RDD介绍
因为RDD的实现原理和IO的实现原理差不多,我们先来说一下IO的实现原理:
其实真正进行读取数据的还是FileInputStream
IO实现原理图解:

RDD的工作流程:
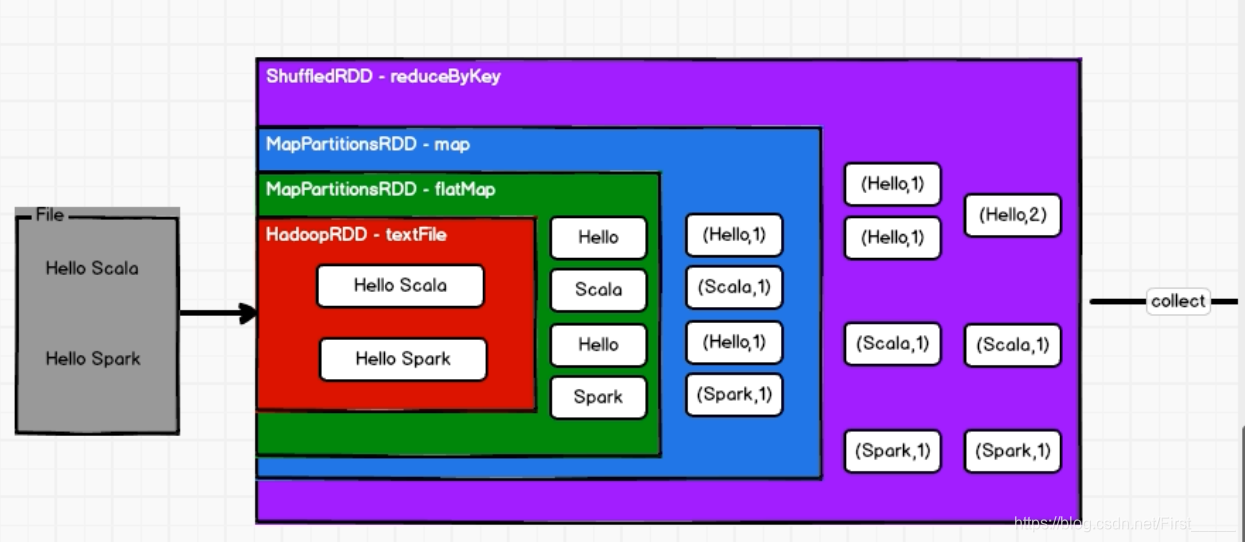
- RDD不会存储数据,但是可以存储依赖关系和血缘关系;
- RDD也有装饰者模式;
- RDD只有调用collect方法,才会真正执行业务逻辑代码,封装操作都是对RDD的功能扩展
分区和并行度:
概念:
分区 & 并行的概念: 分区和并行度是可以不一样的, 当有2个分区和1个executor的时候,就还不是并行,只能并发执行
并行度执行解析:
对数据进行分区, 然后每个分区内必须一个一个执行,多个分区可以并行执行,做到执行区内有序,区外无序
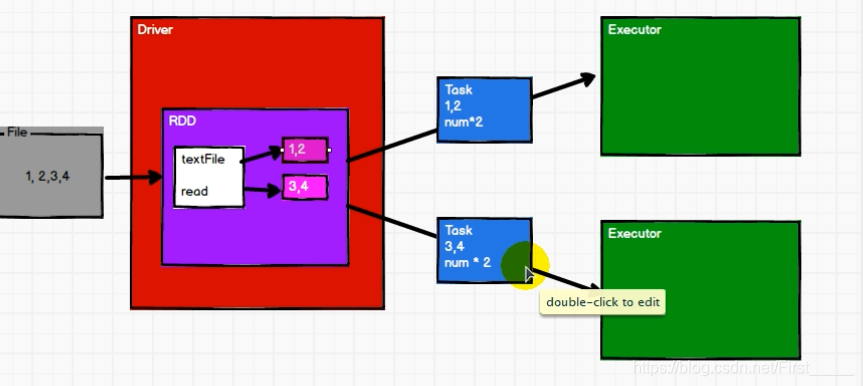
例: 对数据 List(1,2,3,4), 两个分区
计算流程:
- 先进行分配,
0号分区 => 1 ,2
1号分区 => 3,4 - 如果再执行两次map的话, 就会先将每个分区的第一个数据的全部计算完成之后,才会进行执行第二个, 做到区内数据执行有序
RDD的特点:
介绍:RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。
➢ 弹性
⚫ 存储的弹性:内存与磁盘的自动切换(效率高);
⚫ 容错的弹性:数据丢失可以自动恢复;
⚫ 计算的弹性:计算出错重试机制;
⚫ 分片的弹性:可根据需要重新分片(其实就是分区)。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据(数据计算完成之后,就进行销毁了)
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
算子介绍:
- 对象所执行的方法,都是在一个节点中执行的
- RDD的方法内部计算逻辑代码,都是发送到executor上来执行的
- 为了区分不同的效果,将RDD的方法称为算子
RDD依赖(血缘)关系介绍:
概念介绍:
- 血缘关系: 就是我们的RDD的整个之间的依赖关系,就叫血缘关系,而maven中叫间接依赖
- 一个上游的RDD的partition最多只被一个下游的partition使用,叫做OneToOne(窄依赖)
- 一个上游的RDD的partition被多个下游的partition使用,叫做shuffle(宽依赖)
toDebugString(): 获取RDD的血缘关系dependencies():获取依赖关系

任务和阶段的划分:
- 阶段的划分(stage): 每进行一次shuffle都要增加一个阶段,最后还有创建一个resultStage阶段,所以,
阶段的数量= shuffle的次数+1 - 任务的划分(task):
任务的数量=每个stage最后的分区数量
数据重复使用
-
原因: 因为RDD不能存储数据,所以不能进行重复使用
-
如果要想达到重复使用的目的,就在想到重复使用的RDD地方,进行数据持久化(内存中,磁盘上)
-
不一定非要重复时,才进行持久化, 如果进行了持久化,当数据发生错误时,就不会进行从头读取,浪费时间资源,提高效率
-
保存到磁盘的时候,是临时文件,当程序执行完是会删除的, 所以并不需要填写路径
-
也可以使用检查点checkpoint的方式,进行保存数据到磁盘
图解:

具体操作:
- 调用
cache()或者persist()方法进行持久化 cache()方法默认是保存到内存中, 如果要更改保存级别, 可以使用 persist()方法,进行更改checkpoint()检查点,是需要填写路径的(默认当前路径),保存到磁盘当中,当程序执行完,不会进行删除,一般情况下,保存到分布式文件系统当中(hdfs)

三者的效率对比:

分区源码实现
def main(args: Array[String]): Unit = {
//准备环境
val conf = new SparkConf().setAppName("RDD_Partition").setMaster("local[*]")
conf.set("spark.default.parallelism","3")
val sc = new SparkContext(conf)
/**
*
*/
//指定并行度 : 第一个参数:数据 第二个参数: 分区的数量, 默认为当前运行环境的机器的最大核数,也可以通过下面配置参数进行配置
// defaultParallelism: scheduler.conf.getInt("spark.default.parallelism", totalCores)
val rdd = sc.makeRDD(List(1, 2, 3, 4,5))
rdd.saveAsTextFile("output")
//关闭资源
sc.stop()
}
数据进行分区的分配规则(源码):
内存:
//调用positions方法
val array = seq.toArray // To prevent O(n^2) operations for List etc
positions(array.length, numSlices).map {
case (start, end) =>
array.slice(start, end).toSeq
}.toSeq
// 主要实现逻辑代码,每一个区的数据范围分配
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map {
i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
/**
*大概逻辑: 如果数据量为5个, 分区的个数为2个
data.length =5
num =2 分区的个数
分区号:0 -> [0,2)
分区号:1 -> [2,5)
*/
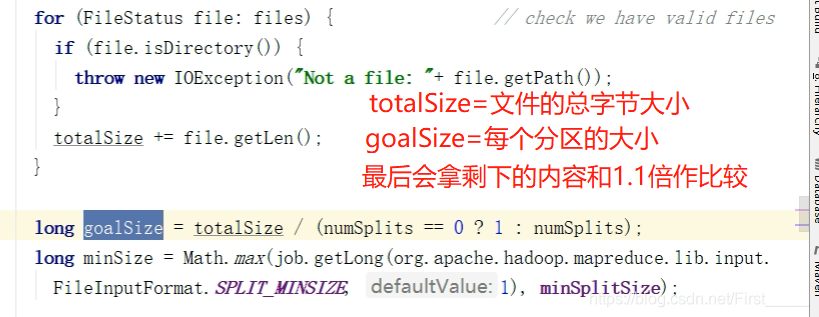
文件:
使用的还是hadoop的读取流程分配, 可以指定最小分区
分区计算公式: 数据量字节数量/最小分区 =数据量
- 如果这个数据量> 每个分区的大小的1.1倍的话,会重新再增加一个分区
- 如果<= 1.1倍的话,则会把剩下的数据量,和最后一个分区进行聚合
源码:
分区的数量:
math.min(defaultParallelism, 2) //默认最小分区是2
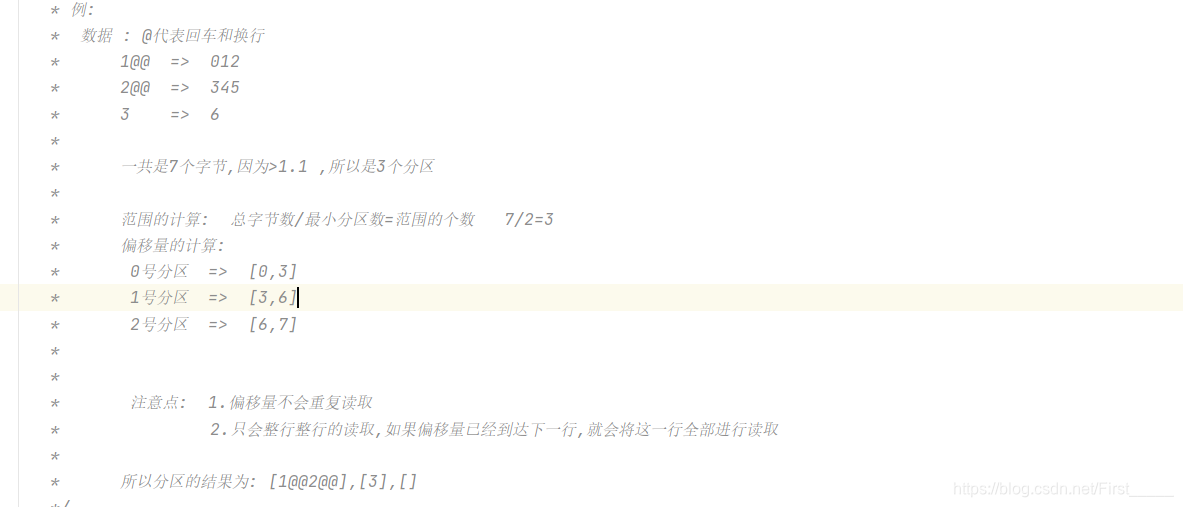
文件具体的数据的分配例子展示:
序列化
因为java中,前期为了考虑安全性, java的序列化方式比较笨重,携带的东西比较多,但是spark出现传输的性能效率来进行考虑,2.0版本之后出现了Kryo方式的序列化,较之前会比较轻便,速度是之前的大约10倍,当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化,如果类也要进行传输,可以进行自行设置.
注册序列化:
注意: 就算是使用Kryo序列化也要进行继承Serializer特质
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
// Array里面放入注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher],classOf[Student]))
RDD常用方法测试(重要)
读取 and 保存
textFile(): 根据数据进行一行一行的读取数据wholeTextFiles(): 根据文件进行读取数据,元组的形式(String,String), 第一个是文件信息,第二个是文件的内容saveAsTextFile(): 将数据保存成文件的格式mapPartitions(): 对数据进行读取,每个分区调用一次,会进行缓存,但是当数据量大,内存小的时候,会造成内存溢出mapPartitionsWithIndex(): 每个分区调用一次,但是可以获取到当前分区号glom(): 拿去到每个分区的数据,以集合的形式
转换算子
-
faltmap(): 会先对数据进行映射,再扁平化 -
map(): 对数据进行映射 -
mapValues(): 只对数据的value值进行修改 -
groupBy():按照某一项数据进行分组,分区数量不变,但是数据会进行重新整合(打散) -
filter():按照某条件对数据进行过滤掉不想要的数据 -
sample(): 当发生数据倾斜时,可以使用这个方法看具体是哪一个数据的问题sample方法介绍: 1.第一个参数 : true 为放回,false 为弃用,不放回 2.第二个参数 : 每个数抽取的概率大概为所输入的概率 (0-1):抽取的概率 >1 :重复的概率 3.第三个参数 : 随机数的种子 -
distinct(): 对重复的数据进行去重内部源码: map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1) -
coalesce(): 对数据进行扩大分区和缩小分区,进行聚合或者数据均衡介绍: 1. 第一个参数: 要聚合成的数据分区数量 2. 第二个参数: true:会对数据进行重新打乱整合,进行shuffle false :不会打乱分区,不会对对数据进行重新整合,不会进行shuffle 3. 可以扩大分区,必须要shuffle , 也可以缩小分区,如果要数据均衡,也需要进行shuffle -
sortBy(): 对数据进行排序, 会进行shuffle,重新整合, ----true(默认):正序 -----false:倒序 -
partitionBy(): 对数据重新进行分区组合,参数里需要添加一个分区器 -
groupBykey(): 根据键值对的key进行分组, 但是不会进行预分区,相比其他几个效率较低 -
reduceByKey(): 根据key进行聚合,分区间和分区内计算逻辑一样 -
aggregateByKey(): 当分区内和分区间的计算逻辑不一样的时候,可以使用第一个参数:是初始值,用来作两两比较的一个初始值 第二个参数: 第一个参数:分区内的计算逻辑 第二个参数: 分区间的计算 -
foldByKey(): 上面方法的简写,当分区内和分区间逻辑一样时,可以进行简写 -
combineByKey(): 比aggregateByKey()方法效率更高参数介绍: 第一个参数: 相同key的第一个数据的转换, v就是分区内相同key的第一个数据的value 第二个参数: 分区内的计算规则 第一个参数a: 就是柯里化,第一个参数的值 第二个参数b: 是分区内其他key所对应的value值 第三个参数: 分区间的计算规则 -
join(): 对数据进行连接 -
leftOuterJoin(): 对数据进行左连接,以左表为主 -
rightOuterJoin():对数据进行右连接,以右表为主 -
cogroup():对数据进行 connect + group, 并会按照key的数据进行分组
(执行)行动算子
reduce(): 聚合所有数据,先聚合分区内的数据,再聚合分区间的数据collect():获取所有数据,以array的形式进行返回count():返回RDD中的元素的个数first():返回RDD中第一个元素的数据take(): 取出前多少位数据元素takeOrdered():先进行排序,再进行取出前面的数据aggregate()():分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合,也就是说,不管是分区内还是分区间的聚合,都会添加这个初始值fold()():上面方法的简化版,如果分区间和分区内计算逻辑相同, 可以使用此方法countByKey(): 统计每种key的个数
累加器(ACC)
累加器: 分布式共享只写变量

原因:进行分布式计算的时候, 变量无法进行返回, driver端的变量还是不会变化. 这时候就要使用累加器变量来完成需求
使用累加器, 和创建自定义累加器
package com.dxy.acc
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{
SparkConf, SparkContext}
import scala.collection.mutable
object Spark02_自定义累加器 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("acc").setMaster("local[*]")
val sc = new SparkContext(conf)
//val acc = sc.longAccumulator("sums")
//使用累加器 统计 wordCount的个数
val rdd = sc.makeRDD(List("hello","word","scala","hello"))
// 注册自定义累加器
val myAcc = new MyAccumulator()
sc.register(myAcc,"wordCount")
// 使用累加器: 分布式只写变量
rdd.foreach(
word => {
myAcc.add(word)
}
)
println( myAcc.value)
sc.stop()
}
//自定义累加器 : 第一个泛型为输入类型, 第二个泛型为输出类型
class MyAccumulator extends AccumulatorV2[String ,mutable.Map[String,Long]]{
//使用map 存储结构
private var map=mutable.Map[String,Long]()
//判断是否为空
override def isZero: Boolean = {
map.isEmpty
}
//进行copy
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
//清空
override def reset(): Unit = {
map.clear()
}
//添加数据
override def add(v: String): Unit = {
map(v)=map.getOrElse(v,0L)+1
}
//进行分区器之间累加器的合并
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1= this.map
val map2= other.value
map2.foreach(
data => {
//进行合并
map1(data._1)= map1.getOrElse(data._1,0L)+data._2
}
)
}
//获取累加器的值
override def value: mutable.Map[String, Long] = {
map
}
}
}
广播变量
广播变量 : 分布式共享只读变量
问题:

解决:
