1.AdderSR: Towards Energy Efficient Image Super-Resolution
要点1:
本文采用加法网络(AdderNet)来实现对超分辨率任务的学习,使用加法是因为加法可以避免卷积产生的大量能量损耗,用人话来说就是卷积的乘法很费劲,很耗内存,用加法可能会更快。
要点2:
要想使用加法网络超分辨的任务,必须解决两个问题:第一个问题就是直接用加法网络无法很好地学习恒等映射(identity mapping),恒等映射就是ResNet中Shortcut短连接,即h(x)=x就是个恒等映射。第二个问题就是高通滤波器不能在加法网络中保证能实现,也就是加法网络的深层提取出的特征不一定是高频信息,这一点和卷积神经网络是不同的,但对于超分辨率任务来说高频信息是十分重要的。
本文分析了加法与恒等映射的关系并添加了短连接,并且提出了一种可学习的激活函数来调整特征分布和修正细节,以此来解决上面两个问题。
要点3:
 加法网络应该有这两个属性才能实现SR任务:1.相邻层提取的对应的特征应该有相似得纹理和颜色信息;2.越深的层应该提取出越多的高频信息;
加法网络应该有这两个属性才能实现SR任务:1.相邻层提取的对应的特征应该有相似得纹理和颜色信息;2.越深的层应该提取出越多的高频信息;
总结:
本文没有在网络结构上创新,而是提出了一种新的加法网络,这个加法网络包含了一个新的可学习的能量激活函数,它可以学习类似卷积的恒等映射和高通滤波。实验表明在SR上已经可以几乎与现在的基于CNN的方法相匹敌,但是加法减少一半的浮点数运算。这个新的加法网络不仅能够用在SR上,还可以在未来去解决去噪、去模糊等问题。
2.Practical Single-Image Super-Resolution Using Look-Up Table
要点1:
本文主要想解决的是现在一些完成SR任务的深度模型再终端设备上很难实际运用的问题。本文为了解决这一问题,训练了一个小感受野的深度SR网络,在网络的后面又连接了LUT结构,让深度模型输出的值传入LUT模型中,得到一个LUT表格,在测试时就可以直接在表格中检索输出高分辨率像素。
(所谓小感受野的网络也就是层数比较浅的网络,最后得到的特征图的一个点对应原来图像的区域比较小。至于LUT是什么,以及测试时究竟怎么检索的,这些作为精读的问题可以后续再了解)
要点2:
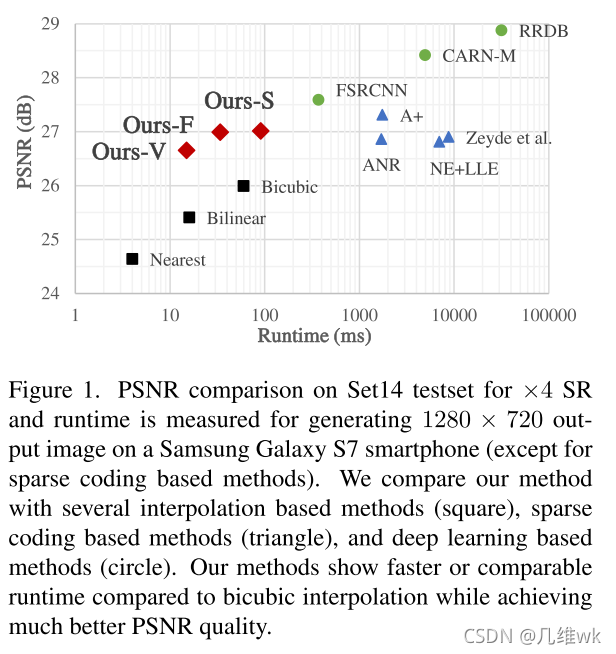 本文主要与一些注重速度的深度模型来进行比较(可能其它的模型它也比不过精度hh),从比较结果来看,他的速度还是很快的,并且和同速度的一些插值方法来比,PSNR还是比较高的。
本文主要与一些注重速度的深度模型来进行比较(可能其它的模型它也比不过精度hh),从比较结果来看,他的速度还是很快的,并且和同速度的一些插值方法来比,PSNR还是比较高的。
要点3:
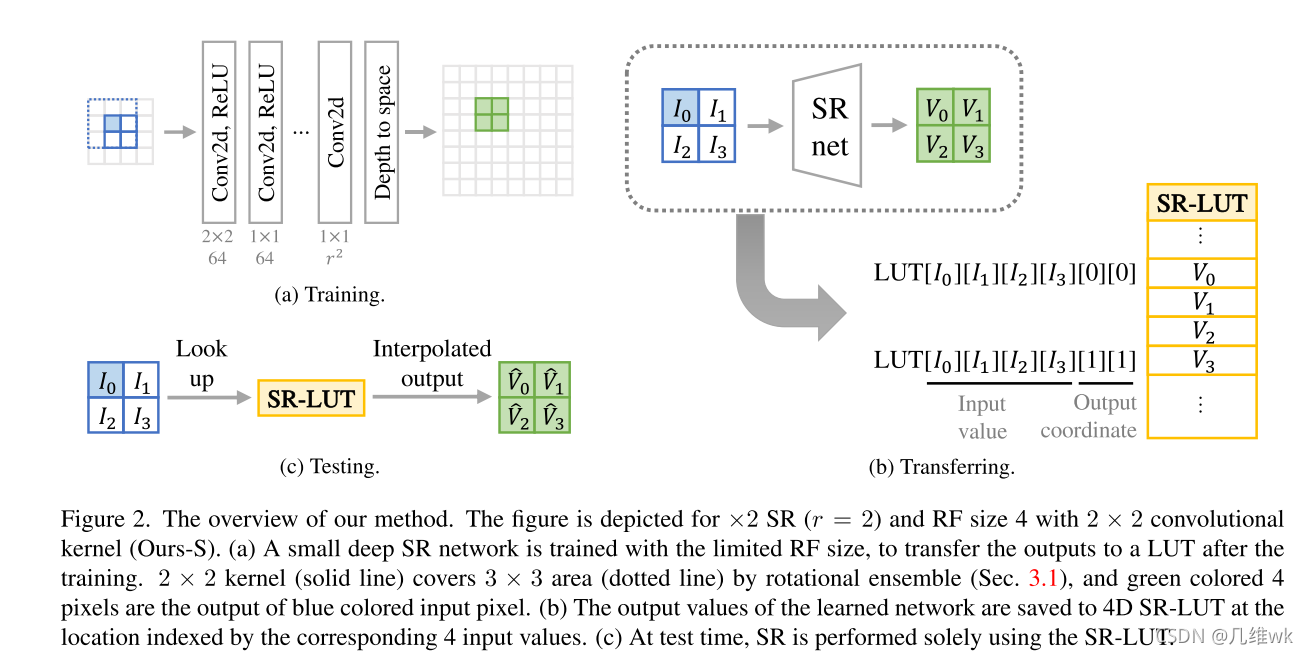
整体结构如上图,(a)部分就是前面提到的小感受野的网络;(b)部分是LUT的部分,这个SRnet在目前的略读阶段还不是很能理解,最后生成的表格就是SR-LUT;(c)部分就是测试时的过程,从图中看来测试也是需要前面的训练的网络的,所以这里也不是很懂。
总结:
本文提出了一种简单并且实用的但图像超分辨方法,与双三次插值比较有明显的优势,与其它的深度模型来比有很大的速度优势,由于速度快并且简单实现,本方法很可能在实际场景中得到广泛的应用。
3.Data-Free Knowledge Distillation For Image Super-Resolution
要点1:
本文想要解决在对CNN压缩时,训练数据难以获取导致训练困难的问题。本文通过构建一个生成器以及分级蒸馏方案来解决这一问题。
要点2:
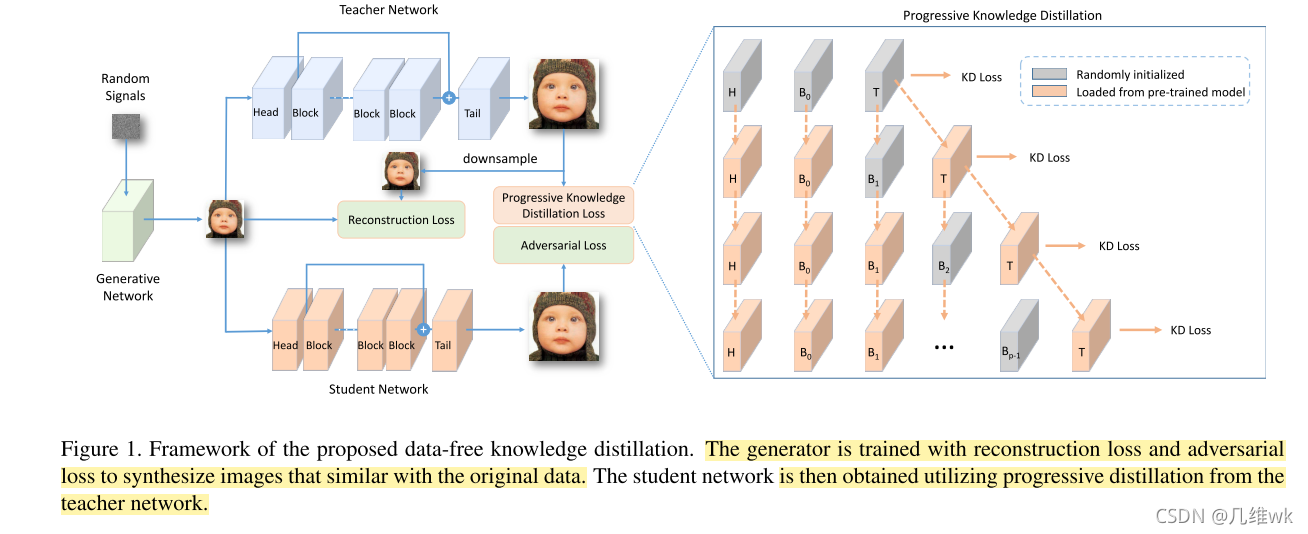
方法整体框架如上图,构建的生成器可以生成合成的数据,这个数据通过一个教师网络可以生成高分辨的图像,通过教师网络可以得到学生网络。
其中,训练这个生成器生成更好地数据的loss包括重建损失和对抗损失,重建损失是由教师网络生成的HR图像进行下采样得到的LR图像与生成的LR对比得到的,而对抗损失则是由学生网络生成的HR图像与教师网络生成的HR图像对比得到的。
知识蒸馏损失(KDloss)是用来生成学生网络的,这个损失如何计算在略读阶段还不是很懂,总之通过这个损失就能得到学生网络。
这个学生网络可以看做是简版的教师网络,它应该能够达到和教师网络类似的精度并且更加简单。
总结:
本文提出了使用重建损失和对抗损失去训练生成器生成训练数据的方法,并且提出了一种主机蒸馏策略获得计算复杂度更低的学生网络。实验证明了本文的方法可以不用训练数据就能生成超分辨率效果较好的、计算度复杂较低的学生网络。
4.SRWarp: Generalized Image Super-Resolution under Arbitrary Transformation
要点1:
本文要解决使用卷积的方法进行SR时不能重建任意尺度,只能重建整数尺度(例如x2,x3)图像的问题。本文通过提出一个SRwarp框架去完成任意尺寸的图像变换的超分辨率问题,其中提出了两种新的运算:适应弯曲层和多尺度弯曲。
要点2:
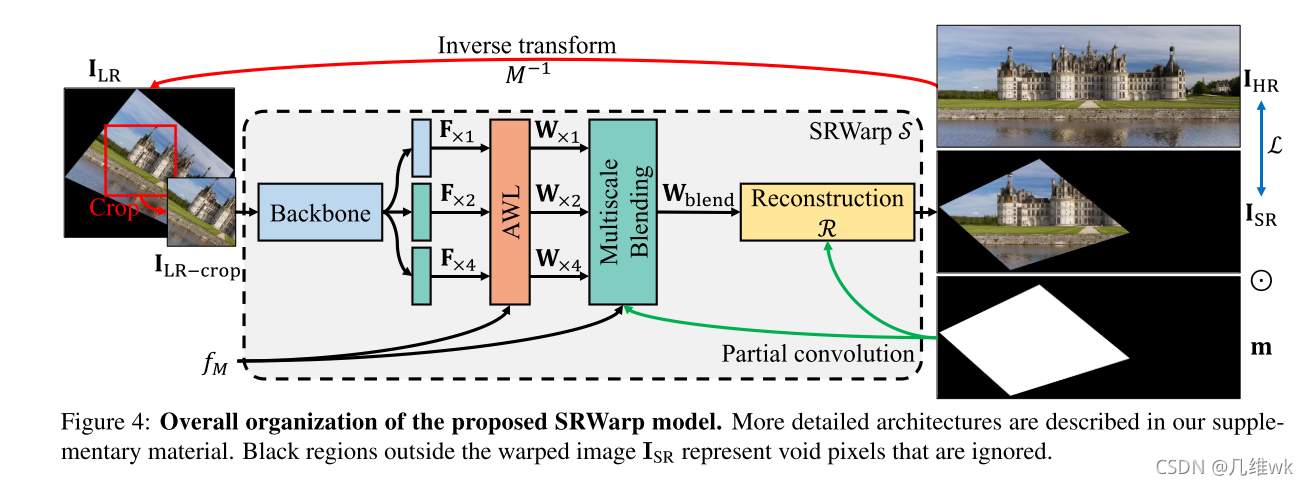
SRWarp模型的具体结构如上,这个图中的信息量特别大,有些细节还需要从论文提供的大量附加材料中了解,略读阶段暂时未能真正理解每一部分操作是如何完成的。
总结:
本文提出了一种更加普适化的卷积超分辨率任务。提出SRWarp框架完成任意尺寸的上采样任务。
5.ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
要点1:
本文着重于对SR深度模型进行加速。
加速的思想来源于:图像中有些区域比较平滑有些区域则比较粗糙(有许多纹理信息),平滑的区域比较容易进行SR,而粗糙的区域则要困难些,如果先把这些区域区分开来,对容易SR的区域采用比较简单的深度模型,对不容易SR的区域采用比较深的模型,就可以减少整体的浮点数运算提高处理速度。
基于上面的思想,本文设计了一个ClassSR框架,它能够运用在现有的一些SR深度模型上并实现很好的加速。
要点2:
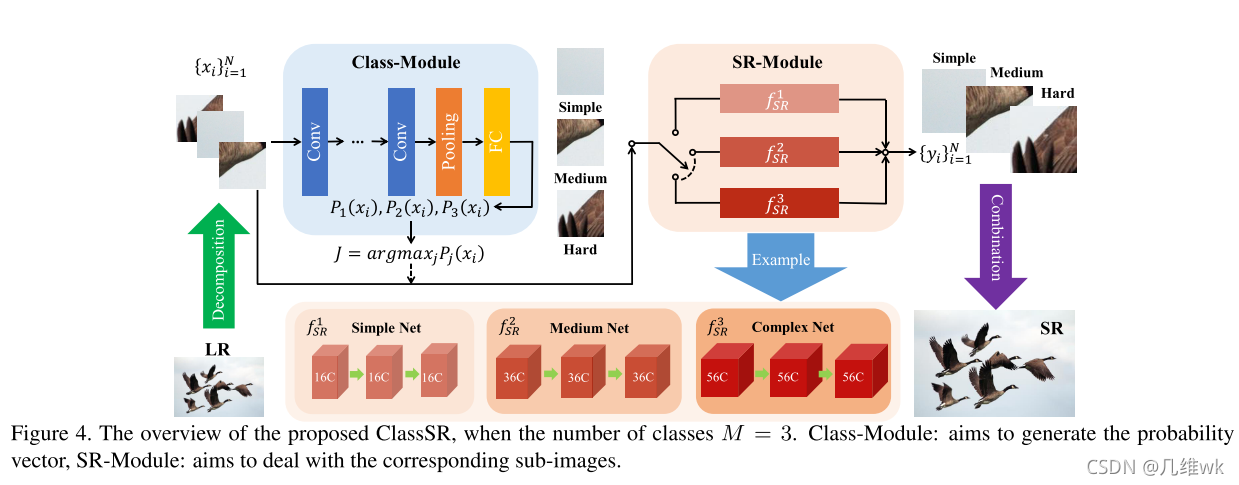
整个框架包含两个模块:分类模块和超分辨率模块,LR图像分成不同的区域块,这些区域块分别输入分类模块进行分类,根据SR难度分成简单、中等和困难三类,然后不同的类对应着不同复杂度的超分辨率网络,传入对应的网络中进行完超分辨率再组合成完整的SR图像。
要点3:
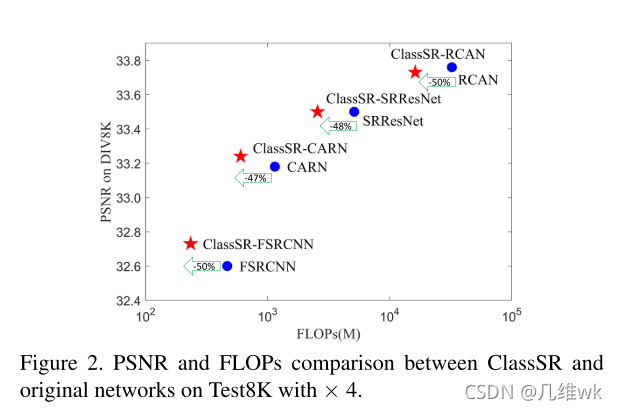
从对比图来看ClassSR能够减少模型50%左右的浮点数运算,有的甚至在减少浮点数运算的同时还提高了精度。