1. 深度和广度优先
1.1 深度优先
前面已经学习过深度和广度优先搜索。为什么叫做深度和广度呢? 其实是针对图的遍历而言的,请看下面这个图:
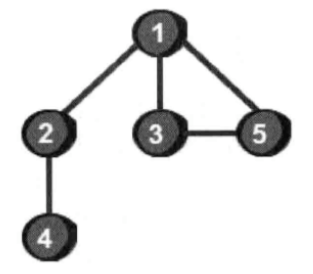
什么是图?简单地说,图就是由一些小圆点(称为顶点)和连接这些小圆点的直线(称为边)组成的。
例如上图是由五个顶点(编号为1、2、3、4、5)和5条边(1-2、1-3、1-5、2-4、3-5)组成。
现在从1号顶点开始遍历这个图,遍历就是指把图的每一个顶点都访问一次。
这五个顶点的被访问顺序如下图。图中每个顶点右上方的数就表示这个顶点是第几个被访问到的。这个数称作——时间戳。
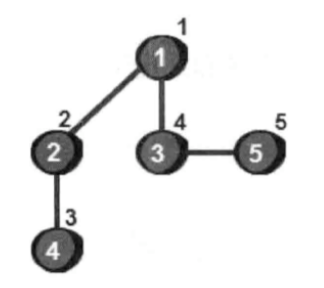
深度优先遍历的主要思想是:
首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;
当没有未访问过的顶点时,则回到上一个顶点,继续试探访问别的顶点,直到所有的顶点都被访问过。
显然,深度优先遍历是沿着图的某一条分支遍历直到末端,然后回溯,再沿着另一条进行同样的遍历,直到所有的顶点都被访问过为止。
那如何存储一个图呢?最常用的方法是使用一个二维数组e来存储,如下:
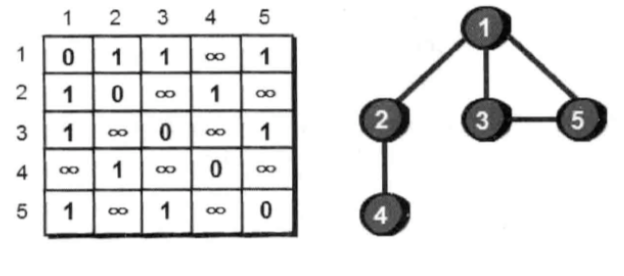
上图二维数组中第i行第j列表示的就是顶点i到顶点j是否有边。1表示有边,∞ 表示没有边。将自己到自己(即i等于j)设为0。
将这种存储图的方法称为图的邻接矩阵存储法。
这个二维数组是沿主对角线对称的,因为上面这个图是无向图。
所谓无向图指的就是图的边没有方向,例如边1-5表示,1号顶点可以到5号顶点,5号顶点也可以到1号顶点。
接下来要解决的问题就是如何用深度优先搜索来实现遍历了。
void dfs(int cur) //cur是当前所在的顶点编号
{
printf("%d\n", cur);
sum++;//每访问一个顶点sum就加1
if (sum == n) return;//所有的顶点都已经访问过则直接退出
for (i=1; i<=n; i++) //从1号顶点到n号顶点依次尝试,看哪些顶点与当前顶点cur有边相连
{
//判断当前顶点cur到顶点i是否有边,并判断顶点i是否已访问过
if (e[cur][i]==1 && book[i]==0) {
book[i]=1;//标记顶点i已经访问过
dfs(i);//从顶点i再出发继续遍历
}
}
return;
}
在上面的代码中变量cur存储的是当前正在遍历的顶点,二维数组e存储的就是图的边(邻接矩阵),数组book用来记录哪些顶点已经访问过,变量sum用来记录已经访问过多少个顶点,变量n存储的是图的顶点的总个数。
完整代码如下:
#include <stdio.h>
int book[101], sum, n, e[101][101];
void dfs(int cur) //cur是当前所在的顶点编号
{
int i;
printf("%d\n", cur);
sum++;//每访问一个顶点sum就加1
if (sum == n) return;//所有的顶点都已经访问过则直接退出
for (i=1; i<=n; i++) //从1号顶点到n号顶点依次尝试,看哪些顶点与当前顶点cur有边相连
{
//判断当前顶点cur到顶点i是否有边,并判断顶点i是否已访问过
if (e[cur][i]==1 && book[i]==0) {
book[i]=1;//标记顶点i已经访问过
dfs(i);//从顶点i再出发继续遍历
}
}
return;
}
int main() {
int i, j, m, a, b;
scanf("%d %d", &n, &m);
//初始化二维矩阵
for (i=1; i<=n; i++) {
for (j=1; j<=m; j++) {
if (i==j) {
e[i][j] = 0;
} else {
e[i][j] = 99999999;//这里假设999999999为正无穷
}
}
}
//读入顶点之间的边
for (i=1; i<=m; i++) {
scanf("%d %d", &a, &b);
e[a][b] = 1;
e[b][a] = 1;//这里是无向图,所以需要将e[b][a]也赋为1
}
//从1号城市出发
book[1] = 1;//标记1号顶点已访问
dfs(1);//从1号顶点开始遍历
getchar();getchar();
return 0;
}
数据验证:
5 5
1 2
1 3
1 5
2 4
3 5
返回值:
1 2 4 3 5
1.2 广度优先
使用广度优先搜索来遍历这个图,五个顶点的被访问顺序如下图:
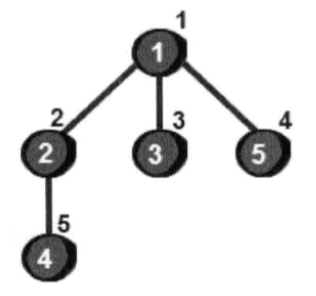
广度优先遍历的主要思想是:
首先以一个未被访问过的顶点作为起始顶点,访问其所有相邻的顶点,然后对每个相邻的顶点,再访问它们相邻的未被访问过的顶点,直到所有顶
点都被访问过,遍历结束。
代码实现如下:
#include <stdio.h>
int main() {
int i, j, n, m, a, b, cur, book[101]={
0}, e[101][101];
int que[1001], head, tail;
scanf("%d %d", &n, &m);
//初始化二维矩阵
for (i=1; i<=n; i++) {
for (j=1; j<=m; j++) {
if (i==j) {
e[i][j] = 0;
} else {
e[i][j] = 99999999;
}
}
}
//读入顶点之间的边
for (i=1; i<=m; i++) {
scanf("%d %d", &a, &b);
e[a][b] = 1;
e[b][a] = 1;//这里是无向图,所以需要将e[b][a]也赋值为1
}
//队列初始化
head = 1;
tail = 1;
//从1号顶点出发,将1号顶点加入队列
que[tail] = 1;
tail++;
book[1] = 1;//标记1号顶点已访问
//当队列不为空的时候循环
while (head < tail) {
cur = que[head];//当前正在访问的顶点编号
for (i=1; i<=n; i++) //从1~n依次尝试
{
//判断从顶点cur到顶点i是否有边, 并判断顶点i是否已经访问过
if (e[cur][i]==1 && book[i]==0) {
//如果从顶点cur到顶点i有边, 并且顶点i没有被访问过, 则将顶点i入队
que[tail] = i;
tail++;
book[i] = 1;//标记顶点i已访问
}
//如果tail大于n, 则表明所有顶点都已经被访问过
if (tail > n) {
break;
}
}
head++;//注意这地方, 千万不要忘记当一个顶点扩展结束后, head++, 然后才能继续往下扩展
}
for (i=1; i<tail; i++) {
printf("%d\n", que[i]);
}
getchar();getchar();
return 0;
}
数据验证:
5 5
1 2
1 3
1 5
2 4
3 5
返回值:
1 2 3 5 4
参考
《啊哈!算法》 —— 第5章 图的遍历