mapreduce的限制
适合“一趟”计算操作
很难组合和嵌套操作符号
无法表示迭代操作
========
由于复制、序列化和磁盘IO导致mapreduce慢
复杂的应用、流计算、内部查询都因为maprecude缺少有效的数据共享而变慢
======
迭代操作每一次复制都需要磁盘IO
内部查询和在线处理都需要磁盘IO
========spark的目标
在内存中保存更多的数据来提升性能
扩展maprecude模型来更好支持两个常见的分析应用:1,迭代算法(机器学习、图)2,内部数据挖掘
增强可编码性:1,多api库,2更少的代码
======
spark组成
spark sql,spark straming(real-time),graphx,mllib(meachine learning)
======
可以使用一下几种模式来运行:
在它的standalone cluster mode下
在hadoop yarn
在apache mesos
在kubernetes
活着在云上面
==========
数据来源:
1,本地文件file:///opt/httpd/logs/access_log
2,amazon S3
3,hadooop distributed filesystem
4,hbase,cassandra,etc
===========
spark 集群cluster
============
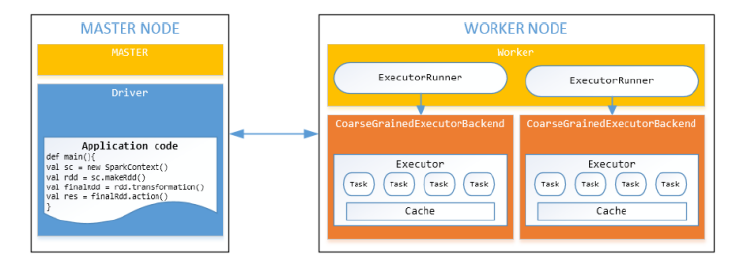
spark workflow
首先产生一个SparkContext对象(1,告诉spark怎么并且在哪里去访问集群;2,连接不同类型的集群管理者,egYARN,Mesos,本身的)
然后使用集群管理分配资源
最后使用Spark executer来运行计算过程,读取数据块
==============
workers节点和执行者
worker节点是能运行executors的机器(1,每个worker一个jvm或者一个process,2每个worker可以产生多个executor)
Executor可以运行任务(1,在子jvm中运行,2在一个线程池中执行一个或者多个任务)
=========
Solution: Resilient Distributed Datasets
弹性分布式数据集
=========
RDD 操作
transformation:返回一个新的RDD,function包括:map,filter,flatMap,groupByKey,reduceByKey,aggragateByKey,filter,join
action:评估并且返回一个新的value,当一个RDD对象调用action方法时,处理查询的所有数据都会被同时计算,结果值返回;方法包括
reduce,collect,count,first,take,countByKey,foreach,saveAsTextFile
============
怎么使用RDD
1,从data source中产生一个RDD(1,利用现存的集合lists,arrays;2,RDD的变换;3,从hdfs或者其他数据系统)
2,使用RDD变换
3,使用RDD操作
=======
产生一个RDD
从hdfs,textfiles,amazons S3,hbase,序列号文件,其他的hadoop输入格式
(//从文件中产生一个RDD
JavaRDD<String> distFile = sc.textFile("data.txt",4)//rdd分为4个部分
)
(//从集合创建RDD
list<Integer> data = Arrays.aslist(1,2,3,4,5);
JavaRDD<Integer> distData = sc.parallelize(data);
)
========