挖掘频繁模式、关联和相关性:基本概念和方法以及aprori算法MATLAB实现
概念
频繁模式(frequent pattern):
是频繁地出现在数据集中的模式(如项集、子序列或子结构)。
对于挖掘数据之间的关联、相关性和许多其他有趣的联系,发现这种频繁模式起着至关重要的作用。
关联规则(association rule):
A = > B A=>B A=>B
其中A和B 表示的是两个互斥事件,A 称为前因(antecedent),B 称为后果(consequent),上述关联规则表示A 会导致B 。
关联规则的强度可以用它的**支持度(support)和置信度(confidence)**表示
相对支持度: s u p p o r t ( A = > B ) = P ( A U B ) support(A=>B) = P(A U B) support(A=>B)=P(AUB)置信度: c o n f i d e n c e ( A = > B ) = P ( B ∣ A ) confidence(A=>B) = P(B|A) confidence(A=>B)=P(B∣A)
同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称为强规则。
项集的出现频度是包含项集的事务数,简称为项集的频度、支持度计数或计数
支持度计数: 已知项集的支持度计数,则规则A=>B这里写图片描述的支持度和置信度很容易从所有事务计数、项集A和项集AUB这里写图片描述的支持度计数推出

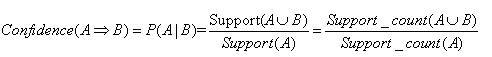
关联规则挖掘是一个两步的过程
(1)找出所有的频繁项集: 根据定义,这些项集的每一个频繁出现次数至少与预定义的最小支持计数(min_sup)一样。
(2)由频繁项集产生的强关联规则: 根据定义,这些规则必须满足最小支持度与最小置信度。
常用关联规则算法
| 算法名称 | 算法描述 |
|---|---|
| Apriori | 关联规则最常用也是最经典的挖掘频繁项集的算法,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集 |
| FP-Tree | 针对Apriori算法固有的多次扫描事务数据集的缺陷,提出不产生候选频繁项集的方法。Apriori和FP-Tree都是寻找频繁项集的算法 |
| Eclat | Eclat算法是一种深度优先算法,采用垂直数据表示形式,在概念格理论的基础上利用基于前缀的等价关系将搜索空间划分为较小的子空间 |
| 灰色关联算法 | 分析和确定各因素之间的影响程度或是若干个子因素(子序列)对主因素(母序列)的贡献度而进行的一种分析方法 |
实现
Apriori算法MATLAB实现——使用候选产生频繁项集
Apriori算法的主要思想是找出存在于事务数据集中最大的频繁项集,利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
数据:
I1,I2,I5
I2,I4
I2,I3
I1,I2,I4
I1,I3
I2,I3
I1,I3
I1,I2,I3,I5
I1,I2,I3
主函数中:首先先设置编码规则,例如如上的数据集中,共有a,b,c,d,e五种数据进行关联,然后根据设置好的编码规则转换原始数据
clc; clear;
%% 设置编码规则
inputfile = 'data.txt';
splitter = ',';
code = {}; % 记录元素种类
fid = fopen(inputfile);
tline = fgetl(fid); % fgetl从已经打开的文件中读取一行,并且丢掉末尾的换行符。
lines = 0;
while ischar(tline)
lines = lines+1;
tline = deblank(tline); % 删除尾随空白和空字符
% regexp用于对字符串进行查找,大小写敏感; 根据splitter进行字符串分割('split')
tline = regexp(tline, splitter, 'split');
code = [code tline];
code = unique(code); % 去除重复记录
tline = fgetl(fid);
end
disp('规则:');
disp(code);
fclose(fid);
%% 根据编码规则转换原始数据
itemsnum= length(code);
transactions = zeros(lines, itemsnum);
% 打开文件再读取第一行
fid= fopen(inputfile);
tline = fgetl(fid);
lines = 0;
while ischar(tline)
lines = lines+1;
tline = deblank(tline);
tline = regexp(tline, splitter, 'split');
[~,icode,~] = intersect(code,tline);% 寻找下标
transactions(lines,icode')=1; % icode'矩阵转置
tline = fgetl(fid);
end
fclose(fid);
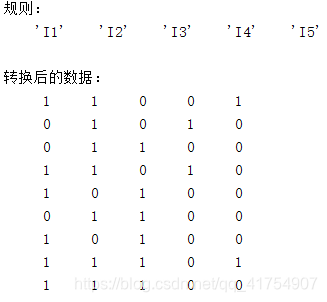
disp('转换后的数据:');
disp(transactions);
%%
minSup = 2; % 最小支持度
minCon = 0.5; % 最小置信度
L = apriori(transactions,minSup); % 含有最小支持度的矩阵
% C = sumConfidence(L, minCon); % 计算最小置信度
初始化init.m:
function [L A]=init(D,min_sup) %D表现数据集 min_sup 最小支持度
[m n]=size(D);
A=eye(n,n); % 单位矩阵
B=(sum(D))'; % 求每一列的和,并将其转置
i=1;
while(i<=n)
if B(i)<min_sup
B(i)=[];
A(i,:)=[];
m=m-1;
else
i=i+1;
end
end
L=[A B];
end
规则函数apriori.m:
function [L]=apriori(D,min_sup)
[L A]=init(D,min_sup);% 产生频繁1项集
disp('频繁1项集L(最后一列为支持度):');
disp(L);
disp('频繁1项集');
disp(A);
k=1;
% disp('频繁2项集的组合:');
C=apriori_gen(A,k); %发生2项的集合
% size(C,1)
while ~(size(C,1)==0)
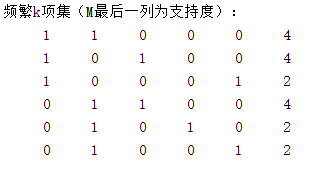
disp('频繁k项集(M最后一列为支持度):');
[M C]=get_k_itemset(D,C,min_sup);%发生k-频仍项集 M是带支持度 C不带
disp(M);
if ~(size(M,1)==0)
L=[L;M];
end
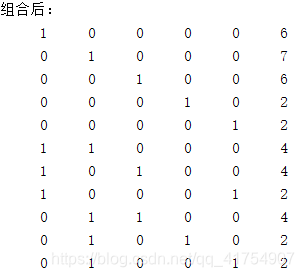
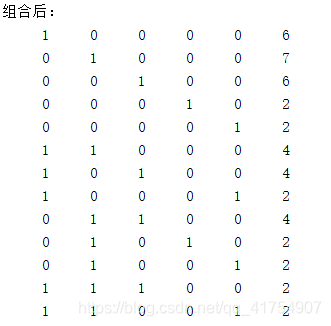
disp('组合后:');
disp(L);
k=k+1;
C=apriori_gen(C,k);%发生组合及剪枝后的候选集
disp('剪枝后:');
disp(C);
end
end
apriori_gen.m
function [C]=apriori_gen(A,k)%发生Ck(实现组内连接及剪枝 )
%A表现第k-1次的频仍项集 k表现第k-频仍项集
[m n]=size(A);
C=zeros(0,n);
%组内连接
for i=1:1:m
for j=i+1:1:m
flag=1;
for t=1:1:k-1
if ~(A(i,t)==A(j,t))
flag=0;
break;
end
end
if flag==0
break;
end
c=A(i,:)|A(j,:);
flag=isExit(c,A); %剪枝
if(flag==1)
C=[C;c];
end
end
end
end
get_k_itemset.m
function [L C]=get_k_itemset(D,C,min_sup)%D为数据集 C为第K次剪枝后的候选集 取得第k次的频仍项集
m=size(C,1);
M=zeros(m,1);
t=size(D,1);
i=1;
while i<=m
C(i,:);
H=ones(t,1);
ind=find(C(i,:)==1);
n=size(ind,2);
for j=1:1:n
D(:,ind(j));
H=H&D(:,ind(j));
end
x=sum(H');
if x<min_sup
C(i,:)=[];
M(i)=[];
m=m-1;
else
M(i)=x;
i=i+1;
end
end
L=[C M];
end
isExit.m
function flag=isExit(c,A)%判断c串的子串在A中是否存在
[m n]=size(A);
b=c;
for i=1:1:n
c=b;
if c(i)==0
continue
end
c(i)=0;
flag=0;
for j=1:1:m
A(j,:);
a=sum(xor(c,A(j,:)));
if a==0
flag=1;
break;
end
end
if flag==0
return
end
end
end