为了复习方便 下面内容摘自PYTHON入门期末复习汇总_锴笑口常开的博客-CSDN博客_python复习

PYTHON期末复习之语法
将用一张思维导图的形式来展示python的基础语法.

PYTHON期末复习之运算符
Python语言支持以下类型的运算符:
算术运算符
比较(关系)运算符
赋值运算符
逻辑运算符
位运算符
成员运算符
身份运算符
运算符优先级

PYTHON期末复习之组合数据类型
1.列表类型(灵活可变)
列表是用中括号([])表示
直接使用list()可以生成一个空列表
list()还可以将元组和字符串转化为列表。


2.集合类型(元素类型不可重复,且是固定一种数据类型,例如整型,字符型)
集合是用大括号({})表示
set()函数可以生成集合.


3.字典类型(键值对,键(一个属性),值(属性的内容))
字典是通过大括号来表示({})以冒号连接,不同键值对通过逗号连接
大括号也可以创建一个空的字典,可以通过中括号向其增加内容.

4.元组类型(不可变序列,不能删除,不能修改)
元组用逗号和圆括号表示
使用小括号 () 或 tuple() 或直接创建,元素间用逗号分隔.
和列表类型差不多.
PYTHON期末复习之字符串类型

错题总结:
1.zip(a,b)表示[(10,93),(11,30),(12,71),(13,68)]
a = (10, 11, 12, 13)
b = (93, 30, 71, 68)
d = dict( zip(a,b) ) #打包为元组的列表,并且元素个数与最短的列表一致.zip(a,b)表示[(10,93),(11,30),(12,71),(13,68)],dict()将其转换为字典{10:93,11:30,12:71,13:68}
print( tuple(d.keys()) )#keys返回一个列表,并且提取出d中键的值放入列表中,就是(10,11,12,13),tuple将列表转换为元组.
2.排序sorted
reverse默认为false 从小到大
True为从大到小
d= {'a':24,'g':52,'i':12,'k':33}
# 以列表形式输出字典d的key
# d.items()为字典d的键值对
b1=[key for key,value in d.items()]
print(b1)
# 以列表的形式输出字典d的value
b2={value for key,value in d.items()}
print(b2)
# 颠倒字典d的key:value位置
b3={value : key for key,value in d.items()}
print(b3)
# 将字典d按value的值进行排序
b4=sorted(d.items(), key=lambda x: x[1])
print(b4)
sorted(d.items(), key=lambda x: x[1]) 中 d.items() 为待排序的对象;key=lambda x: x[1] 为对前面的对象中的第二维数据(即value)的值进行排序。 key=lambda 变量:变量[维数] 。维数可以按照自己的需要进行设置。
维数以字符串来表示
Lambda表达在Python中是作为一个匿名函数的构造器而存在。
最简单的一个Lambda表达式例子和对应的非匿名函数:
f = lambda x: x + 1
print ( f(1) )
def h (x):
return x + 1
print ( h(1) )
带有一个参数的Lambda表达式和对应的非匿名函数:
def f(n):
return lambda x: x / n
print ( f(1)(2) ) # n=1; x=2
def g(n):
return lambda x: x / n
k = g(1) # n=1
print ( (k(2)) ) # x=2
def h(x,n):
return x / n
print ( h(2,1) ) #x=2; n=1
Lambda匿名函数经常被用到filter(), map(), reduce(), sorted()函数中,这些函数的共同点是均需要函数型的参数,Lambda表达式正好适用。以sorted函数为例,其key参数指定了一个负责从带排序的list中抽取comparison key的函数。
club_ranking = [
('Arsenal', 3),
('Chelsea', 1),
('Manchester City', 2),
('Manchester United', 4),
]
club_sorted = sorted(club_ranking, key = lambda x: x[1]) # sort by ranking
print (club_sorted)
#这里的lambda x: x[1] 1指的是元组中的第二个值进行排序
'''
在Python3.4中需要使用functools将cmp函数转化为key函数
'''
import functools
club_ranking = [
('Arsenal', 3),
('Chelsea', 1),
('Manchester City', 2),
('Manchester United', 4),
]
def get_ranking( x, y ): #define cmp function
return x[1] - y[1]
club_sorted = sorted(club_ranking, key = functools.cmp_to_key(get_ranking)) # sort by ranking
print (club_sorted)
3.reversed()函数
print(sorted([1,2,3],reverse=True)==reversed([1,2,3]))
a=[1,2,3]
print(reversed([1,2,3]))
print(reversed(a))
print(sorted(a))
def print_iter(it):
for i in it:
print(i,end=' ')
print('\n')
print_iter(a)
<list_reverseiterator object at 0x7fe578127190>
<list_reverseiterator object at 0x7fe578127190>
[1, 2, 3]
1 2 3 reversed()函数从指定的sequence参数返回反向迭代器。
带序列的reversed() (reversed() with sequence)
Let’s look at reversed() function examples with standard sequence objects such as string, bytes, tuple, list etc.
让我们看一下带有标准序列对象(例如字符串, 字节 ,元组,列表等)的reversed()函数示例。
def print_iterator(it):
for x in it:
print(x, end=' ')
print('\n')
# reversed string
r = reversed('abc')
print(type(r))
print(r)
print_iterator(r)
# reversed list
r = reversed([1, 2, 3])
print_iterator(r)
# reversed tuple
r = reversed((1, 2, 3))
print_iterator(r)
# reversed bytes
r = reversed(bytes('abc', 'utf-8'))
print_iterator(r)
# reversed bytearray
r = reversed(bytearray('abc', 'utf-8'))
print_iterator(r)
<class 'reversed'>
<reversed object at 0x109d1f208>
c b a
3 2 1
3 2 1
99 98 97
99 98 97
4.enumerate()的用法
enumerate()说明
enumerate()是python的内置函数
enumerate在字典上是枚举、列举的意思
对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
enumerate多用于在for循环中得到计数
例如对于一个seq,得到:
(0, seq[0]), (1, seq[1]), (2, seq[2])
1
enumerate()返回的是一个enumerate对象,例如:
enumerate()使用
如果对一个列表,既要遍历索引又要遍历元素时,首先可以这样写:
list1 = ["这", "是", "一个", "测试"]
for index, item in enumerate(list1):
print index, item
>>>
0 这
1 是
2 一个
3 测试enumerate还可以接收第二个参数,用于指定索引起始值,如
list1 = ["这", "是", "一个", "测试"]
for index, item in enumerate(list1, 1):
print index, item
>>>
1 这
2 是
3 一个
4 测试a=[4,3,2,1]
print(list(enumerate(a)))
for i,j in enumerate(a):
print(i,j)
//[(0, 4), (1, 3), (2, 2), (3, 1)]
0 4
1 3
2 2
3 15.map函数
map(func, seq1[, seq2,…])
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。
Python函数编程中的map()函数是将func作用于seq中的每一个元素,并将所有的调用的结果作为一个list返回。如果func为None,作用同zip()。
1、当seq只有一个时,将函数func作用于这个seq的每个元素上,并得到一个新的seq。
让我们来看一下只有一个seq的时候,map()函数是如何工作的。
从上图可以看出,函数func函数会作用于seq中的每个元素,得到func(seq[n])组成的列表。下面举得例子来帮助我们更好的理解这个工作过程。
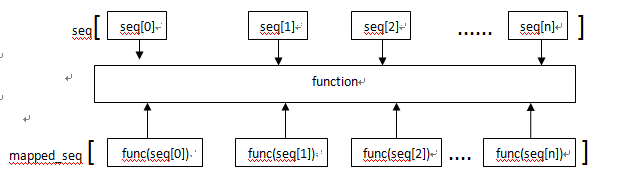
#使用lambda
>>> print map(lambda x: x % 2, range(7))
[0, 1, 0, 1, 0, 1, 0]
#使用列表解析
>>> print [x % 2 for x in range(7)]
[0, 1, 0, 1, 0, 1, 0]
一个seq时,可以使用filter()函数代替,那什么情况不能代替呢?
2、当seq多于一个时,map可以并行(注意是并行)地对每个seq执行如下图所示的过程:
从图可以看出,每个seq的同一位置的元素同时传入一个多元的func函数之后,得到一个返回值,并将这个返回值存放在一个列表中。下面我们看一个有多个seq的例子:
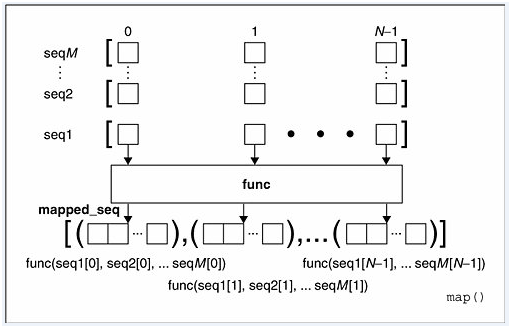
>>> print map(lambda x , y : x ** y, [2,4,6],[3,2,1])
[8, 16, 6]
如果上面我们不使用map函数,就只能使用for循环,依次对每个位置的元素调用该函数去执行。还可以使返回值是一个元组。如:
>>> print map(lambda x , y : (x ** y, x + y), [2,4,6],[3,2,1])
[(8, 5), (16, 6), (6, 7)]
当func函数时None时,这就同zip()函数了,并且zip()开始取代这个了,目的是将多个列表相同位置的元素归并到一个元组。如:
需要注意的是:
map无法处理seq长度不一致、对应位置操作数类型不一致的情况,这两种情况都会报类型错误。如下图:

3、使用map()函数可以实现将其他类型的数转换成list,但是这种转换也是有类型限制的,具体什么类型限制,在以后的学习中慢慢摸索吧。这里给出几个能转换的例子:
***将元组转换成list***
>>> map(int, (1,2,3))
[1, 2, 3]
***将字符串转换成list***
>>> map(int, '1234')
[1, 2, 3, 4]
***提取字典的key,并将结果存放在一个list中***
>>> map(int, {1:2,2:3,3:4})
[1, 2, 3]
***字符串转换成元组,并将结果以列表的形式返回***
>>> map(tuple, 'agdf')
[('a',), ('g',), ('d',), ('f',)]
#将小写转成大写
def u_to_l (s):
return s.upper()
print map(u_to_l,'asdfd')
a=[1,2,3]
b=['a','b','c']
print(list(zip(a,b)))
print(map(str,a))
print(list(map(int,a)))
print(list(map(str,a)))
print(list(map(lambda x:x%2,range(7))))
print(list(map(lambda x:x+1,range(7))))
print(list(x%2 for x in range(7)))
print(list(map(lambda x,y:x**y,[2,2],[2,3])))
# [(1, 'a'), (2, 'b'), (3, 'c')]
# <map object at 0x7ffcd024c4f0>
# [1, 2, 3]
# ['1', '2', '3']
# [0, 1, 0, 1, 0, 1, 0]
# [1, 2, 3, 4, 5, 6, 7]
# [0, 1, 0, 1, 0, 1, 0]
# [4, 8]6.filter
filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个序列,函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新的序列Iterator。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
a=[1,2,3,4,5,6,7]
def check(x):
if(x%2==0):
return 1
else :
return 0
print(filter(check,a))
print(list(filter(check,a)))
# <filter object at 0x7f895824c4f0>
# [2, 4, 6]
import math
def is_sqr(x):
r = int(math.sqrt(x))
return r * r == x
t = filter(is_sqr, range(1, 101))
print(list(t))
#输出结果
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
7..join()函数的运用
这个函数展开来写应该是str.join(item),join函数是一个字符串操作函数
str表示字符串(字符),item表示一个成员,注意括号里必须只能有一个成员,比如','.join('a','b')这种写法是行不通的
举个例子:
','.join('abc')
join()函数
语法: ‘sep’.join(seq)
参数说明:
sep:分隔符,可以为空。
seq:要连接的元素序列、字符串、元组、字典。
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串。
返回值:返回一个以分隔符sep连接各个元素后生成的字符串。
#对序列进行操作(分别使用' '与':'作为分隔符)
>>> seq1 = ['hello','good','boy','doiido']
>>> print ' '.join(seq1)
hello good boy doiido
>>> print ':'.join(seq1)
hello:good:boy:doiido
#对字符串进行操作
>>> seq2 = "hello good boy doiido"
>>> print ':'.join(seq2)
h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o
#对元组进行操作
>>> seq3 = ('hello','good','boy','doiido')
>>> print ':'.join(seq3)
hello:good:boy:doiido
#对字典进行操作
>>> seq4 = {'hello':1,'good':2,'boy':3,'doiido':4}
>>> print ':'.join(seq4)
boy:good:doiido:hello
#合并目录
>>> import os
>>> os.path.join('/hello/','good/boy/','doiido')
'/hello/good/boy/doiido'注意:里面的元素必须是str类型
8.eval函数
eval(str)函数很强大,官方解释为:将字符串str当成有效的表达式来求值并返回计算结果。所以,结合math当成一个计算器很好用。
eval()函数常见作用有:
1、计算字符串中有效的表达式,并返回结果
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> eval("n + 4")
85
2、将字符串转成相应的对象(如list、tuple、dict和string之间的转换)
>>> a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
>>> b = eval(a)
>>> b
[[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]]
>>> a = "{1:'xx',2:'yy'}"
>>> c = eval(a)
>>> c
{1: 'xx', 2: 'yy'}
>>> a = "(1,2,3,4)"
>>> d = eval(a)
>>> d
(1, 2, 3, 4)
10.set
首先我们需要知道什么可以作为集合的元素。集合对象是一组无序排列***可哈希***的值,集合成员可以做字典中的键。那么可哈希与不可哈希是什么意思呢?
简要的说可哈希的数据类型,即不可变的数据结构(字符串str、元组tuple、对象集objects);同理,不可哈希的数据类型,即可变的数据结构 (集合set,列表list,字典dict)
Python面向对象静态方法,类方法,属性方法
属性:
公有属性 (属于类,每个类一份)
普通属性 (属于对象,每个对象一份)
私有属性 (属于对象,跟普通属性相似,只是不能通过对象直接访问)
方法:(按作用)
构造方法
析构函数
方法:(按类型)
普通方法
私有方法(方法前面加两个下划线)
静态方法
类方法
属性方法
静态方法
@staticmethod
静态方法,通过类直接调用,不需要创建对象,不会隐式传递self
class Dog(object):
@staticmethod
def run():
# 不需要访问类属性和实例属性的方法,就可以定义一个静态方法
print("跳着跑")
def __init__(self, name):
self.name = name
def bark(self):
pass
# 通过 类名. 调用静态方法,不需要创建对象
Dog.run()
类方法
@classmethod
类方法,方法中的self是类本身,调用方法时传的值也必须是类的公有属性,
就是说类方法只能操作类本身的公有字段
class Plant(object):
# 使用赋值语句定义类属性,记录所有植物对象的数量
count = 0
# 定义一个类方法
@classmethod
def show_count(cls):
print("目前已养植物种类数量:", Plant.count)
def __init__(self, name):
self.name = name
Plant.count += 1
duorou = Plant("多肉")
luhui = Plant("芦荟")
# 调用类方法
Plant.show_count() # 目前已养植物种类数量: 2
10 yield 和 return 对比分析
相同点:都是返回函数执行的结果
不同点:return 在返回结果后结束函数的运行,而yield 则是让函数变成一个生成器,生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
例子:求一组数的平方值
return 实现:
def squre(n):
ls = [i*i for i in range(n)]
return ls
for i in squre(5):
print(i, end=' ')
0 1 4 9 16
yield 实现:
def squre(n):
for i in range(n):
yield i*i
for i in squre(5):
print(i, end=' ')
yield 生成器相比 return一次返回所有结果的优势:
(1)反应更迅速
(2)更节省空间
(3)使用更灵活
11.__iter__ 和 __next__
__iter__和__next__
iter()函数主要映射类中__iter__函数
next()函数主要映射类中__next__函数
class MyRange(object):
def __init__(self, end):
self.start = 0
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.start < self.end:
ret = self.start
self.start += 1
return ret
else:
raise StopIteration
m = MyRange(5)
modify(m) # Iterable, Iterator
# 利用for语句迭代元素,会捕获StopIteration异常并自动结束for
for i in m:
print(i)
# 利用next()函数迭代元素
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a)) # 其实到这里已经完成了,我们在运行一次查看异常
12.and or
print(2 and 3)
print(2 or 3)
print(2 and 3 or 4)
print(2 and 3 and 4)
print(2 or 3 or 4)
# 3
# 2
# 3
# 4
# 2