1.gRPC的定义:
是一项进程间的通信技术,可以用来连接、调用、操作和调试分布式异构应用程序。功能如同其他RPC的框架一样。
2.那么什么是rpc?
– 像调用本地方法一样调用远程方法。
RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务,一个进程到进程之间的调用。
其中有一个比较特殊的概念——本地过程调用,通信模型是调用本地,比如,咱们之前常用的,http通信一定是需要调用应用层协议的。而本地调用是封装通信过程,通过调用本地方法的形式调用远程服务器的,此时的通信的形式就远远不止http形式,还可以用tcp、udp,除此之外,序列化、压缩、认证、访问、监控、扩容都可以重构,我不是http协议的不可以实现,只是http很多时候是对外的,这些工作可能要暴露在外,或者是需要增加不同的插件完成,研发成本也会比较高。这是自己的理解一点。
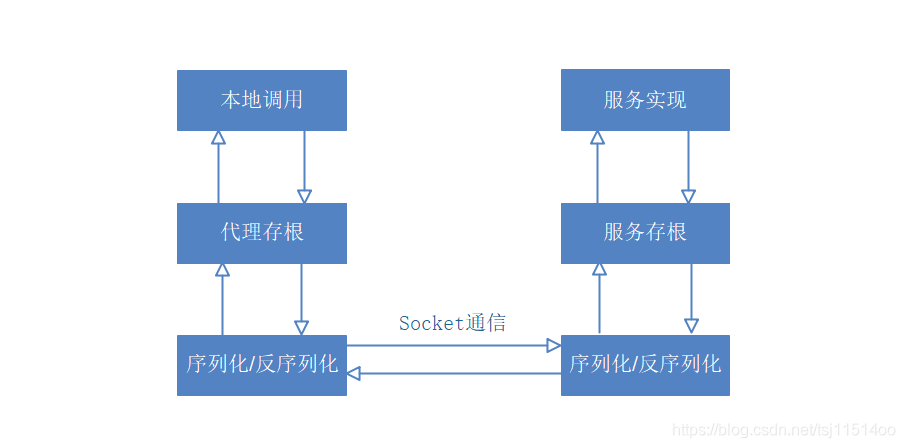
3.RPC的核心
- 核心目标:主要是解决分布式系统中服务之间的调用问题。
- 主要解决远程通信间的问题,不需要了解底层网络的通信机制。
- RPC框架负责屏蔽底层的传输方式(TCP或者UDP)、序列化方式、以及通信细节。
- 实际使用中,并不需要关心底层通信细节和调用过程,让业务端专注于业务代码的实现。
4.RPC的设计过程
针对RPC目标和核心,设计理念我们应该怎么构思出一个RPC的框架。
4.1.动态代理
首先,如何获取一个远程接口,如何像调用本地方法一样调用远程方法。
可以基于动态代理来完成,你面向接口获取到一个代理对象,这个代理对象就是接口在本地的一个代理,然后这个代理就会找到服务对应的机器。(RPC的核心是代理)
4.2.socket通信
那么,是如何找到远程机器的,这就涉及到网络通信了,一般通信我们常用的就是http tcp udp。
4层,传输层用tcp、udp,udp不可靠,设计数据包的完整可靠就直接淘汰udp。
7层,应用层用http,7层依赖于4层,直接用4层协议比较快。so,tcp会比http高效一点。那么后面通信协议就针对tcp来设计。
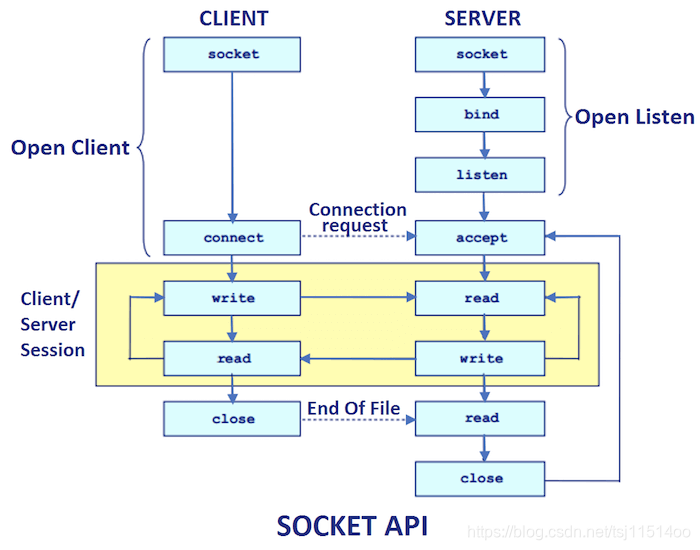
那,tcp和客户端和服务做之间做了一些什么工作呢?
首先是通信,服务之间的通信可以理解是端到端的通信,tcp是通过Socket完成的。通过一张图复习一下socket的通信过程。
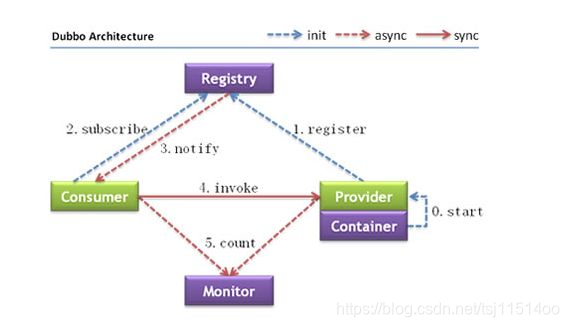
(1)服务注册与发现的引入
Socket为了可靠性设计成一个四元组,即自己IP+端口和对方地址IP+对方的端口,那我们是自己知道自己IP和端口,那么如何知道对方的ip和端口呢?是不是服务之间需要交换一个信息表,类似路由表的功能,那就可以通过服务注册和发现的机制帮我完成这个本地存有信息表的功能,能动态感知服务路由表的,这就可以引入——服务注册与发现的概念,通过一个注册中心来完成动态路由的功能,同时也能做服务健康探测、动态上线、监控的一些工作。
怎么选择注册中心,这里先不聊,各公司选型不一样,可以参考cap、base等原则来选型,中间件列举几个:Zookeeper、Etcd、Consul、Nacos。
注册中心的核心工作就是Registry,以zk为例,zk是一个目录型的,rpc主动注册和服务发现主要是生成一个目录结构和节点数据,
目录结构大概举个例子:根(rpc) + “/” +interfaceGroup+ “/” + interfaceName + “/” + interfaceVersion + “/” + hostAndPort。
节点数据:编码后的URL数据。
借用dubbo的register中心展示一下zk的原理+观察者模式的应用。
(2)序列化和反序列的技术引入
ok,我们在有这个套接字之后,是不是开始要传输了,
那么我们在传输的时候,服务器之间二进制传输的,是不是要把我的object对象这种字符流转化为字节流。那就设计到一个序列化和反序列化的问题。
我们复习一下序列化相关概念

-
1.什么是序列化和反序列
序列化: 将数据结构或对象转换成二进制串的过程
反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程 -
2.为什么要序列化?好处在哪里?
(1) 将对象存储于硬盘上 ,便于以后反序列化使用
(2)在网络上传送对象的字节序列 -
3.序列化和反序列化选型工作,要注意几点:
(1).通用性
第一、技术层面,序列化协议是否支持跨平台、跨语言。如果不支持,在技术层面上的通用性就大大降低了。
第二、流行程度,序列化和反序列化需要多方参与,很少人使用的协议往往意味着昂贵的学习成本;另一方面,流行度低的协议,往往缺乏稳定而成熟的跨语言、跨平台的公共包。
(2).性能
时间复杂度和空间复杂度
(3).强健性
是否支持被序列化对象新旧版本的兼容性问题。这个需求在实际开发中经常遇到,比如发布了一个服务,有很多客户端使用。当服务需要修改,新 添加1个参数时,不可能要求所有客户端都更新,那样牵扯的面太大,所以要做到新旧版本的兼容
(4).是否可以直接序列化对象,而不需要额外的辅助类,比如用IDL生成辅助的序列化类 -
4.序列化代表:
- 语言原生的序列化,RMI,Remoting
- 二进制平台无关,Hessian,avro,kyro,fst等
- 文本,JSON、XML等
(3)IO模型框架的引入
Socket 网络通信过程可以归纳为,bind-listen-accept-网卡-dma数据拷贝-cpu拷贝-application应用,其中涉及的accept、read、write工作就是IO的工作。这个过程比较优点复杂。前置知识是你需要了解一些BIO、NIO的概念。其中RPC就是大量应用了多路复用的概念。这里展开说可能就是比较长。简单说一下RPC的IO应用。
说IO就要从他的发展,java、linux之前IO模型是同步阻塞的 BIO 模型。
BIO的ServerSocket 的 accept() 方法是阻塞方法,也就是说 ServerSocket 在调用 accept()等待客户端的连接请求时会阻塞,直到收到客户端发送的连接请求才会继续往下执行代码,因此我们需要要为每个 Socket 连接开启一个线程(可以通过线程池来做)。
另外还有一个阻塞的方式操作系统的systemcall,也是阻塞。
为了解决上述的问题,Java 1.4 中引入了 NIO ,一种同步非阻塞的 I/O 模型——NIO。
nio 提供了 Channel , Selector,Buffer 等抽象。
NIO 支持面向缓冲(Buffer)的,基于通道(Channel)的 I/O 操作方法。
NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。
Selector(选择器,也可以理解为多路复用器)是 NIO(非阻塞 IO)实现的关键。它使用了事件通知相关的 API 来实现选择已经就绪也就是能够进行 I/O 相关的操作的任务的能力。
NIO的框架代表就是Netty、mina。
4.3.其他
-
在tcp通信的时候,还有什么问题
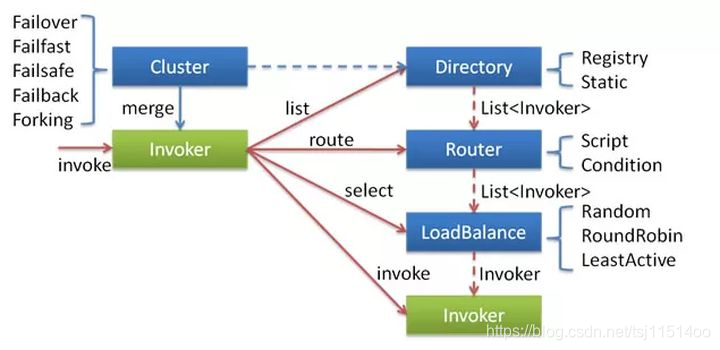
刚才说的的都是单机服务,但是为了HA就需要集群部署。集群涉及一下几个概念。 -
怎么选 就是复制均衡的问题
-
失败后怎么办? 就设计到容错、重试。
-
高并发的调用怎么办?限流、熔断
-
幂等性问题?
-
监控-monitor
-
TCP四次挥手时产生的TIME_WAIT或CLOSE_WAIT,造成死链。或者服务器A<->路由器B<->路由器C<->客户端D,链路中的路由器发生了故障,造成死链。需要采取定时器/心跳检测来清理死链。