一、BeanFactoryPostProcessor处理流程
整体流程图:
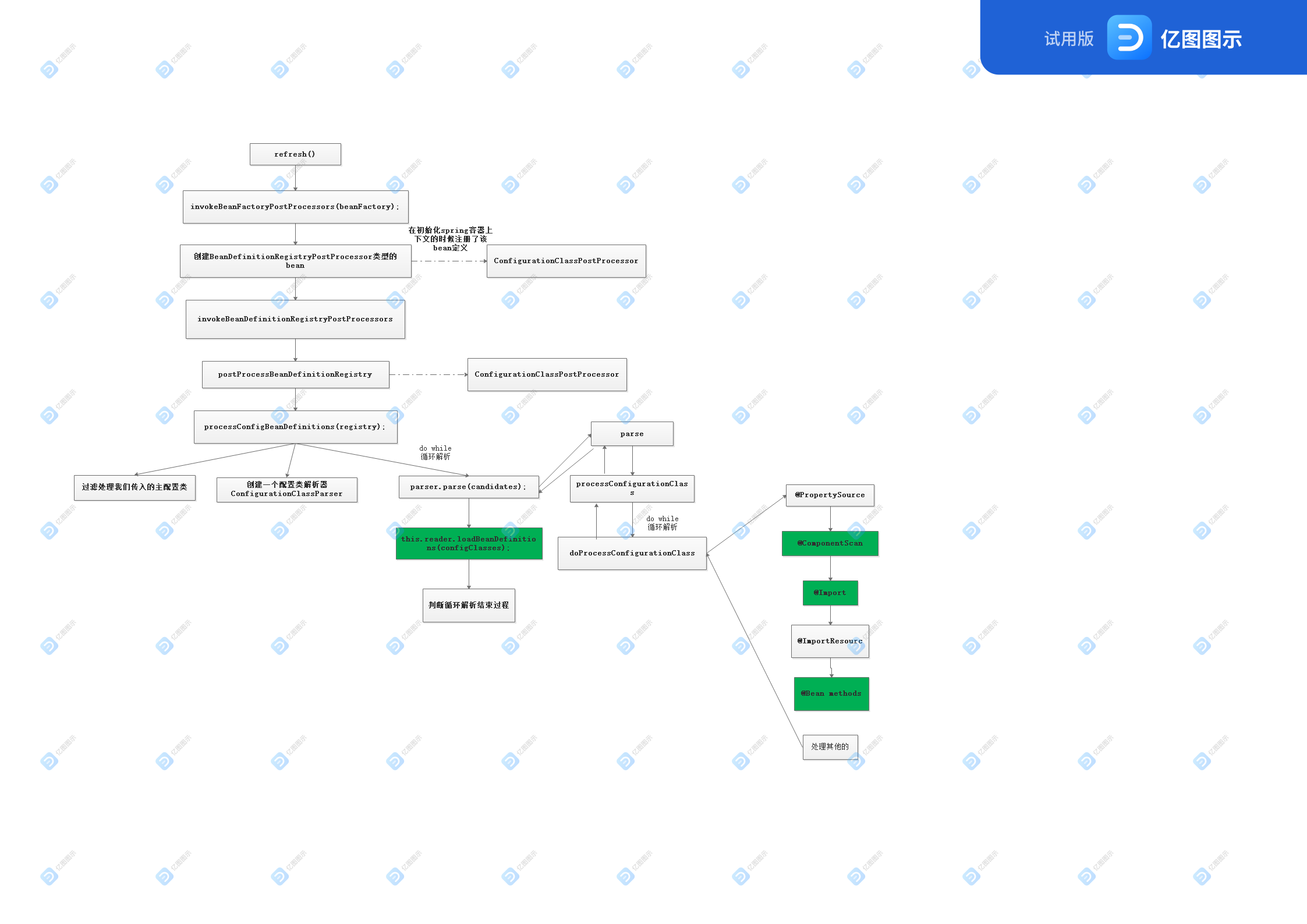
执行时间:所有的Bean定义信息已经加载到容器中,但是Bean实例还没有被初始化
下面我们自己定义一个BeanFactoryPostProcessor,Spring提供了对BeanFactory进行操作的处理器BeanFactoryProcessor,简单来说就是获取容器BeanFactory,这样就可以在真正初始化bean之前对bean做一些处理操作,允许我们在bean工厂里面的所有bean被加载出来但是还有没有进行实例化的时候可以对bean的属性进行修改。
/**
* @author maoqichuan
* @date 2021年10月09日 19:26
*/
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
/**
* 在这里我们在bean实例化之前,修改bean的一些属性信息,配置一些元数据
* @author maoqichuan
* @date 2021/10/9 19:26
*/
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition myBean = beanFactory.getBeanDefinition("myBean");
System.out.println("修改属性name值");
myBean.getPropertyValues().add("name", "liSi");
}
}mainClass源码:
public class MainClass {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(MainConfig.class);
//System.out.println(ctx.getBean(TulingLog.class));
}
}下面这个是整个调用流程的调用链路,从i1->i8,大家可以调用链路来看,最好是打开源码跟着本文章一起分析。
i1:org.springframework.context.support.AbstractApplicationContext#refresh
>i2:org.springframework.context.support.AbstractApplicationContext#invokeBeanFactoryPostProcessors
>i3:org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors
>i4:org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors
>i5:org.springframework.context.annotation.ConfigurationClassPostProcessor#processConfigBeanDefinitions
> i6:org.springframework.context.annotation.ConfigurationClassParser#parse
>i7:org.springframework.context.annotation.ConfigurationClassParser#processConfigurationClass
>i8:org.springframework.context.annotation.ConfigurationClassParser#doProcessConfigurationClass1.1i4源码出解析
源码位置:org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors ,下面是源码,源码里面我有备注里面每一步的具提流程。
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set<String> processedBeans = new HashSet<String>();
// 首先判断IOC容器是不是BeanDefinitionRegistry
if (beanFactory instanceof BeanDefinitionRegistry) {
// 把IOC容器强制转为BeanDefinitioinRegistry类型的
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
// 创建一个普通的PostProcessor的list组件
List<BeanFactoryPostProcessor> regularPostProcessors = new LinkedList<BeanFactoryPostProcessor>();
// 创建一个BeanDefinitionRegistryPostProcessor的list组件
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new LinkedList<BeanDefinitionRegistryPostProcessor>();
// 处理容器硬编码(new 出来的)带入的beanFactoryPostProcessors
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
// 判断是不是BeanDefinitionRegistryPostProcessor
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
//调用BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry
registryProcessor.postProcessBeanDefinitionRegistry(registry);
//加入到集合list中
registryProcessors.add(registryProcessor);
}
else { //判断如果不是BeanDefinitionRegistryPostProcessor
//加入到list集合中
regularPostProcessors.add(postProcessor);
}
}
// 创建一个当前注册的RegistryPostProcessor的集合
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<BeanDefinitionRegistryPostProcessor>();
// 第一步,去容器中查询是否有BeanDefinitionRegistryProcessor类型的
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 判断是否实现了PriorityOrdered接口的
// 第二步:去容器中查询是否有BeanDefinitionRegistryPostProcessor类型的
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 排除被处理过得,并且实现了ordered接口的
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 加入到已处理的list中
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
// 调用BeanDefinitionRegistryProcessors的invokeBeanDefinitionRegistryPostProcessors方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// 调用普通的BeanDefinitionPostProcessor并且没有实现了PriorithOrdered和ordered接口的
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
// 排除被处理过的
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// 调用上诉实现了也实现了BeanFactoryPostProcessors的接口
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
} else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// 去IOC容器中获取BeanFactoryPostProcessor类型的
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// 分离实现了PriorityOrdered接口的Ordered接口的 普通的
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
List<String> orderedPostProcessorNames = new ArrayList<String>();
List<String> nonOrderedPostProcessorNames = new ArrayList<String>();
for (String ppName : postProcessorNames) {
//跳过已经在上面一阶段处理过
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// 首先调用PriorityOrdered
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);// 其次调用Ordered
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// 最后调用普通的
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}1.2 i5源码解析
源码位置:org.springframework.context.annotation.ConfigurationClassPostProcessor#processConfigBeanDefinitions。
- 获取所有的bean名称,然后循环这些bean名称筛选出来用来描述配置类的,就是那种配置@Configuration的bean,如果没有则返回。
- 将配置类进行排序
- 定义bean定义名称的生成策略
- 创建一个组件扫描器,其中组件扫描器里面包括配置元数据读取工厂、问题报告器、环境设置、资源加载器配置。
- 然后通过配置器真正的解析配置类(看到这里,可以跳过下面的解析,先去看对应的parse的源码分析,在接下来一块)
- 校验
- 获取所有@Comfiguration配置过的bean定义信息取出来,然后我们@componentScan是直接注册bean信息的,但是通过@Import,@Bean这种的注解还没有注册到bean定义,所以我们就要一直去循环判去解析注册。
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 去IOC容器中获取Bean定义的名称
List<BeanDefinitionHolder> configCandidates = new ArrayList<BeanDefinitionHolder>();
// 没有解析之前,系统候选的bean定义配置(有自己的 有系统自带的)
String[] candidateNames = registry.getBeanDefinitionNames();
// 循环Bean定义的名称,找出自己传入的主配置类的bean定义信息,configCandidates
for (String beanName : candidateNames) {
// 去bean定义的map中获取对应的bean定义对象
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
// 检查bean定义对象是不是用来描述配置类
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// 检查配置类排序
Collections.sort(configCandidates, new Comparator<BeanDefinitionHolder>() {
@Override
public int compare(BeanDefinitionHolder bd1, BeanDefinitionHolder bd2) {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return (i1 < i2) ? -1 : (i1 > i2) ? 1 : 0;
}
});
// bean定义名称的生成策略
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet && sbr.containsSingleton(CONFIGURATION_BEAN_NAME_GENERATOR)) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}/**
1)元数据读取器工厂
this.metadataReaderFactory = metadataReaderFactory;
2)问题报告器
this.problemReporter = problemReporter;
// 设置环境
this.environment = environment;
3)资源加载器
this.resourceLoader = resourceLoader;
this.registry = registry;
4)创建了一个组件扫描器
this.componentScanParser = new ComponentScanAnnotationParser(
environment, resourceLoader, componentScanBeanNameGenerator, registry);
this.conditionEvaluator = new ConditionEvaluator(registry, environment, resourceLoader);
**/
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
// 将要被解析的配置类(把自己的configCandidates加入到候选的)
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<BeanDefinitionHolder>(configCandidates);
// 已经被解析的配置类(由于do while那么mainclass就一定会被解析,被解析的size为1)
Set<ConfigurationClass> alreadyParsed = new HashSet<ConfigurationClass>(configCandidates.size());
do {
// 通过配置解析器真正的解析配置类
parser.parse(candidates);
// 进行校验
parser.validate();
// 获取configClass(把解析过得配置bean定义信息获取出来)
Set<ConfigurationClass> configClasses = new LinkedHashSet<ConfigurationClass>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// @ComponentScan是直接注册Bean定义信息的,但是通过获取@Import,@Bean这种的注解还没有注册的bean定义
this.reader.loadBeanDefinitions(configClasses);
// 把系统解析过我们自己的组件放在alreadyParsed
alreadyParsed.addAll(configClasses);
// 清楚已经解析过得配置文件
candidates.clear();
// 已经注册的bean定义个数大于最新开始系统+主配置类的(发生解析过得)
if (registry.getBeanDefinitionCount() > candidateNames.length) {
// 获取系统+自己解析的+mainConfig的bean定义信息
String[] newCandidateNames = registry.getBeanDefinitionNames();
// 系统的 +mainConfig的bean定义信息
Set<String> oldCandidateNames = new HashSet<String>(Arrays.asList(candidateNames));
// 已经解析过得自己的组件
Set<String> alreadyParsedClasses = new HashSet<String>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
// 老的(系统的+mainConfig)不包含解析的
if (!oldCandidateNames.contains(candidateName)) {
// 把当前的bean定义获取出来
BeanDefinition bd = registry.getBeanDefinition(candidateName);
// 判断是否解析过
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
// 若不过解析过切通过检查的 把当前的bean定义信息加入candidates中
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
// 把解析过得赋值给原来的
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty()); // 还存在没有解析估的 再次解析
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null) {
if (!sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}1.3 i6出源码分析
源码位置:org.springframework.context.annotation.ConfigurationClassParser#parse
这里他会判断你的配置类是注解的定义还是超类的定义
public void parse(Set<BeanDefinitionHolder> configCandidates) {
this.deferredImportSelectors = new LinkedList<DeferredImportSelectorHolder>();
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
processDeferredImportSelectors();
}这里他会递归处理配置类及其超类层次结构。
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
for (Iterator<ConfigurationClass> it = this.knownSuperclasses.values().iterator(); it.hasNext();) {
if (configClass.equals(it.next())) {
it.remove();
}
}
}
}
// 递归处理配置类及其超类层次结构
SourceClass sourceClass = asSourceClass(configClass);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}- 处理@PropertySource注解(这里因为不经常使用就不做具体代码分析)
- 处理@ComponentScan注解,他这里会解析@ComponentScan注解属性,会解析成一个一个的componentscan对象。
- 循环@ComponentScan的set,然后立即去解析。(大家看到这里也可以先跳到对应的parse的源码,看完那个源码解析再出来到这里继续往下看)。
- 循环检查扫描得到的bean列表,检查任何其他的配置类定义信息集,并在需要的时候递归解析。(其实这里怎么理解呢,我的理解就是他为了防止一些情况,比如说是我在@Controller注解上面加@ComponentScan注解)
- 处理@Import注解,解析@Import的ImportSelector、ImportBeanDefinitionRegistry @Bean这种。
- 处理@ImportResource annotations
- 处理 @Bean methods
- 处理接口
- 处理超类。
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass);
// 处理@PropertySource注解
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.warn("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}// 处理@ComponentScan注解
// 解析@compoment注解属性 封装成一个一个的componentscan对象
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
//循环componentscans的set
for (AnnotationAttributes componentScan : componentScans) {
// 立即执行扫描解析
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// 检查任何其他配置类的扫描定义信息集,并在需要时递归解析
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
// 获取原始的bean定义信息
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
// 检查当前的bean定义信息是不是配置类 比如MainConfig的bean定义信息
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
// 递归调用来解析MainConfig,解析出来配置类中导入的bean定义信息
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// 处理@import注解 解析Import注解的ImportSelector ImportDeanDefinitionRegistry @bean这种
processImports(configClass, sourceClass, getImports(sourceClass), true);// 处理@ImportResource annotations
if (sourceClass.getMetadata().isAnnotated(ImportResource.class.getName())) {
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// 处理 @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// 处理接口
processInterfaces(configClass, sourceClass);
// 处理超类
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (!superclass.startsWith("java") && !this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}通过组件扫描器进行真正的解析org.springframework.context.annotation.ComponentScanAnnotationParser#parse,源码如下:
- 首选他会创建一个类路径下的bean定义扫描器,下面会有对应里面具体的源码分析。
- 为扫描器设置一个bean名称的生成器
- 然后为扫描器设置一些列属性,细心的大家可以发现,这些属性就是@ComponentScan支持的注解属性,也就是我们在上一篇博客中介绍到的注解属性
- 真正执行解析。
Set<BeanDefinitionHolder>
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
Assert.state(this.environment != null, "Environment must not be null");
Assert.state(this.resourceLoader != null, "ResourceLoader must not be null");
// 创建一个类路径下的bean定义扫描器
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
// 为扫描器设置一个bean名称的生成器
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet<String>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
basePackages.addAll(Arrays.asList(tokenized));
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
// 真正扫描器扫描指定路径
return scanner.doScan(StringUtils.toStringArray(basePackages));
}类路径的bean定义扫描器,源码分析,可以看到他这里使用的是默认的扫描规则。我们再进去看看里面具体的默认的扫描规则是怎么样的。
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
// 使用默认的扫描规则
if (useDefaultFilters) {
registerDefaultFilters();
}
//设置环境变量
setEnvironment(environment);
// 设置资源加载器
setResourceLoader(resourceLoader);
}使用默认的扫描规则,具体源码分析如下:
- 首先添加了@Component的解析,其实这也就解释了为什么我们的@Component、@Respository、@Service、@Controller注解能够被扫描到的原因
- 添加jsr250注解
- 添加JSR300注解
protected void registerDefaultFilters() {
// 添加了Component的解析,这就是我们为啥@componet @Respository @Service @Controller能够被扫描到
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
// 添加jsr 250规范的注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.debug("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
// 添加JSR330的注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.debug("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}使用扫描器去真正的扫描类,返回Set<DefinitionHolder>,源码分析:
- 创建一个BeanDefinitionHolder的set,然后循环去扫描对应的路径,然后通过findCandidateComponents找到候选组件,我们可以跳到对应这里的源码解析,看看他具体是怎么样找到候选的组件信息的。
- 找到了对应的候选组件,他就会循环候选组件的集合,然后给候选组件生成bean的名称,然后判断是不是抽象的bean定义或者是不是注解的bean定义。
- 然后他会检查当前的bean定义是否跟之前的存在有冲突,如果没有存在冲突,他会给这个bean定义封装成一个BeanDefinitionHolder,然后加入到bean定义的集合中,然后注册该bean信息,这也是刚刚我们在上面说的,@ComponentScan为什么会直接注册bean定义信息。
- 返回扫描的所有bean定义集合信息。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
// 创建一个bean定义holder的set
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<BeanDefinitionHolder>();
// 循环扫描路径
for (String basePackage : basePackages) {
// 找到候选的组件
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 循环候选组件的集合
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成bean的名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 判断是不是抽象的bean定义
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 注解的bean定义
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//检查当前的和主的bean定义是否有冲突
if (checkCandidate(beanName, candidate)) {
// 把候选的组件封装成BeanDefinitionHolder
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
// 加入到bean定义的集合中
beanDefinitions.add(definitionHolder);
// 注册当前的bean定义信息
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}找到候选的组件列表,源码位置:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#findCandidateComponents
- 首先他会拼接我们扫描包下面的类路径,比如是:classpath*:com/tuling/testapplicationlistener/**/*.class
- 把所有的源文件路径解析成一个个的.class文件
- 循环解析.class文件的resources对象,首先他会判断该文件是否是可读的,不可读则跳过
- 然后会把resource对象封装成一个源信息读取器
- 然后会判断该源信息读取器是否为候选组件,这里我们这里跳到下面的源码分析,看看他具体是怎么判断该源信息读取器是否为候选组件。
- 如果是候选组件,他就会把当前解析出来的定义加入到BeanDefinition的集合中。
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 候选的bean定义信息
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try {
// 拼接需要扫描包下面的类的路径 classpath*:com/tuling/testapplicationlistener/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 把路径解析成一个个.class文件
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 循环.class的resource对象
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
// 首先判断class文件是否可读
if (resource.isReadable()) {
try {
// 把resource对象编程一个类的原信息读取器
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
// 判断类的源信息读取器是否为候选的组件
if (isCandidateComponent(metadataReader)) { // 是候选组件
// 把类源信息读取器封装成一个ScannedGeneriBeanFinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
// 是候选组件
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
// 把当前解析出来的定义加入到BeanDefinition的集合中
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}return candidates;
}
判断源信息读取器是不是需要扫描的组件,源码分析如下:
- 首先会判断是不是被排除的
- 然后会判断当前组件是不是被包含的,如果是被包含会判断该组件是不是能够通过@Conditional进行判断的。
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// 判断是不是被排除的
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
// 在包含的组件
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return isConditionMatch(metadataReader);
}
}
return false;
}不是能够被进行@Conditional判断,源码分析如下:
private boolean isConditionMatch(MetadataReader metadataReader) {
if (this.conditionEvaluator == null) {
this.conditionEvaluator = new ConditionEvaluator(getRegistry(), getEnvironment(), getResourceLoader());
}
return !this.conditionEvaluator.shouldSkip(metadataReader.getAnnotationMetadata());
}