一个元素。
- 使用next()获取序列中的下一个元素。
- 使用hasNext()检查序列中是否还有元素。
- 使用remove()将移除迭代器返回的最后一个元素。
import java.util.*;
public class Box{
public static void main(String[] args){
Set<String> t_box=new TreeSet<String>();
Collections.addAll(t_box,"B,A,C,E,D,F".split(","));
//创建一个迭代器
Iterator it=t_box.iterator();
while(it.hasNext()){
//迭代器的remove方法若放在next()方法前会报错
//it.remove();
System.out.print(it.next()+" ");
it.remove();
break;
}
System.out.println();
//采用for循环同样可以实现集合的遍历
for(String t:t_box){
System.out.print(t+" ");
//但是在遍历中不能进行删除操作,因为每删除一个元素,t_box.size()的大小会发生变化
//t_box.remove(t);
}
}
}
运行结果:
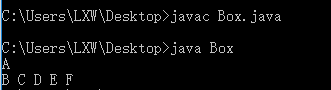
从运行结果可以看出迭代器在遍历的同时可以对集合中的元素进行删除操作,删除迭代器最后返回的值。但是在使用迭代器的删除功能时需要注意俩点:一是,要在.next()方法后使用;二是,不能连续多次使用remove()方法。迭代器之所以可以在遍历中删除元素,是因为其在删除中会维持一个标志来记录目前是不是处于可删除状态。
*Java中提供了ListIterator迭代器——
是一个更加强大的Iterator子类型,但是其只能用于各种List类的访问。要注意的一点是,Iterator只能向前移动,而ListIterator可以双向移动。它可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引,并可以使用set()方法替换它访问过的最优一个元素。
俩个创建方式:
- 调用ListIterator()方法产生一个指向List开始处的迭代器。
- 调用ListIterator(index)方法产生一个指向List中索引为index的元素位置的迭代器。
import java.util.*;
public class Box{
public static void main(String[] args){
List<String> list=new ArrayList<String>();
Collections.addAll(list,"A,B,C,D,E,F".split(","));
//创建遍历列表所有元素的迭代器
ListIterator it=list.listIterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
System.out.println();
//创建遍历下表为3开始的列表元素
ListIterator it_index=list.listIterator(3);
while(it_index.hasNext()){
System.out.print(it_index.next()+" ");
it_index.set("1");//将遍历的元素替换为1
}
System.out.println();
ListIterator it2=list.listIterator();
while(it2.hasNext()){
System.out.print(it2.next()+" ");
}
}
}
运行结果:

从结果可以看出使用迭代器的set()方法,可以将遍历的元素都替换为指定值。
*Foreach与迭代器——
Foreach在遍历集合时之所以能与迭代器有一样的效果,是因为Java SE5引入了新的被称为Iterable的接口,该接口包含一个能产生Iterator的iterator()方法,并且Iterable接口被foreach用来在序列中移动(也就是在foreach的底层实际也是迭代器)。也因此,能够与foreach一起工作成为了所有Collection对象的特性。
*适配器方法惯用法——
想要使用向前和向后迭代的俩种方法遍历一个列表,如果直接继承并覆盖iterator()方法,只能替换现有方法,而不能实现要求。此时使用适配器方法(设计模式的一种思想)的惯用法可以解决问题。
这里不能使用覆盖,而是添加一个能够产生Iterable对象的方法,该对象可以用于foreach语句中。这样我们可以有多种使用foreach的方式:
import java.util.*;
public class Box{
public static void main(String[] args){
List<Integer> list=new ArrayList<Integer>();
Integer[] a={1,2,3,4,5};
list=Arrays.asList(a);
ReversedList<Integer> rl=new ReversedList<Integer>(list);
for(Integer i:rl){
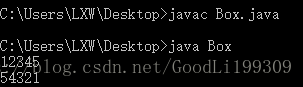
System.out.print(i);
}
System.out.println();
for(Integer i:rl.reversed()){
System.out.print(i);
}
}
}
class ReversedList<T> extends ArrayList<T>{
public ReversedList(Collection<T> c){super(c);}
public Iterable<T> reversed(){
return new Iterable<T>(){
public Iterator<T> iterator(){
return new Iterator<T>(){
int current=size()-1;
public boolean hasNext(){return current>-1;}
public T next(){return get(current--);}
public void remove(){throw new UnsupportedOperationException();}
};
}
};
}
}
运行结果:
——什么是适配器模式:
将一个接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。我的理解是有一些接口我们只需要其中的一部分方法(也许只要一个),有些类我们和其没有继承关系但需要其中的一个或多个方法,此时我们没必要实现接口中的所有方法,更没必要继承一个类(也许此时你已经继承了另一个类),我们要想实现我们的要求就可以通过适配器创建一个新的接口,接口中由我们需要的那些方法,然后创建一个类实现此接口进行方法调配。
总结:
- 数组将数字和对象联系起来。保存类型明确的对象,查询对象不需对结果做类型转换。它可以保存多维的基本类型的数据。但是一旦生成,不能改变其容量。
- Collection保存单一元素,而Map存储键值对类型的数据。泛型确定了应该存放的数据类型,从容器中获取元素时不用进行类型转换。这类容器可以自动改变存放数据的空间大小。不能持有基本类型,但是Java中的自动拆装箱机制可以弥补这一个缺点。
- List集合也建立了数字索引与对象的关联,因此数组和List集合都是排好序的容器,但是List可以自动扩充容量,但是数组不可以。List集合包含了俩个实现类ArrayList和LinkedList,前者适合进行大量的随机访问,后者则更适合进行有大量插入或删除元素的操作。
- Map是一种将对象与对象相关联的设计。HashMap设计用来快速访问;TreeMap保持”键“始终处于排序状态,所以没有HashMap快;LinkedHashMap保持元素插入的顺序,但是也通过散列提供了快速访问的能力。
- Set集合不可以接受重复元素(依赖于equals()),HashSet提供了快速查询速度,而TreeSet保持元素处于排序状态。LinkedHashSet保持元素插入的顺序。
- Vector、Hashtable、Stack已经被淘汰,所以在实际开发中尽量不要使用。
- 生成Iterator是将队列与消费队列的方法连接在一起耦合度最小的方式,并且与实现Collection相比,它在序列类上所施加的约束也少许多。

——点线框表示接口
——实线框表示实现类
——黑色粗线框表示常用容器
——空心箭头表示实现接口
——实心箭头表示可以实现指向类的对象
从这张图中可以很好的看到各个容器之间的关系,需要我们记住他。
----------------------------------------------------------------------
容器的使用在实际开发中至关重要,这里我们需要熟练使用各个集合和迭代器。另一方面从最后的例子中会发现内部类在开发中的重要性,设计模式也需要我们花大功夫去学习,要深刻理解设计模式的思想。