分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
1.安装hive
如果想创建一个数据库用户,并且为数据库赋值权限,可以参考:http://blog.csdn.net/tototuzuoquan/article/details/52785504
2.将配置好的hive-site.xml、core-site.xml、hdfs-site.xml放入$SPARK_HOME/conf目录下
[root@hadoop1 conf]# cd /home/tuzq/software/hive/apache-hive-1.2.1-bin[root@hadoop1 conf]# cp hive-site.xml $SPARK_HOME/conf[root@hadoop1 spark-1.6.2-bin-hadoop2.6]# cd $HADOOP_HOME[root@hadoop1 hadoop]# cp core-site.xml $SPARK_HOME/conf[root@hadoop1 hadoop]# cp hdfs-site.xml $SPARK_HOME/conf同步spark集群中的conf中的配置[root@hadoop1 conf]# scp -r * root@hadoop2:$PWD[root@hadoop1 conf]# scp -r * root@hadoop3:$PWD[root@hadoop1 conf]# scp -r * root@hadoop4:$PWD[root@hadoop1 conf]# scp -r * root@hadoop5:$PWD
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
放入进去之后,注意重新启动Spark集群,关于集群启动和停止,可以参考:
http://blog.csdn.net/tototuzuoquan/article/details/74481570
- 1
修改spark的log4j打印输出的日志错误级别为Error。修改内容为:
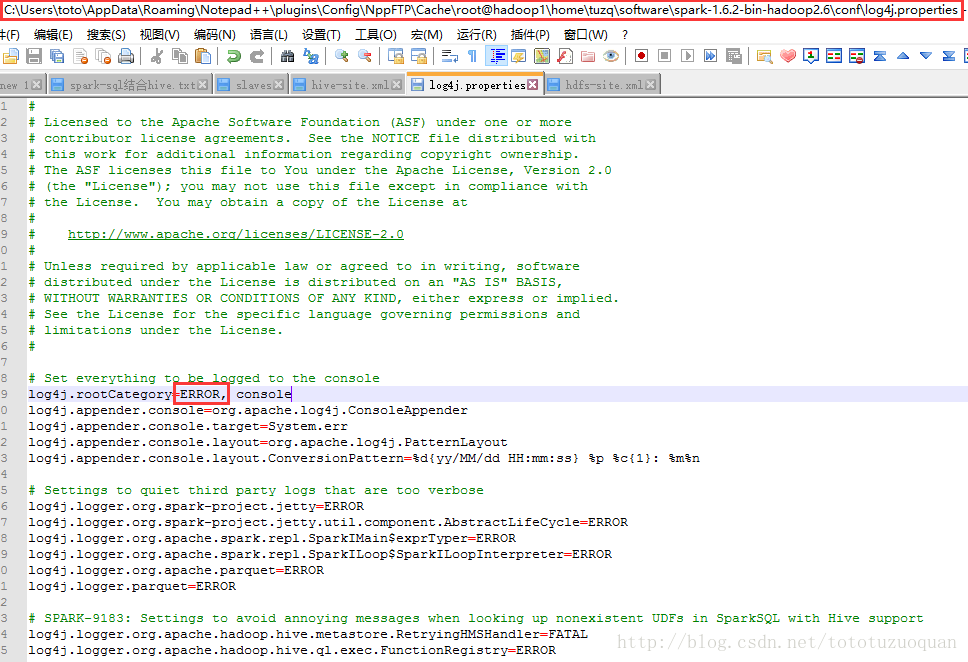
3.启动spark-shell时指定mysql连接驱动位置
bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 1g --total-executor-cores 2 --driver-class-path /home/tuzq/software/spark-1.6.2-bin-hadoop2.6/lib/mysql-connector-java-5.1.38.jar
- 1
如果启动的过程中报如下错:
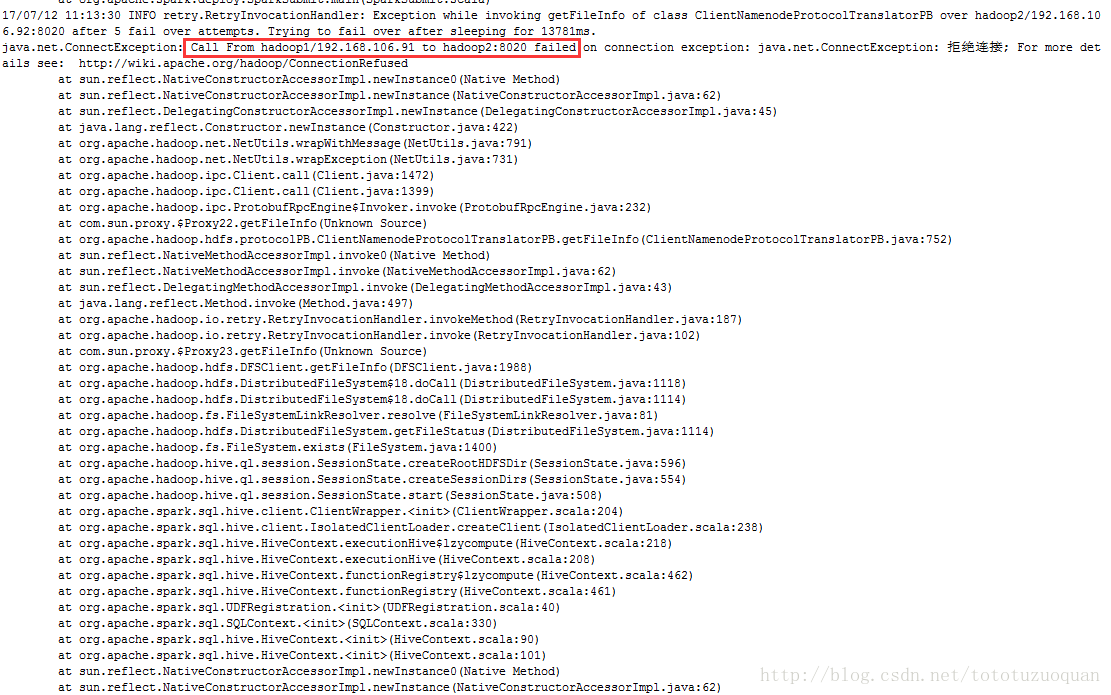
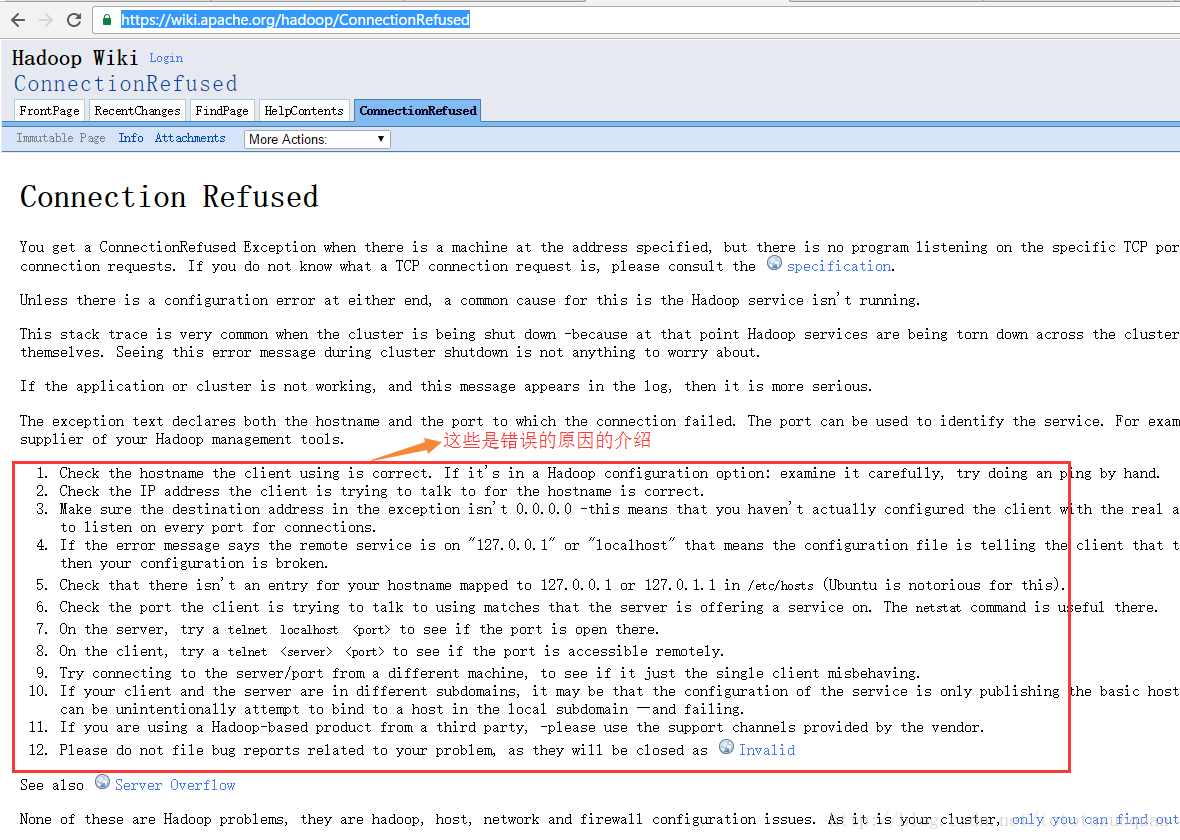
可以按照上面的红框下的url进行检查:
https://wiki.apache.org/hadoop/ConnectionRefused
4.使用sqlContext.sql调用HQL
在使用之前先要启动hive,创建person表:
hive> create table person(id bigint,name string,age int) row format delimited fields terminated by " " ;OKTime taken: 2.152 secondshive> show tables;OKfuncpersonwypTime taken: 0.269 seconds, Fetched: 3 row(s)hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查看hdfs中person的内容:
[root@hadoop3 ~]# hdfs dfs -cat /person.txt1 zhangsan 192 lisi 203 wangwu 284 zhaoliu 265 tianqi 246 chengnong 557 zhouxingchi 588 mayun 509 yangliying 3010 lilianjie 5111 zhanghuimei 3512 lian 5313 zhangyimou 54[root@hadoop3 ~]# hdfs dfs -cat hdfs://mycluster/person.txt1 zhangsan 192 lisi 203 wangwu 284 zhaoliu 265 tianqi 246 chengnong 557 zhouxingchi 588 mayun 509 yangliying 3010 lilianjie 5111 zhanghuimei 3512 lian 5313 zhangyimou 54
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
load数据到person表中:
hive> load data inpath '/person.txt' into table person;Loading data to table default.personTable default.person stats: [numFiles=1, totalSize=193]OKTime taken: 1.634 secondshive> select * from person;OK1 zhangsan 192 lisi 203 wangwu 284 zhaoliu 265 tianqi 246 chengnong 557 zhouxingchi 588 mayun 509 yangliying 3010 lilianjie 5111 zhanghuimei 3512 lian 5313 zhangyimou 54Time taken: 0.164 seconds, Fetched: 13 row(s)hive>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
如果是spark-2.1.1-bin-hadoop2.7,它没有sqlContext,所以要先执行:val sqlContext = new org.apache.spark.sql.SQLContext(sc)如果是spark-1.6.2-bin-hadoop2.6,不用执行:val sqlContext = new org.apache.spark.sql.SQLContext(sc)scala> sqlContext.sql("select * from person limit 2")+---+--------+---+| id| name|age|+---+--------+---+| 1|zhangsan| 19|| 2| lisi| 20|+---+--------+---+scala>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
或使用org.apache.spark.sql.hive.HiveContext (同样是在spark-sql这个shell命令下)
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContextscala> val hiveContext = new HiveContext(sc)Wed Jul 12 12:43:36 CST 2017 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.Wed Jul 12 12:43:36 CST 2017 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.hiveContext: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@6d9a46d7scala> hiveContext.sql("select * from person")res2: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]scala> hiveContext.sql("select * from person").show+---+-----------+---+| id| name|age|+---+-----------+---+| 1| zhangsan| 19|| 2| lisi| 20|| 3| wangwu| 28|| 4| zhaoliu| 26|| 5| tianqi| 24|| 6| chengnong| 55|| 7|zhouxingchi| 58|| 8| mayun| 50|| 9| yangliying| 30|| 10| lilianjie| 51|| 11|zhanghuimei| 35|| 12| lian| 53|| 13| zhangyimou| 54|+---+-----------+---+scala>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
bin/spark-sql \
–master spark://hadoop1:7077,hadoop2:7077 \
–executor-memory 1g \
–total-executor-cores 2 \
–driver-class-path /home/tuzq/software/spark-1.6.2-bin-hadoop2.6/lib/mysql-connector-java-5.1.38.jar
5、启动spark-shell时指定mysql连接驱动位置
bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 1g --total-executor-cores 2 --driver-class-path /home/tuzq/software/spark-1.6.2-bin-hadoop2.6/lib/mysql-connector-java-5.1.38.jar
- 1
5.1.使用sqlContext.sql调用HQL(这里是在spark-shell中执行的命令)
scala> sqlContext.sql("select * from person limit 2")res0: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]scala> sqlContext.sql("select * from person limit 2").show+---+--------+---+| id| name|age|+---+--------+---+| 1|zhangsan| 19|| 2| lisi| 20|+---+--------+---+scala>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
或使用org.apache.spark.sql.hive.HiveContext
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContextscala> val hiveContext = new HiveContext(sc)这里是日志,略去scala> hiveContext.sql("select * from person")res2: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]scala> hiveContext.sql("select * from person").show+---+-----------+---+| id| name|age|+---+-----------+---+| 1| zhangsan| 19|| 2| lisi| 20|| 3| wangwu| 28|| 4| zhaoliu| 26|| 5| tianqi| 24|| 6| chengnong| 55|| 7|zhouxingchi| 58|| 8| mayun| 50|| 9| yangliying| 30|| 10| lilianjie| 51|| 11|zhanghuimei| 35|| 12| lian| 53|| 13| zhangyimou| 54|+---+-----------+---+scala>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow
