1. 摘要
使用分治策略来处理SR-iTM问题;将其分成三个任务相关的子网络:图像重建子网络(image reconstruction subnet),细节恢复子网络 (detail restoration subnet),局部对比度增强子网络(local contrast enhancement subnet),从而学习到一组像素级的逐像素的1维可分离卷积用于复原细节,像素级的2维局部卷积核来用于对比度增强。此外,作者提出一种可增强细节信息的GAN loss,可同时增强细节恢复和对比度复原。
2. 介绍
一方面,作者认为SR-ITM这个问题需要同时考虑两个问题:如何在上采样的结果中恢复细节;由于比特位数增加如何增强局部的对比度信息(enhance local contrast)
GAN网络可用于生成图片,但作者认为GAN网络会导致主观的图像质量提高的同时降低客观的评价指标(PSNR,SSIM),直接使用传统的GAN网络的结构会导致缺少相应的细节和局部的对比度,因此本文中使用了新的detail loss,使得生成的图片与GT的细节更相符合,并且使用一种feature-matching loss,用来减轻在训练过程中客观评价的drop。
本文主要有以下几个贡献:
- 首先提出了一个用于联合SR-ITM的GAN框架,称为JSI-GAN,具有新颖的细节损失和特征匹配损失,可以恢复现实的细节并进行稳定的训练。”
- JSI-GAN的设计旨在具有特定于任务的子网(DR / IR /
LCE子网络),这些子网具有像素级的1D可分离滤波器以改善局部细节,并具有2D局部滤波器以增强局部对比度,方法是考虑给定放大系数的局部上采样操作。 - DR子网专注于高频分量,以精心还原HR HDR输出的细节,而LCE子网通过专注于LRSDR输入的基础层分量,有效地恢复了局部对比度。
3. 网络结构
3.1 生成器

3.1.1 细节恢复子网络(detail restoration subnet)
是上采样滤波器, 输入是细节层 X d \large X_d Xd 包含了 LR SDR 输入图片的高频分量, X d = X ⊘ X b \large X_d = X \oslash X_b Xd=X⊘Xb , 其中 X b \large X_b Xb是X应用引导滤波器的输出, ⊘ \large \oslash ⊘表示按元素相除. 在我们的实现中,向分母添加一个较小的值 1 0 − 15 \large 10^{-15} 10−15,以防止在 X b \large X_b Xb接近零的情况下 X d \large X_d Xd发散. X d \large X_d Xd用于生成水平和垂直一维可分离滤波器.
残差模块(Res-Block) RB定义:
R B ( x ) = ( C o n v ∘ R L ∘ C o v e ∘ R L ) ( x ) + x \large RB(x) = (Conv \circ RL \circ Cove \circ RL)(x) +x RB(x)=(Conv∘RL∘Cove∘RL)(x)+x, 其中 x 是 ResBlock 的输入, Conv 是卷积层, RL是 ReLU激活函数.
水平1D滤波器 f 1 D h = ( C o n v ∘ R L ∘ R B 4 ∘ C o n v ) ( X d ) \large f_{1D}^h = (Conv \circ RL \circ RB^4 \circ Conv)(X_d) f1Dh=(Conv∘RL∘RB4∘Conv)(Xd), 其中 R B n \large RB^n RBn表示 n个 ResBlock 串行级联. 垂直 1D滤波器 f 1 D v \large f_{1D}^v f1Dv用同样的方式获得. 在生成1D水平和垂直滤波器时,除最后一个卷积层外的所有层都共享.
最后两个卷积层中的每一个都由41×scale×scale 输出通道组成,其中41是一维可分离kernel的长度,每个通道应用于其对应的网格位置,scale × scale 考虑了对于上采用因子scale 的像素混洗重组操作. 动态可分离上采样操作 ( ∗ ˙ s \large \dot{*}_s ∗˙s) 表示使用两个1D可分离滤波器产生空间上采样输出.
DR subnet 输出为: D = X d ∗ ˙ s ( f 1 D v , f 1 D h ) \large D = X_d \quad \dot{*}_s \quad (f^v_{1D}, f^h_{1D}) D=Xd∗˙s(f1Dv,f1Dh)
生成的一维kernel是位置特定的,也是细节特定的,因为针对不同的细节层生成了不同的kernel,这与训练后固定的卷积滤波器不同, 在实现中, 首先通过每个比例通道的局部过滤将 f 1 D v \large f^v_{1D} f1Dv应用于细节层, 然后在其输出应用 f 1 D h \large f^h_{1D} f1Dh, 最后,将像素混洗应用到具有scale * scale 个通道的最终滤波输出上,以进行空间放大。
3.1.2 局部对比度增强网络(Local Contrast Enhancement(LCE) Subnet)
LCE子网在每个像素网格位置生成一个9×9 2D局部滤波器, 同样是上采样滤波器, 在最后一层具有9×9×scale×scale输出通道
f 2 D = ( C o n v ∘ R L ∘ R B 4 ∘ C o n v ) ( X b ) \large f_{2D} = (Conv \circ RL \circ RB^4 \circ Conv)(X_b) f2D=(Conv∘RL∘RB4∘Conv)(Xb)
LCE 网络输出 C l = 2 × s i g m o i d ( X b ∗ ˙ f 2 D ) \large C_l = 2 \times sigmoid(X_b \dot{ \ast} f_{2D}) Cl=2×sigmoid(Xb∗˙f2D)
由于将Cl视为LCE掩码,并且将其逐个元素地与IR和DR子网的两个输出之和相乘,因此JSInet与singmoid函数更好的融合,没有它,初始预测输出(与Cl相乘后)的像素值太小,需要更长的训练时间才能使JSInet的最终HR HDR输出达到合适的像素范围。
3.1.3 图像重建网络Image Reconstruction (IR)Subnet
输入LR SDR 图像X, 产生中间特征 i I R = ( R B ∘ C o n v ) ( X ) \large i_{IR} = (RB \circ Conv)(X) iIR=(RB∘Conv)(X)
IR 网络的输出 I = ( C o n v ∘ P S ∘ R L ∘ C o n v ∘ R L ∘ R B 3 ) ( [ i I R , i D R ] ) \large I= (Conv \circ PS \circ RL \circ Conv \circ RL \circ RB^3)([i_{IR}, i_{DR}]) I=(Conv∘PS∘RL∘Conv∘RL∘RB3)([iIR,iDR]), PS 是 pixel-shuffle 操作, [x, y] 表示在通道方向x与y 进行拼接.
最终HR HDR预测值 P = ( I + D ) × C l \large P = (I+ D) \times C_l P=(I+D)×Cl
3.2 判别器

输入x (P[生成器预测的结果] 或 Y[ground truth]), 判别器的输出 D f ( x ) = ( B N ∘ F C 1 ∘ B N ∘ F C 512 ∘ L R L ∘ B N ∘ 4 C o n v 2 ∘ D B 4 ∘ L R L ∘ 3 C o n v 1 ) ( x ) \large D^f (x) = (BN \circ FC1 \circ BN \circ FC512 \circ LRL \circ BN \circ 4Conv2 \circ DB^4 \circ LRL \circ 3Conv1)(x) Df(x)=(BN∘FC1∘BN∘FC512∘LRL∘BN∘4Conv2∘DB4∘LRL∘3Conv1)(x)
其中, BN表示 batch normalization, LRL 表示 Leaky ReLU激活slope size 为0.2, FCk 表示全连接层有k个输出通道. K Conv s表示k*k 大小的 kernel size , stride 为s
DB(DisBlock) D B ( x ) = ( L R L ∘ B N ∘ 3 C o n v 1 ∘ L R L ∘ B N ∘ 4 C o n v 2 ) ( x ) \large DB(x) = (LRL \circ BN \circ 3Conv1 \circ LRL \circ BN \circ 4Conv2)(x) DB(x)=(LRL∘BN∘3Conv1∘LRL∘BN∘4Conv2)(x)
对抗损失(Adversarial loss):
L a d v D = E Y [ m a x ( 0 , Q ~ Y , P ( − ) ] + E P [ m a x ( 0 , Q ~ P , Y ( + ) ) ] \large L^D_{adv} = \underset{Y}{\mathbb{E}}[ max(0, \widetilde{Q}_{Y,P}^{(-)} ] + \underset{P}{\mathbb{E}}[ max(0, \widetilde{Q}^{(+)}_{P,Y}) ] LadvD=YE[max(0,Q Y,P(−)]+PE[max(0,Q P,Y(+))]
L a d v G = E P [ m a x ( 0 , Q ~ P , Y ( − ) ) ] + E Y [ m a x ( 0 , Q ~ Y , P ( + ) ) ] \large L^G_{adv} = \underset{P}{\mathbb{E}}[max(0, \widetilde{Q}^{(-)}_{P,Y})] + \underset{Y}{\mathbb{E}}[ max(0, \widetilde{Q}^{(+)}_{Y,P}) ] LadvG=PE[max(0,Q P,Y(−))]+YE[max(0,Q Y,P(+))]
其中, Q ~ P , Y ( ± ) = 1 ± D ~ P , Y \large \widetilde{Q}^{(\pm )}_{P,Y} = 1 \pm \widetilde{D}_{P,Y} Q P,Y(±)=1±D P,Y, D ~ P , Y = D f ( P ) − E Y D f ( Y ) \quad \widetilde{D}_{P,Y} = D_f(P) - \mathbb{E}_YD_f(Y) D P,Y=Df(P)−EYDf(Y)
feature-matching loss:
L f m = ∑ i = 1 4 ∣ ∣ f m i ( Y ) − f m i ( P ) ∣ ∣ 2 \large L_{fm} = \sum^4_{i=1}|| fm_i(Y) - fm_i(P) ||_2 Lfm=∑i=14∣∣fmi(Y)−fmi(P)∣∣2
Detail GAN loss: L a d v d \large L_{adv}^d Ladvd为了增强训练稳定性和提供局部对比度和细节产生更好的结果.
d 上标表示 细节层. 对于 L a d v d \large L_{adv}^d Ladvd 我们采用不同于第一鉴别器(D1)的第二鉴别器(D2),两者的结构相同,但D2取两个输入Pd和Yd,由等式(1)计算得出 [ P d = P ⊘ P b ] [\large P_d = P \oslash P_b] [Pd=P⊘Pb]。
total loss:
L D 1 = L a d v D 1 , L D 2 = λ d ⋅ L a d v d , D 2 \large L_{D_1} = L_{adv}^{D_1}, \quad L_{D_2} = \lambda_d \cdot L_{adv}^{d, D_2} LD1=LadvD1,LD2=λd⋅Ladvd,D2
L G = λ r e c ⋅ ∣ ∣ Y − P ∣ ∣ 2 + λ a d v ⋅ ( L a d v G + λ d ⋅ L a d v d , G ) + λ f m ⋅ ( L f m + λ d ⋅ L f m d ) \large L_G = \lambda_{rec} \cdot || Y-P ||_2 + \lambda_{adv} \cdot (L_{adv}^G + \lambda_d \cdot L_{adv}^{d,G}) + \lambda_{fm} \cdot (L_{fm} + \lambda_d \cdot L_{fm}^d) LG=λrec⋅∣∣Y−P∣∣2+λadv⋅(LadvG+λd⋅Ladvd,G)+λfm⋅(Lfm+λd⋅Lfmd)
上标d表示细节层成分(Pd,Yd)的损失
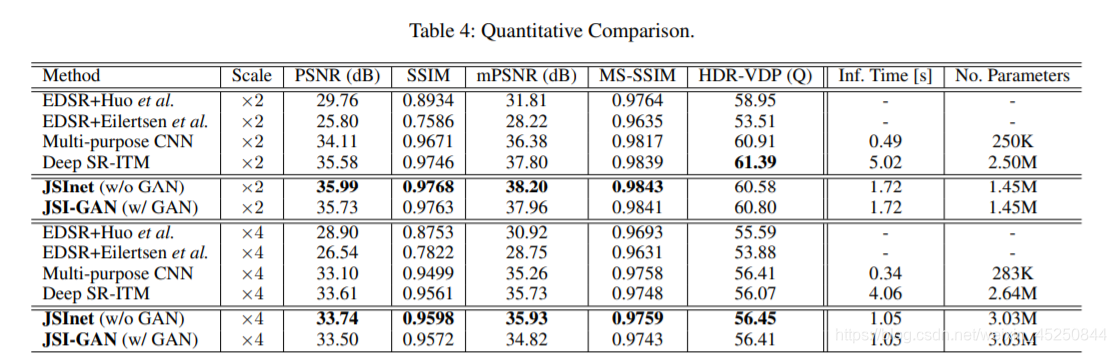
4. 实验