系列文章目录
Java并发编程技术知识点梳理(第一篇)操作系统底层工作的整体认识
Java并发编程技术知识点梳理(第二篇)并发编程之JMM&volatile详解
Java并发编程技术知识点梳理(第三篇)CPU缓存一致性协议MESI
Java并发编程技术知识点梳理(第四篇)并发编程之synchronized详解
Java并发编程技术知识点梳理(第五篇)抽象队列同步器AQS应用Lock详解
Java并发编程技术知识点梳理(第六篇)并发编程之LockSupport的 park 方法及线程中断响应
Java并发编程技术知识点梳理(第七篇)抽象队列同步器AQS应用之阻塞队列BlockingQueue详解
Java并发编程技术知识点梳理(第八篇)并发编程之CountDownLatch&Semaphore原理与应用
Java并发编程技术知识点梳理(第九篇)并发编程之Atomic&Unsafe魔法类详解
Java并发编程技术知识点梳理(第十篇)Collections之HashMap分析
Java并发编程技术知识点梳理(第十一篇)并发编程之Executor线程池原理与源码解读
Java并发编程技术知识点梳理(第十二篇)并发编程之定时任务&定时线程池
HashMap
数据结构
数组+链表+(红黑树jdk>=8)
源码原理分析
重要成员变量
DEFAULT_INITIAL_CAPACITY = 1 << 4; Hash表默认初始容量
MAXIMUM_CAPACITY = 1 << 30; 最大Hash表容量
DEFAULT_LOAD_FACTOR = 0.75f;默认加载因子
TREEIFY_THRESHOLD = 8;链表转红黑树阈值
UNTREEIFY_THRESHOLD = 6;红黑树转链表阈值
MIN_TREEIFY_CAPACITY = 64;链表转红黑树时hash表最小容量阈值,达不到优先扩容。
内部的执行机制源码
public class Main {
public static void main(String[] args) {
Map<String,Person> personMap = new HashMap<>();
personMap.put("张三",new Person("张三",21));
personMap.put("李四",new Person("李四",19));
personMap.put("王五",new Person("王五",25));
personMap.put("赵六",new Person("赵六",24));
personMap.put("孙七",new Person("孙七",32));
personMap.put("周八",new Person("周八",17));
personMap.put("钱九",new Person("钱九",24));
personMap.put("吴十",new Person("吴十",23));
System.out.println("personMap.size():"+personMap.size());
}
}
package com.yg.edu.map.test;
/**
* @author 史凯强
* @date 2021/10/30 14:59
* @desc
**/
public class Person {
private String name;
private Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
构造函数如下:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
似乎简单,就是初始化了一个负载因子,负载因子默认为0.75f,这个负载因子后续会详说。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
又看到了传说中的数组,数组里原对象是Node,来看一下Node是什么鬼
transient Node<K,V>[] table;

其实很简单,一些属性,一个key,一个value,用来保存我们往Map里放入的数据,next用来标记Node节点的下一个元素。目前还没有任何代码用到Node,我们只能从成员变量入手了
transient int size;
transient int modCount;
这两个就不多说了吧,一个是逻辑长度,一个是修改次数,ArrayList,LinkedList也有这两个属性,老规矩,我们来画一画

HashMap我们就初始化好了,成员变量table数组默认为null,size默认为0,负载因子为0.75f,初始化完成,往里添加元素,来看一下put的源码
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
就一行代码,调用了putVal方法,其中key是传进来的“张三”这个字符串对象,value是“张三”这个Person对象,调用了一个方法hash(),再看一下
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
看到了熟悉的hashCode,我们在前面的文章里已经强调过很多次了,重写equals方法的时候,一定要重写hashCode方法,因为key是基于hashCode来处理的。继续看putVal方法

resize方法比较复杂,这儿就不完全贴出来了,当放入第一个元素时,会触发resize方法的以下关键代码
newCap = DEFAULT_INITIAL_CAPACITY;
再看这个DEFAULT_INITIAL_CAPACITY是什么东东
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
又是传说中的移位运算符,1 << 4 其实就是相当于16。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
恩,这句是关键,当我们放入第一个元素时,如果底层数组还是null,系统会初始化一个长度为16的Node数组,像极了ArrayList的初始化。
return newTab;
最后返回new出来的数组,继续画图,由于篇幅有限,下图中省略了部分数组内容,注意,虽然数组长度为16,但逻辑长度size依然是0

继续执行下图中putVal方法里的红框内容

if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
这段代码初学者可能看起来比较费劲,我们重写一下以便初学者能更好的理解,这两段代码等同,下面是重写后的代码,清晰了很多
i = (n - 1) & hash;//hash是传过来的,其中n是底层数组的长度,用&运算符计算出i的值
p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){
//如果这个元素为null,用key,value构造一个Node对象放入数组下标为i的位置
tab[i] = newNode(hash, key, value, null);
}
这个hash值是字符串“张三”这个对象的hashCode方法与hashMap提供hash()方法共同计算出来的结果,其中n是数组的长度,目前数组长度为16,不管这个hash的值是多少,经过(n - 1) & hash计算出来的i 的值一定在n-1之间。刚好是底层数组的合法下标,用i这个下标值去底层数组里去取值,如果为null,创建一个Node放到数组下标为i的位置。这里的“张三”计算出来的i的值为2,继续画图

继续添加元素“李四”,“王五”,“赵六”,一切正常,key:“李四”经过(n - 1) & hash算出来在数组下标位置为1,“王五”为7,“赵六”为9,添加完成后如下图

上图更趋近于堆内存中的样子,但看起来比较复杂,我们简化一下

上图是简化后的堆内存图。继续往里添加“孙七”,通过(n - 1) & hash计算“孙七”这个key时计算出来的下标值是1,而数组下标1这个位置目前已经被“李四”给占了,产生了冲突。相信大家在看本文的过程中也有这样的疑惑,万一计算出来的下标值i重了怎么办?我们来看一看
HashMap是怎么解决冲突的。

上图中红框里就是冲突的处理,这一句是关键
p.next = newNode(hash, key, value, null);
也就是说new一个新的Node对象并把当前Node的next引用指向该对象,也就是说原来该位置上只有一个元素对象,现在转成了单向链表,继续画图

继续添加其它元素,添加完成后如下


大框里的内容是链表的体现,小框里的内容是单元素的体现。
红框中还有两行比较重要的代码
if (binCount >= TREEIFY_THRESHOLD - 1) //当binCount>=TREEIFY_THRESHOLD-1
treeifyBin(tab, hash);//把链表转化为红黑树
再看看TREEIFY_THRESHOLD的值
static final int TREEIFY_THRESHOLD = 8;
当**链表长度到8时,将链表转化为红黑树来处理,**由于树相关的内容本专栏还未讲解,红黑树的内容这里就不深入了。树在内存中的样子我们还是画个图简单的了解一下

在JDK1.7及以前的版本中,HashMap里是没有红黑树的实现的,在JDK1.8中加入了红黑树是为了防止哈希表碰撞攻击,当链表链长度为8时,及时转成红黑树,提高map的效率。在面试过程中,能说出这一点,面试官会对你加分不少。
HashMap的最底层是数组来实现的,数组里的元素可能为null,也有可能是单个对象,还有可能是单向链表或是红黑树。
文中的resize在底层数组为null的时候会初始化一个数组,不为null的情况下会去扩容底层数组,并会重排底层数组里的元素。
假设执行完红框里的代码,personMap里放入了8个元素,放置完成后在堆内存表现如下图

如果忽略底层实现细节,是这样的

在Map中,一个key,对应了一个value,如果key的值已经存在,Map会直接替换value的内容,来看一下源码中是怎么实现的,来看以下代码
Person oldPerson1 = personMap.put("张三",new Person("新张三",21));
Person oldPerson2 = personMap.put("孙七",new Person("新孙七",32));
System.out.println("oldPerson1.getName():"+oldPerson1.getName());
System.out.println("oldPerson2.getName():"+oldPerson2.getName());
System.out.println("personMap.size():"+personMap.size());
for(Map.Entry<String,Person> map:personMap.entrySet()){
System.out.println(map.getKey()+"=========="+map.getValue());
}
new了一个Person“新张三”,注意,key依然是张三,看一下源码

放入“新张三”时,会执行以上代码1、2、5
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
上面这段代码在上一篇文章已经改写过了,改写后的代码如下:
i = (n - 1) & hash;//hash是传过来的,其中n是底层数组的长度,用&运算符计算出i的值
p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){
//这儿P不为null,所以下面这行代码不会执行。
tab[i] = newNode(hash, key, value, null);//这行代码不会执行
}
很简单,直接在底层数组里取值赋值给p,由于p不为null,执行else里的逻辑
Node<K,V> e; K k;
if (p.hash == hash && //如果hash值相等,key也相等,或者equals相等,赋值给e
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//赋值给e
又看到了熟悉的equals方法,这里我们hash值相等,key的值也相等,条件成立,把值赋值给e。(如果key的值不相等,就比较equals方法,也就是说,就算key是一个新new出来的对象,只要满足equals,也视为key相同)
if (e != null) {
// existing mapping for key
V oldValue = e.value;//定义一个变量来存旧值
if (!onlyIfAbsent || oldValue == null)
e.value = value;//把value的值赋值为新的值
afterNodeAccess(e);
return oldValue;//返回的值
}
这段代码就比较简单了,用新的value替换旧value并返回旧的value。画一下图

再new一个Person“新孙七”并put到personMap中,注意,key依然是“孙七”,会执行图17-2里的1、2、3、4、5,由于2、3不满足条件,实际执行的是1、4、5,1这一步已经说过了,重点说一下4这一步
for (int binCount = 0; ; ++binCount) {
//循环
if ((e = p.next) == null) {
//如果循环到最后也没找到,把元素放到最后
p.next = newNode(hash, key, value, null);//把元素放到最后
if (binCount >= TREEIFY_THRESHOLD - 1) //如果长度超>=8,转换成红黑树
treeifyBin(tab, hash);//转换成红黑树
break;
}
if (e.hash == hash && //这段代码和第2步一样
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;//如果hash值相等,key也相等或者equals相等,赋值给e
}
}
}
其实就是循环链表的节点,直到找到"孙七"这个key,然后执行图17-2里的第5步,如果找不到,就添加到最后,这里我们key是“孙七”,在链表中找到元素替换value即可,再画一下图

最后来看看放到树里的方法putTreeVal,由于树的内容我们还没涉及到,下面只标注出了关键代码

和链表类似,循环(遍历)树的节点,如果找到节点,返回节点,执行图17-2里的第5步更新value。如果循环完整颗数都找不到相应的key,添加新节点。
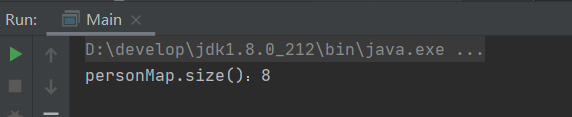
最后我们看一下本文初那段示例代码的执行结果:

总结
在hashMap中放入(put)元素,有以下重要步骤:
- 1、计算key的hash值,算出元素在底层数组中的下标位置。
- 2、通过下标位置定位到底层数组里的元素(也有可能是链表也有可能是树)。
- 3、取到元素,判断放入元素的key是否==或equals当前位置的key,成立则替换value值,返回旧值。
- 4、如果是树,循环树中的节点,判断放入元素的key是否==或equals节点的key,成立则替换树里的value,并返回旧值,不成立就添加到树里。
- 5、否则就顺着元素的链表结构循环节点,判断放入元素的key是否==或equals节点的key,成立则替换链表里value,并返回旧值,找不到就添加到链表的最后。
精简一下,判断放入HashMap中的元素要不要替换当前节点的元素,key满足以下两个条件即可替换:
1、hash值相等。
2、==或equals的结果为true。
由于hash算法依赖于对象本身的hashCode方法,所以对于HashMap里的元素来说,hashCode方法与equals方法非常的重要,这也是强调重写对象的equals方法一定要重写hashCode方法的原因,不重写的话,放到HashMap中可能会得不到你想要的结果