要点1
本文定义了一个新的任务:随机掩码图像重建任务。即随机的掩盖图像中的某些部分,然后重建出图像。
要点2
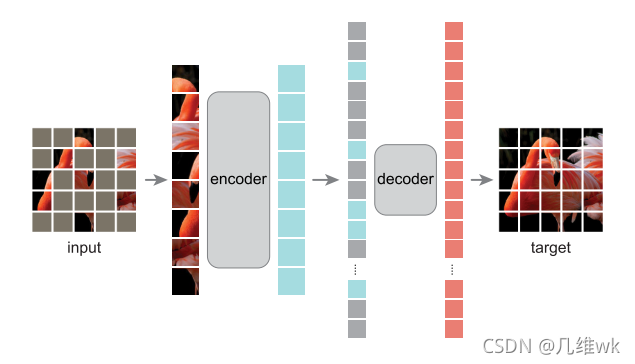
本文提出了一个掩码自编码器,用来解决随机掩码图像重建任务。该编码器是一个不对称的编码-解码器结构,将没有被掩盖的部分传入编码器进行编码,然后经过一个比较轻量级的解码器进行解码,从而实现重建任务。
要点3
作者总结说现在深度学习的方法大多数依靠不断加深模型来提高性能。在作者的研究中,在ImageNet上利用一个类似于NLP的简单方法就学到了一个强大的自编码器,这具有很强大的扩展性,让计算机视觉可能走上与NLP类似的道路。
要点4
图像和语言是不同的信号,这一点值得关注。图像仅仅记录了光的信号而不像单词能够分解成不同的语义信息。同样地,MAE重建出的像素也不是语义实体,因为作者是随机抽取的块而不是把目标抽取出来,所以与语义分割任务不同。
要点5
不同mask数量的结果展示
