SparkSQL是spark用来处理结构化的一个模块,它提供一个抽象的数据集DataFrame,并且是作为分布式SQL查询引擎的应用
注:本文所有操作是基于ambari工具,搭建好了 hdfs yarn hive spark mapReduce 等大数据常用的组件
一、进入spark命令窗口
输入命令 spark-shell

以上是各种报错的部分截图,原因是spark操文件时,用的是hdfs系统,使用hdfs系统必须hdfs账号来操作,
为了解决上述问题,切换用户到hdfs用户即可
退出重新进入
切换hdfs用户
su hdfs
重新进入spark-shell
spark-shell

现在完全正常了,
二、创建DataFrames
2.1、创建了一个数据集,实现了并行化
val seq= Seq(("1","xiaoming",15),("2","xiaohong",20),("3","xiaobi",10))
var rdd1 = sc.parallelize(seq)


2.2、将当前的rdd对象转换为DataFrame对象(数据信息和数据结构信息存储到DataFrame)
val df = rdd1.toDF("id","name","age")

三、查询数据操作
3.1、DSL 风格语法
df.select("name").show
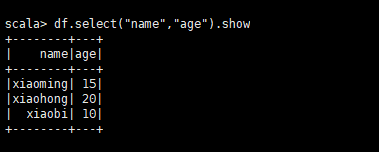
df.select("name","age").show
//条件过滤
df.select("name","age").filter("age >10").show
//参数必须是一个字符串,filter中的表达式也需要时一个字符串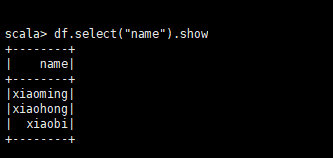

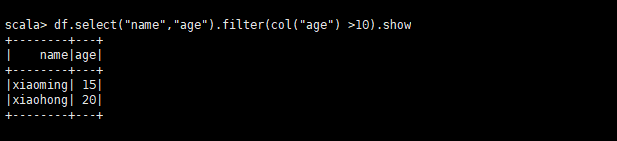
3.1.1、参数是类名col (“列名”)
df.select(“name”,“age”).filter(col(“age”) >10).show
3.1.2、分组统计个数
df.groupBy("age").count().show()

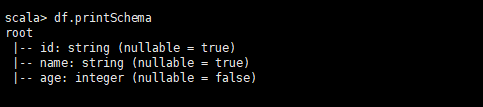
3.1.3、打印DataFrame结构信息
df.printSchema
3.2、SQL风格语法
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL查询,结果将作为一个DataFrame返回。
如果想使用SQL风格的语法,需要将DataFrame注册成表,注册方式如下
df.registerTempTable("t_person")
表示 将DataFrame成t_person表
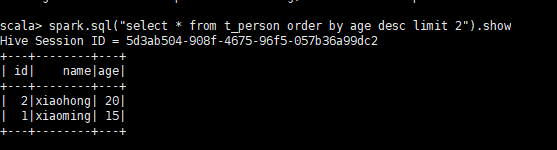
3.2.1 、查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2").show
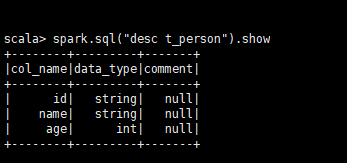
3.2.2、显示表的Schema信息
spark.sql("desc t_person").show
3.2.3 、查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 10 ").show

3.3、DataSet 风格
3.3.1. 、 什么是DataSet
DataSet是分布式的数据集合。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作
3.3.2 、 DataFrame、DataSet、RDD的区别
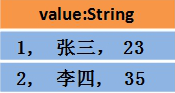
同样一组数据,分别形式如下
RDD中的长像:

DataFrame中的长像

Dataset中的长像

DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
(1)DataSet可以在编译时检查类型
(2)并且是面向对象的编程接口
相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,这会浪费大量的时间,这也是引入Dataset的一个重要原因。
3.3.3 DataFrame与DataSet的互转
DataFrame和DataSet可以相互转化。
(1)DataFrame转为 DataSet
df.as[ElementType]这样可以把DataFrame转化为DataSet。
(2)DataSet转为DataFrame
ds.toDF()这样可以把DataSet转化为DataFrame。
3.3.4. 创建DataSet
3.3.4.1 、通过spark.createDataset创建
val ds = spark.createDataset(1 to 10)

3.3.4.2、通toDS方法生成DataSet
定义一个类
case class Person(name:String,age:Long)

定义一个类的集合
val data = List(Person("zhangsan",20),Person("lisi",30))

转成DS
val ds = data.toDS

查看DS
ds.show
