1.原文链接
论文原文:Accurate Image Super-Resolution Using Very Deep Convolutional Networks
2.前言
这是一篇2016CVPR关于深度学习进行超分辨率的文章,核心思想是利用更深的网络和残差结构去完成SR任务的学习。
3.核心问题
使用更深的网络可以增加SR图像的质量,但是训练的收敛速度很慢。
本文为了进一步提高SR图像的质量引入更深的模型,为了提高训练的收敛速度引入残差学习和提高学习率。
4.整体结构
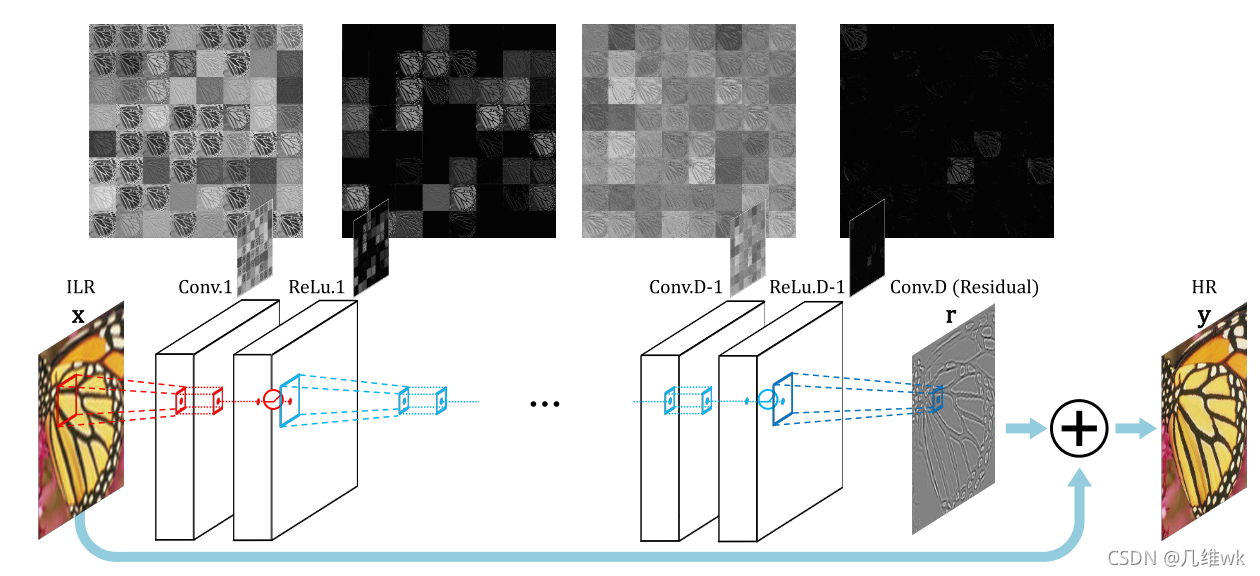
整体的结构如上图,总的来看是一个大的残差结构,主干上作者引入了20层卷积 ,采用ReLU激活。
5.训练细节
5.1 损失函数
损失函数使用的还是均方误差MSE,计算的是最终重建的图片和ground truth之间的欧式距离。
5.2 优化方法
优化使用mini-batch gradient descent(小批量梯度下降法,MBGD),设定动量(momentum)参数为0.9,增加了L2正则化项,系数为0.0001,也就是优化器中weight decay参数.
5.3 高学习率
训练深的模型收敛的速度会很慢,所以本文采用比较高的学习率,作者实验发现0.1的学习率效果最好。注意,在代码里看到的是,0.1只是初始学习率,在每10个epoch会缩小10倍。
5.4 梯度裁剪
单纯提高学习率会导致梯度爆炸或者消失问题的出现,为了限制梯度,本文采用梯度裁剪的策略,把梯度限制在一定范围。具体的做法是使用torch.nn中的一个函数直接完成的,如下:
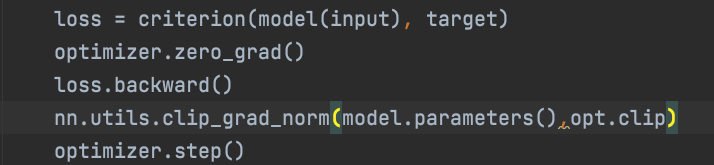
文章里默认的这个clip值应该是0.4.就把所有参数的梯度限制在-0.4到0.4之间了。
6.总结
本文提出了一个非常深的网络来完成超分辨率任务,使用残差学习和提高学习率以及梯度裁剪的方法加速网络的训练,最终获得了不错的效果。