参考资料:https://zh-v2.d2l.ai/chapter_computer-vision/ssd.html
其中代码稍有修改
1. 模型搭建
这里直接贴上代码,这部分框架比较清晰,没有改动,可以正常使用。
SSD的框架图:
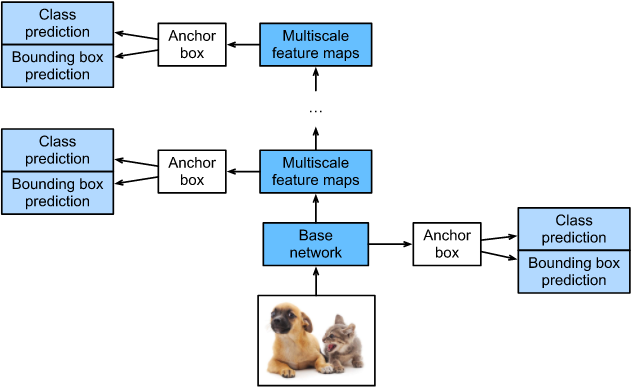
详细具体的搭建流程可以查看参考资料,以下是参考代码:
# 以下属于ssd模型的定义
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
def bbox_predictor(num_inputs, num_anchors):
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))
return nn.Sequential(*blk)
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1))
else:
blk = down_sample_blk(128, 128)
return blk
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
class TinySSD(nn.Module):
def __init__(self, num_classes=1, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
# 即赋值语句 `self.blk_i = get_blk(i)`
setattr(self, f'blk_{
i}', get_blk(i))
setattr(self, f'cls_{
i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
setattr(self, f'bbox_{
i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# `getattr(self, 'blk_%d' % i)` 即访问 `self.blk_i`
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{
i}'), sizes[i], ratios[i],
getattr(self, f'cls_{
i}'), getattr(self, f'bbox_{
i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
其中模型框架打印如下:
<bound method Module.modules of TinySSD(
(blk_0): Sequential(
(0): Sequential(
(0): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
(cls_0): Conv2d(64, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_0): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(blk_1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(cls_1): Conv2d(128, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_1): Conv2d(128, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(blk_2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(cls_2): Conv2d(128, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_2): Conv2d(128, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(blk_3): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(cls_3): Conv2d(128, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_3): Conv2d(128, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(blk_4): AdaptiveMaxPool2d(output_size=(1, 1))
(cls_4): Conv2d(128, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_4): Conv2d(128, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)>
对于模型搭建的核心代码是:
anchors = multibox_prior(Y, sizes=size, ratios=ratio)
对多个特征图的每一个像素点为中心,生成多个anchor
2. 自定义数据集
在上一篇blog中简单介绍过了这里使用的数据集:多尺度检测及检测数据集,不过直接使用代码出现了各种各样的问题,所以这里不得不重新构建了一个自定义数据集。
参考代码:
# 一个用于加载香蕉检测数据集的自定义数据集
class BananasDataset(Dataset):
def __init__(self, is_train):
# 加载图像与标签信息
self.images, self.labels = self.read_data_bananas(is_train)
# 根据训练集或测试集打印出数量
print('read ' + str(len(self.images)) + (' training examples' if is_train else ' validation examples'))
def __getitem__(self, item):
image = self.images[item]
label = self.labels[item]
# print("image: ", image, "label: ", label)
# 对图像进行预处理
transform = transforms.Compose([
# 转换为RGB图像
lambda x: Image.open(x).convert('RGB'),
# 转换为Tensor格式
transforms.ToTensor(),
# 使数据分布在0附近
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
image = transform(image)
# label是int形式,转换为tensor格式
label = torch.tensor(label)
return image, label
# 对每一张图像的处理, 这里转变为了浮点数
# return (self.images[idx].float(), self.labels[idx])
def __len__(self):
# 返回图像数量
return len(self.images)
def read_data_bananas(self, is_train=True):
# 保存测试集与训练集的图像是一致的
datapath = 'E:\学习\机器学习\数据集\\banana-detection'
csv_file = os.path.join(datapath, 'bananas_train' if is_train else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_file)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
# 迭代每一行,添加信息
for img_name, target in csv_data.iterrows():
# 每张图像的路径
imagepath = os.path.join(datapath, 'bananas_train' if is_train else 'bananas_val', 'images', f'{
img_name}')
# 读取图片数据, 类似于Image.open(x).convert('RGB')
# images.append(torchvision.io.read_image(imagepath))
images.append(imagepath)
# target中包含了类别与边界框信息(左上角与右下角组成),eg:[0, 104, 20, 143, 58]组成的一个列表
targets.append(list(target))
# 对于边界框与类别信息在第2个维度前做了增维处理, 并且进行归一化处理, 图像的尺寸是256
# labels.shape: torch.Size([1000, 1, 5])
return images, torch.tensor(targets).unsqueeze(1) / 256
3. 模型训练
在训练过程中的核心代码是bbox_labels, bbox_masks, cls_labels = multibox_target(anchors, Y)一句,根据生成的anchor与真实边界框,对anchor进行分配。计算出anchor相对于真实边界框的偏移量,掩码,既类别。为下一步做损失计算做准备。
参考代码:
# 训练代码
def ssd_train():
# net = TinySSD(num_classes=1)
# X = torch.zeros((32, 3, 256, 256))
# anchors, cls_preds, bbox_preds = net(X)
#
# print('output anchors:', anchors.shape)
# print('output class preds:', cls_preds.shape)
# print('output bbox preds:', bbox_preds.shape)
# 对于测试集,无须按随机顺序读取
train_iter = DataLoader(BananasDataset(is_train=True), batch_size, shuffle=True)
val_iter = DataLoader(BananasDataset(is_train=False), batch_size)
print(len(train_iter), len(val_iter))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = TinySSD(num_classes=1)
optimizer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
cls_loss = nn.CrossEntropyLoss(reduction='none')
bbox_loss = nn.L1Loss(reduction='none')
# 总损失 = 类别损失 + 偏移量损失
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = cls_loss(cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox
# 分类结果评价
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维, `argmax` 需要指定最后一维。
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
# 边界框偏移评价
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
# 模型训练
net = net.to(device)
for epoch in range(num_epochs):
# 训练精确度的和,训练精确度的和中的示例数
# 绝对误差的和,绝对误差的和中的示例数
result = []
net.train()
for iteridx, (features, target) in enumerate(train_iter):
optimizer.zero_grad()
X, Y = features.to(device), target.to(device)
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = multibox_target(anchors, Y)
# 根据类别和偏移量的预测和标注值计算损失函数
loss = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks)
loss = loss.mean()
loss.backward()
optimizer.step()
result.append([cls_eval(cls_preds, cls_labels), # 计算正确个数
cls_labels.numel(), # 真实对象标签总数量
bbox_eval(bbox_preds, bbox_labels, bbox_masks), # 计算边界框偏移
bbox_labels.numel()]) # anchor标签总数量
if iteridx % 9 == 0:
print("epoch:{}/{}, batch:{}/{}, loss:{}"
.format(epoch + 1, num_epochs, iteridx, len(train_iter), loss))
# print(len(result), result)
result = torch.tensor(result)
print("result.shape:", result.shape)
cls_rig = result[:, 0] / result[:, 1]
bbox_mae = result[:, 2] / result[:, 3]
print("len: cls_rig:{}, cls_rig:{}".format(len(cls_rig), cls_rig))
print("len: bbox_mae:{}, bbox_mae:{}".format(len(bbox_mae), bbox_mae))
print("cls_rig:{}, bbox_mae:{}".format(cls_rig.mean(), bbox_mae.mean()))
torch.save(net.state_dict(), 'ssd_model.mdl')
在开始训练初期,在置信度比较高时,有时候得到的边界框可能是负数,不过训练的epoch数增加了之后就可以看见变化。
4. 模型测试
这里随便挑一张验证集的图像进行测试,输出置信度前3的边界框。
# 测试结果
def ssd_test():
imagepath = 'E:\学习\机器学习\数据集\\banana-detection\\bananas_val\images\\0.png'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
# 转换为RGB图像
lambda x: Image.open(x).convert('RGB'),
# 转换为Tensor格式
transforms.ToTensor(),
# 使数据分布在0附近
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def predict(X):
# 加载模型
net = TinySSD(num_classes=1)
net.load_state_dict(torch.load('ssd_model.mdl'))
net.eval()
# 这里测试的时候需要注意, 传入的数据不是cuda类型的,也就是不要使用GPU加速
anchors, cls_preds, bbox_preds = net(X)
print("len(anchors):{}, len(cls_preds):{}, len(bbox_preds):{}".format(len(anchors[0]), len(cls_preds[0]), len(bbox_preds[0])))
# len(anchors): 5444, len(cls_preds): 5444, len(bbox_preds): 21776
# shape: torch.Size([1, 5444, 4]) torch.Size([1, 5444, 2]) torch.Size([1, 21776])
# 利用softmax计算概率: torch.Size([1, 5444, 2]) -> torch.Size([1, 2, 5444])
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
# 使用非极大值抑制来预测边界框:torch.Size([1, 5444, 6])
# 1表示当前只传入了一张图像, 5444表示一共生成的anchor数量, 6表示anchor信息(第一列为类别,第二列为置信度, 第三到六列为边界框坐标信息)
output = multibox_detection(cls_probs, bbox_preds, anchors)
# 挑选出类别信息不为-1的索引,也就是要挑选出类别为香蕉(类别0)的anchor的索引
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
# 返回类别正确的预测anchor
return output[0, idx]
def denormalize(x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
# print(mean.shape, std.shape)
x = x_hat * std + mean
return x
def show_box(sample, axes):
# label = sample[0]
# confidence = sample[1]
bbox = sample[2:].detach().numpy() * 255
print(bbox)
rect = plt.Rectangle((bbox[0], bbox[1]), bbox[2] - bbox[0], bbox[3] - bbox[1],
fill=False, edgecolor='red', linewidth=2)
axes.add_patch(rect)
image = transform(imagepath)
# 这里获取的output为类别正确的anchor
output = predict(image.unsqueeze(0))
print(len(output), output) # [ 0.0000, 0.3077, 0.1768, -0.1711, 0.8515, 1.0493]
# 将前5个框绘制出来
fig = plt.imshow(denormalize(image).permute(1,2,0))
for i in range(3):
sample = output[i]
show_box(sample, fig.axes)
plt.show()
查看效果:

可以看见,置信度最高的anchor(0.9966)可以准确的框选出目标的,其余两个若有偏差。
[[ 0.0000, 0.9966, 0.6949, 0.2278, 0.9027, 0.4500],
[ 0.0000, 0.0728, 0.7195, 0.3263, 0.8781, 0.5081],
[ 0.0000, 0.0434, 0.6839, 0.3844, 0.8962, 0.5677],
在测试阶段的核心代码是:
output = multibox_detection(cls_probs, bbox_preds, anchors)
使用非极大值抑制来预测边界框,返回一个二维列表, 第一列表示预测类别, 第二列表置信度, 其余四列表示预测边界框的左上角与右下角。