一、集合的框架(转载自)
1、集合的概述
为了在程序中保存数目不确定的对象,java提供了一系列特殊的类,这些类可以存储任意类型的对象,并且长度可以改变,这些类都称为集合.集合类都位于JAVA。uti包中使用时必须导包。
可以大概分两类
COllection:单列集合的根接口
-------LIst、列表
--------------**ArrayList 、动态数组 ; LInkedList、链表数组;Vector **
-------Set、集合
--------------HashSet、哈希集合
----------------------------LinkedHashSet、链式散列集
--------------TreeSet、树集合
Map:双列集合类的根接口
-------HashTable、、哈希表
--------------Properties、、特性
-------HashMap、、哈希图
--------------LInkedHashMap、、
-------TreeMap、、矩形树图
2、为什么要集合框架
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定。数组无法满
足。 就使用集合容器进行存储。集合容器因为内部的数据结构不同,有多种具体容器。
不断的向上抽取,就形成了集合框架。
框架的顶层是Collection接口,定义了集合框架中共性的方法。
数组的插入删除速度太慢,查找速度比较快。
集合的插入删除速度比较快,查找慢。
3、Collection接口
Collection是所有单列集合的父接口,他定义啦单列集合(LIst和Set)通用的一些方法,这些方法可以操作所有的单列集合
实际开发很少用Collection ,更多的是用子接口的方法。
没有get
二、LIst接口(ArrayLIst重要)
-------LIst、列表
--------------**ArrayList 、动态数组 ; LInkedList、链表数组;Vector **
ArrayList集合
ArrayLIst的本质还是一个数组,不过是一个已经封装好的数组了,这个数组的长度可以可以改变,长度不够时,ArrayLIst会在内存中分配一个更大的数组来保存元素
特点:
因为ArrayLIst的长度改变方式的原因,所以效率比较低,因此不适合做大量的增加和删除操作,但是他允许通过索引的方式来访问元素,所以查找元素比较便捷。
创建和使用
public static void main(String[] args) {
ArrayList list=new ArrayList ();//创建AeeayLIst类
}
常用方法
| size() | 数组中数据的个数并不是长度 |
|---|---|
| 方法名 | 含义 |
| add() | 追加 |
| get(index) | 根据下标获取值 |
| isEmpty() | 判断ArrayList中是否有数据 |
| indexOf(数据 ) | 获取aa在ArrayList中首次出现的索引,有返回,没有-1 |
| lastIndexOf(数据) | 返回数据最后一次出现的索引 |
| contains(数据) | 判断数据在ArrayList中是否存在 |
| remove(index)/remove(obj) | 根据下标删除,或者直接删除数据 |
| toArray() | 将List转换成数组 |
| clear() | 清空List列表 |
| set(索引,“数据”) | 将指定索引的数据修改 |
遍历
普通for
//个数遍历size()
for(int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
增强for
//增强性for
for (Object o : list) {
System.out.println(o);
}
迭代器
//迭代器
Iterator it=list.iterator();
while (it.hasNext()){
Object obj=it.next();//拿object这个类型的值可以接任何数据类型
System.out.println(obj);
}
底层(对数组的操作)
自己把着去看
泛型
LInkedLIst集合和vector
LinkedList:链表结构,有序,插入和删除速度快,遍历查找速度慢
LinkedList list=new LinkedList();
list.add(1);
list.add(2);
list.add(3);
list.add("4");
for(Object obj:list){
System.out.println(obj+"\t");
}
Vector:ArrayList和Vector实现原理都一样,ArrayList:线程不安全,效率高。
Vector list=new Vector();
list.add(1);
list.add(2);
list.add(3);
list.add("4");
for(Object obj:list){
System.out.println(obj+"\t");
}
Vector:线程安全,效率低;
Iterator接口(也被称为迭代器)
专门用来遍历集合中所有元素集合的时候使用的方法
注意:迭代器获得的元素时,这些元素类型都是Object类型的,如果需要特定数据类型的时候需要强转。
Iterator it=list.iterator();
while (it.hasNext()){
Object obj=it.next();//拿object这个类型的值可以接任何数据类型
if(obj.equals(1)){
//删除
list.remove(obj);
break;
}
}
System.out.println(list);
| 返回类型 | 方法 | 描述 |
|---|---|---|
| boolean | hasNext() | 如果有元素可迭代 |
| Object | next() | 返回迭代的下⼀个元素 |
三、Set接口
Set集存储的顺序无序,不可以保存重复元素。
TreeSet是可以保持自然顺序或者定义的比较器的比较的结果顺序的set集合
是以二叉树的方式来存储元素可以实现对集合中的元素进行排序
LInkedHashSet维护一个双重列表,能保存添加是的顺序
1.HashSet类(底层是HashMap)
可以存储任意对象类型的数据 包括null
无序
数据不能重复 数据结构跟LIst不同
没有下标 查找慢,插入删除快。
2.HashSet的创建使用
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add(1);
set.add("abc");
set.add("你好哈哈哈");
set.add(1);//数据不重复 会自动除重
set.add("hello world");
set.add("5sc");
//使用迭代器遍历
Iterator<Object> iterator = set.iterator();
/*while (iterator.hasNext()){
System.out.println(iterator.next());
}*/
//使用for each遍历
for (Object o : set) {
System.out.println(o);
}
}
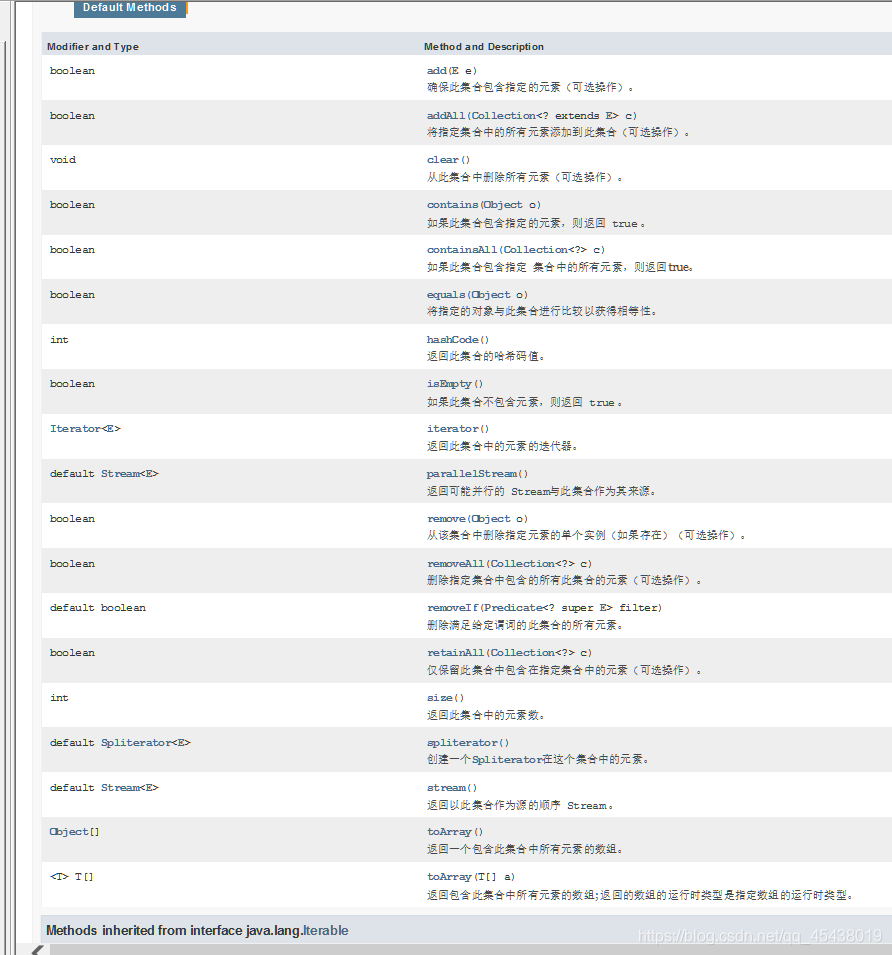
3、常用方法
add:添加
clear:删除集合所有元素
clone:返回Hashset实例浅层副本 本身不被克隆
contains:判断是否有指定元素 有返回true;
isEmpty:判断集合不包含元素就返回true
iterator:迭代器
remove:删除
size:元素个数
spliterator 快速出击late-binding和故障快速Spliterator
4、iterator 迭代器
因为hashset没有下标 所以需要迭代器来使用
因为HashSet的内部数据结构是哈希表,线程是不安全的。为了保证对象元素的内容角度唯一,必须覆盖hashCode方法和equals方法。
5、TreeSet
基于TreeMap实现比较器
基本数据类型 按照默认的排序 ,和String类中重写了compareTo()方法定义了字符排序的规则。
默认按照元素自然排序,必须实现Comparable接口
有序;不重复;添加删除判断效率高;
TreeSet排序方式
1、如果是基本数据类型和String类型,可以直接进行排序
2、对象类元素排序,需要实现Comparable接口,并覆盖其compareTo方法
实现步骤:排序的类实现Comparable接口,重写compareTo方法,并在方法里定义排序规则
3、另一种对象类元素排序:需要实现Comparator接口,并覆盖其compare()方法。
创建比较器,实现comparator接口,重写compare方法,在方法里定义排序规则。
TreeSet:可以对set集合进行排序,线程不安全。
判断元素不重复方法是:根据比较方法的返回结果是否为0,如果是0,则是相同元素,不存,如果不是0,则是不同元素,存储。
注意:LinkedHashSet是一种有序的Set集合,即其元素的存入和输出的顺序是相同的。
案例 排序方法2
public static void main(String[] args) {
//comparable接口 并且要重写 compareTo()方法
TreeSet<Student> students=new TreeSet<>();
students.add(new Student("张三",18));
students.add(new Student("张2",119));
students.add(new Student("张1",189));
students.add(new Student("张4",184));
System.out.println(students);
}
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
Student o1 = (Student) o;
if(this.age>o1.age){
return -1;
}else if(this.age<o1.age){
return 1;
}else {
return 0;
}
}
}
案例排序方法3
测试类
public static void main(String[] args) {
//comparable接口 并且要重写 compareTo()方法
PeoCompar student=new PeoCompar();
//创建一个比较器对象
TreeSet<Student> students=new TreeSet<>(student);
students.add(new Student("张三",18));
students.add(new Student("张2",119));
students.add(new Student("张1",189));
students.add(new Student("张4",184));
for (Student stu:students){
System.out.println(stu);
}
比较器
public class PeoCompar implements Comparator {
@Override
public int compare(Object o1, Object o2) {
//将数据强转成Student类型
Student p1=(Student) o1;
Student p2=(Student) o2;
if(p1.getAge()>p2.getAge()){
return -1;
}else{
return 1;
}
}
}
学生类
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
二维数组
public static void main(String[] args) {
ArrayList arrayList=new ArrayList();
//String[][] ints=new String[9][];
//list嵌套list
for (int i=0;i<9;i++){
List list=new ArrayList<>();
for (int j=0;j<=i;j++){
list.add((i+1)+"*"+(j+1)+"="+(i+1)*(j+1));//给数组赋值
}
arrayList.add(list);
}
for (int i=0;i< arrayList.size();i++) {
List list=(List) arrayList.get(i);
for (int j=0; j < list.size(); j++) {
System.out.print(list.get(j) + "\t");
}
System.out.println();
}
}
四、MAP接口
Map是一种双列集合,他的每个元素都包含一个 键对象key,一个值对象value,key和value是一种对应关系,称为映射,通过找键就能知道值value
key和value可以是任意数据类型,key具有唯一性,value可以重复
Map 存储的是键值对 类似JSON的对象
1、HashMap集合
是MAP接口的实现类,用于存储键值对的映射关系,没有重复键,键值对没有顺序
如果添加重复的key,后⾯的覆盖前⾯的。
2、创建使用
属性名:属性值,key:value。
增加 put
删除 remove
修改 put
遍历
1、遍历values 值 无序
2、遍历key
3、遍历节点对象entry
public static void main(String[] args) {
//声明一个列表存储多个学生
//每行信息存储多个相同信息还是用list
//声明一个对象 存储一个学生对象 项姓名 年龄
HashMap map=new HashMap();
map.put("name","张三");
map.put("age",11);
System.out.println(map.get("name"));//根据key name 获取 姓名//张三
HashMap map1=new HashMap();
map1.put("name","张2");
map1.put("age","33");
System.out.println(map1.get("age"));//33
/* Map *///遍历
Collection values = map1.values();
for(Object obj: map.keySet()){
System.out.println(obj+"\t");//张三//11
}//无序的 key
System.out.println("+++++");
Set set=map.keySet();
for (Object key:set){
System.out.println(key+"---"+map.get(key)+"\t");//name---张三//age---11
//Map 遍历节点对象
Set<Map.Entry> entrys=map.entrySet();
for (Map.Entry entry:entrys){
System.out.println(entry.getKey()+"===="+entry);
//name====name=张三 age====age=11
}
}
}
3、底层
HashMap的底层结构实际上是“链表散列”,即数组和链表的结合体。
HashMap的put和get的实现
put(key,value)原理
先将key和value封装到一个对象里面 ,
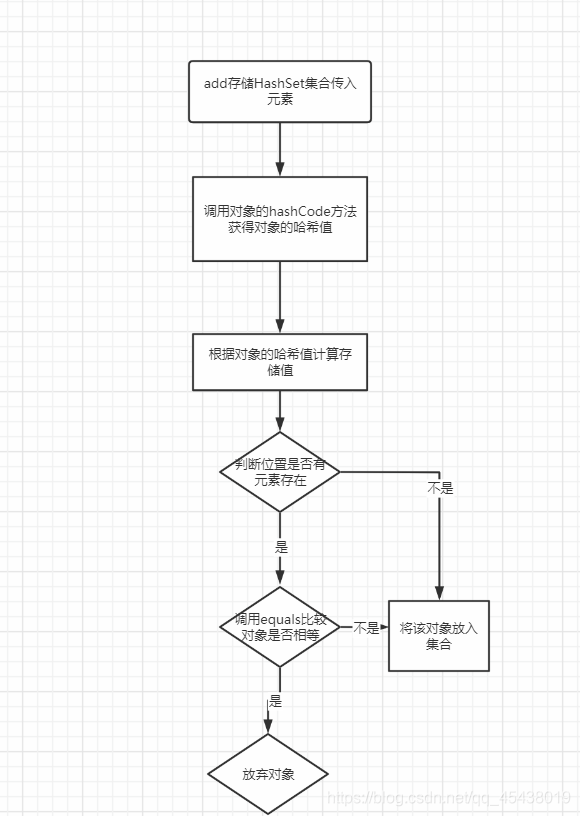
然后调用hashCode方法求出hash值,通过哈希表函数/哈希算法,将hash值转换成数组的下标,判断该位置上是否已有元素,如果已经有元素存在,则遍历该Entry[]数组位置上的单链表。判断key是否存在(equals判断),如果key已经存在,则用新的value值,替换点旧的value值,并将旧的value值返回。如果key不存在于HashMap中,程序继续向下执行。将key-vlaue, 生成Entry实体,添加到HashMap中的Entry[]数组中。
get(key)原理
在get方法中,首先通过hashCode方法计算hash值,然后调用indexFor()方法得到该key在table中的存储位置(下标),得到该位置的单链表(如果这个位置什么的没有返回null),遍历列表找到key和指定key内容相等的Entry(equals方法)(如果equals都返回fals,get返回一个null,),返回entry.value值。
4、哈希表 HashTable
哈希表是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映射到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。作为线性数据结构与表格和队列等相比,哈希表无疑是查找速度比较快的一种。
不允许空key null不能
key无序 linkedHashMap是有序的
TreeMap是自然序
HashTable是线程不安全的 ConcurrentHashMap:是线程安全
5、HashMap和HashTable的区别
1、HashTable是线程安全的,HashMap是线程不安全的
Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合。{
来源}
2、HashMap可以用null来做key HashTable不可以(尽量别用)
3、HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类。
4、容量
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
HashMap扩容时是当前容量翻倍即:capacity2,Hashtable扩容时是容量翻倍+1即:capacity2+1。
Properties
这个类:可以当成map用
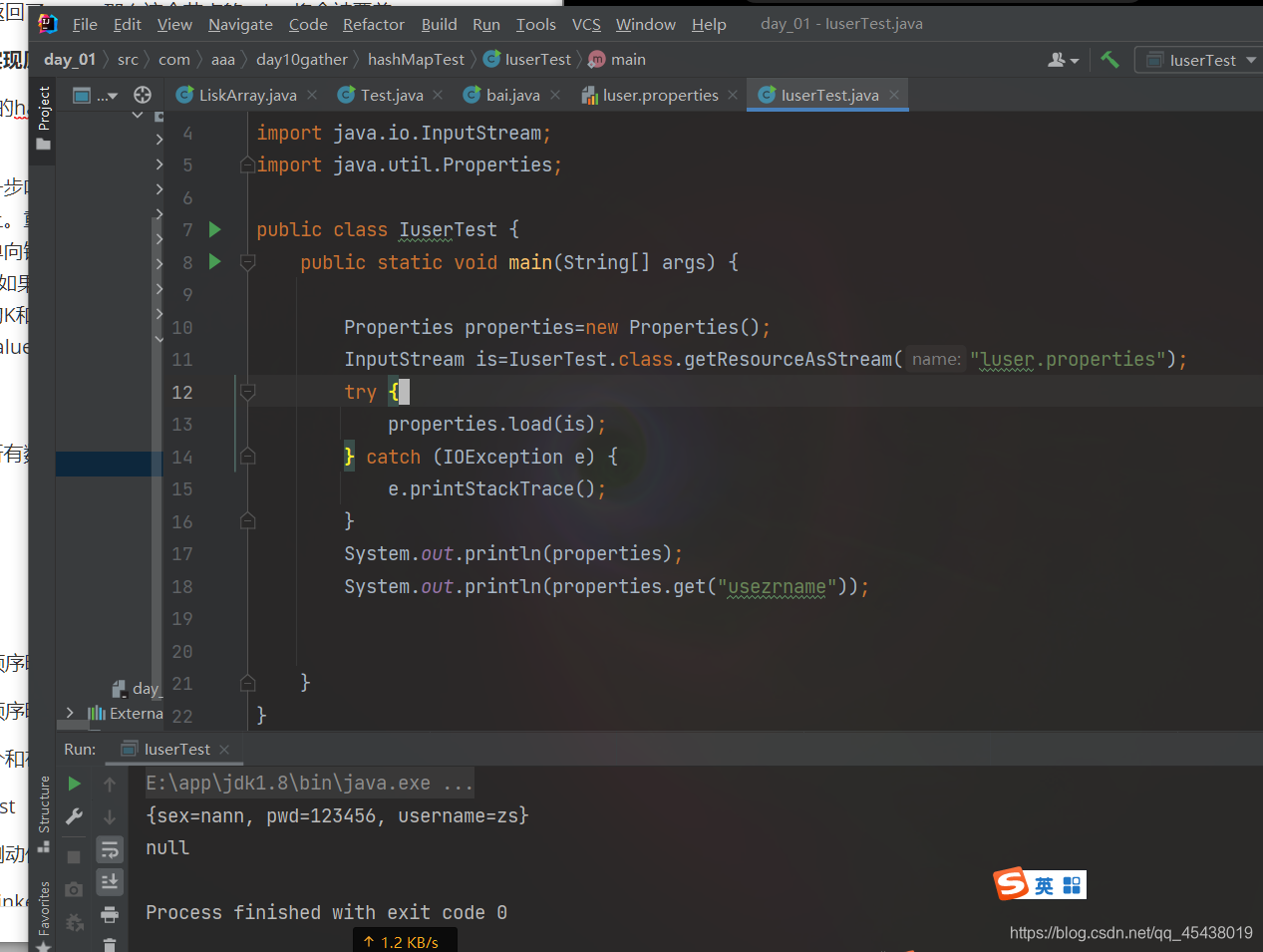
嵌套
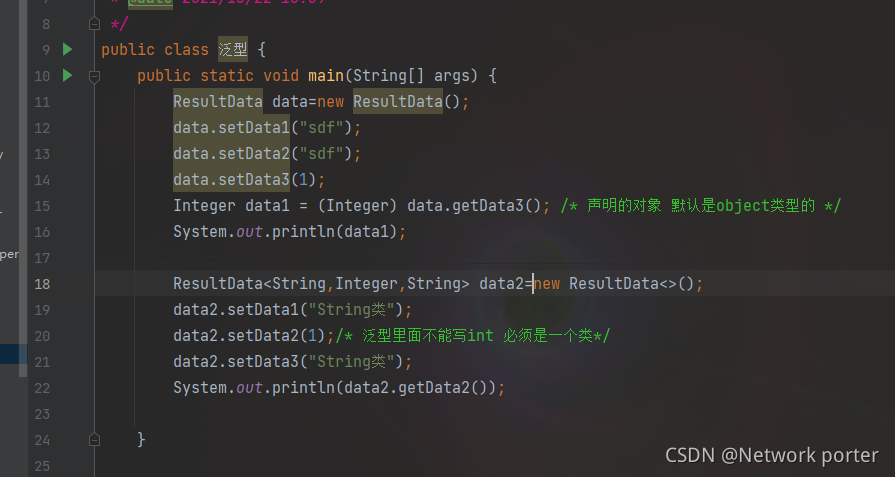
泛型
概念
什么是泛型 E:泛型的一个占位符 数据类型的代指-----参数化数据类型
意思是我传递啦一个数据类型
LIst list=newArrayList();
list.add(1);
泛型在编译阶段的一种特性 (运行阶段没有用)
泛型:参数化数据类型 ,写一个类的时候数据类型没有定死,声明的时候给这个占位符赋值
为什么用泛型
因为list中对存储的内容没有限制,所以取值需要强转,当使用泛型的时候就不需要强转了
1、规范数据类型的存储
2、避免了强转
3、只存在于编译期
public static void main(String[] args) {
List<String> list=new ArrayList<String>();//限制了存储类型
List<Integer> list1=new ArrayList<Integer>();
list.add("sdf");//list类型是String
list.add("3");
list1.add(32);//list1类型是int类型
System.out.println(list.get(1));
for (String str:list){
System.out.println(str);
}
}
自定义泛型类
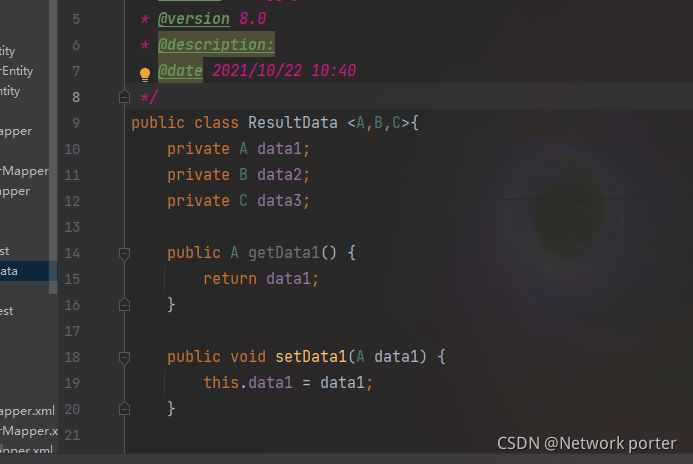
注解(注释类型)
内置注解
注解 又被称为注释类型 Annotation
* 第一 语法格式 @注解类型名
* 第二 注解可以出现在类,属性上,方法上,变量上,
注解还可以出现在注释类型上
注解是引用数据类型 
常见的注解
Dekprecated 注释的程序元素
Override 表示一个方法声明打算重写超类中的另一个方法声明
SuppressWarnings 指示应该在注释元素中取消显示指定的编译器警告
Override 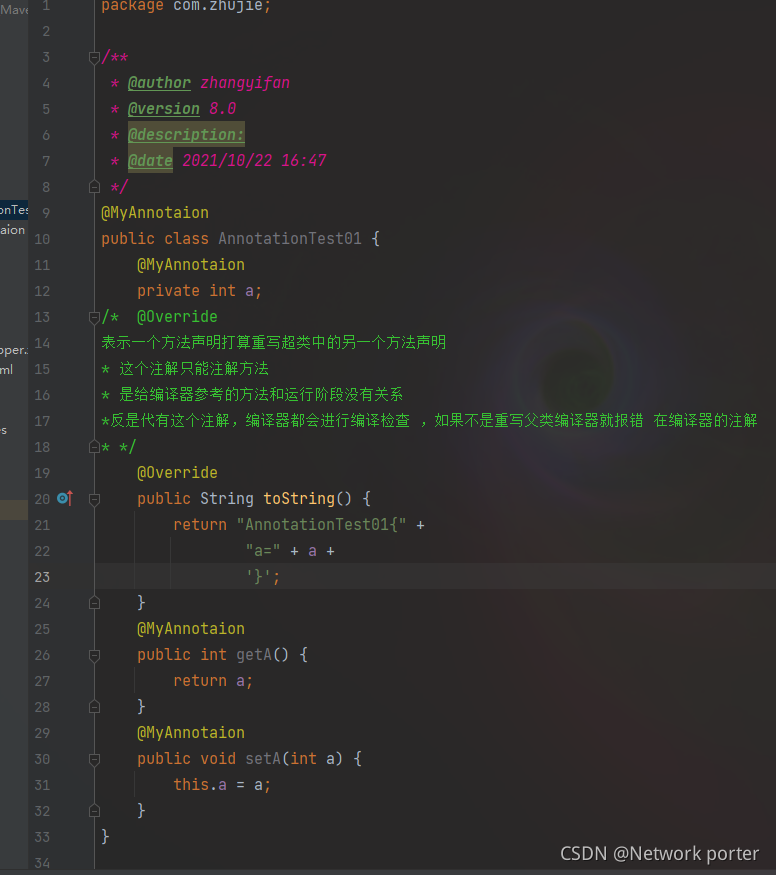
Dekprecated
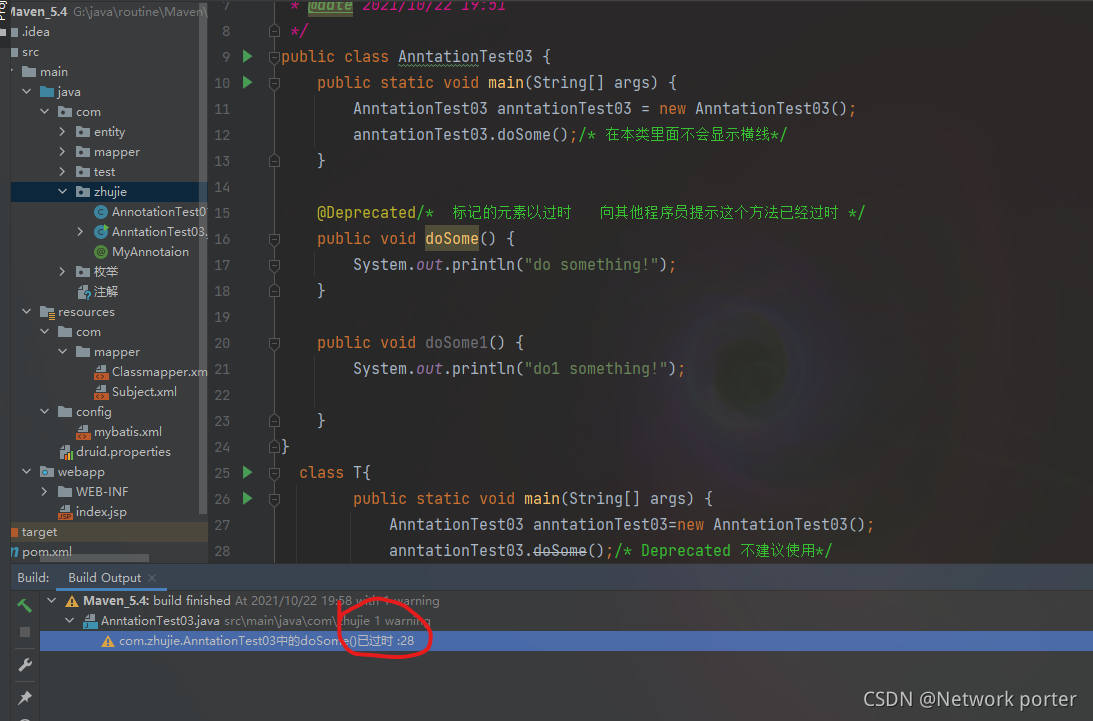
元注解
什么是元注解
用来注解 “注解类型的” 注解 被称为元注解
常见的元注解
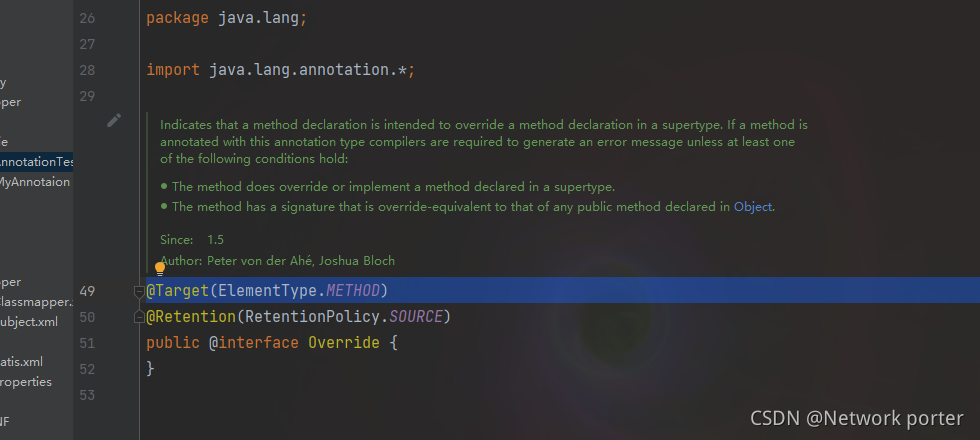
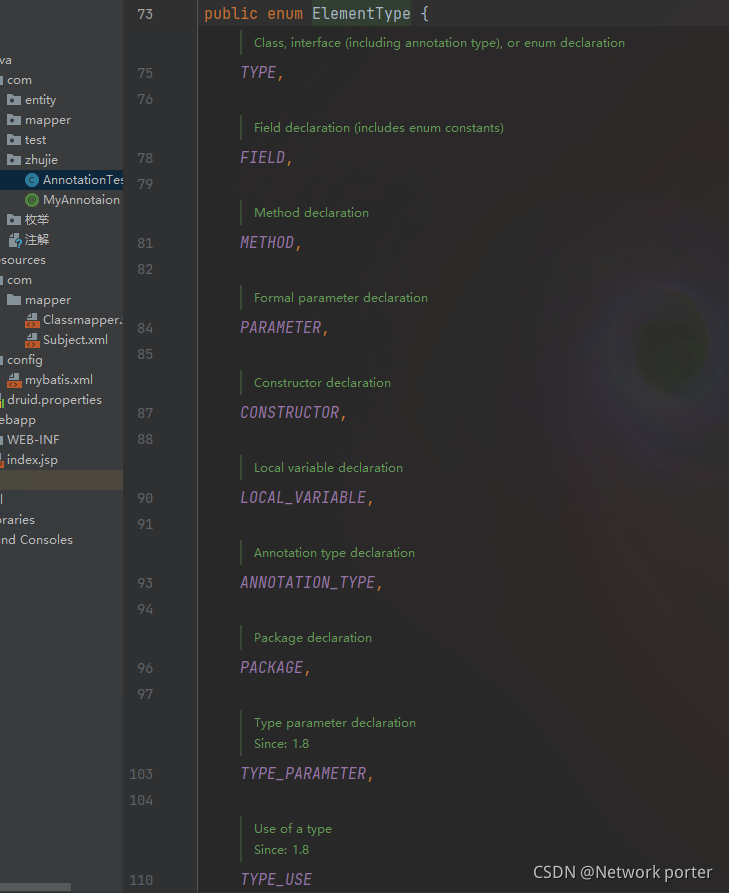
Target 元注解
@Target(ElementType.METHOD) 表示这个注解只能出现在方法上面
用来指定被注解的注解可以出现的位置 在什么地方
REtention元注解
@Retention(RetentionPolicy.SOURCE) //表示该注解保留在java源文件中。
@Retention(RetentionPolicy.CLASS) //被保存在class文件中
@Retention(RetentionPolicy.RUNTIME) //保存在class文件中并且可以被反射方获取到
用来标注被“标注的注解”最终保留在什么地方