nosql概念简述
nosql英文全称是not only sql,即不仅仅是非关系型数据库之意,nosql存储也并非像关系型数据库那样依赖业务逻辑方式存储,nosql存储方式是很简单的sql存储。
什么是redis
总所周知,总内存中读取速度远远大于从磁盘中读取。所以如果能够将重要且查询频繁的数据放在内存中是非常不错的选择。
由此memcache就应运而生了,memcache就是一种nosql数据库,数据都存储在内存中,但是缺点也很明显,由于数据只能在内存中存储,一旦关机那么数据都将丢失,且memcache存储类型也十分单一,所以开发者们就开始想着有没有更好的解决方案呢?
redis就是最新的解决方案,他拥有memcache所有的所有功能,且支持数据持久化,以及存储数据结构多样。
redis安装
安装C 语言的编译环境
yum install centos-release-scl scl-utils-build
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
完成之后设置gcc版本
gcc --version
下载redis-6.2.1.tar.gz放/opt目录
解压命令:tar -zxvf redis-6.2.1.tar.gz
解压完成后进入目录:cd redis-6.2.1
键入make
注意:2.2.2.6.如果没有准备好C语言编译环境,make 会报错—Jemalloc/jemalloc.h:没有那个文件,可以运行make distclean,再次运行make即可解决问题
运行make install
小结
自此,redis安装已经全部完成,redis会被默认安装在/usr/local/bin目录,所以为了方便后续各种操作,我们可以运行如下命令,创建一个redis配置目录方便后续各种实验操作
# 创建配置文件实验文件夹
mkdir myredis
进入redis解压目录
cd /opt/redis-6.2.1/
复制配置文件到新文件夹
cp redis.conf /myredis/
# 进入redis命令目录
cd /usr/local/bin/
启动
前台启动
一旦按ctrl+c进程直接结束
redis-server /myredis/redis.conf
后台启动(推荐)
运行一下命令配置文件
vim /myredis/redis.conf
按/daemonize找到daemonize,将此参数设置为yes,如下图所示
启动
# 启动redis
/usr/local/bin/redis-server /myredis/redis.conf
# 检查redis是否启动
ps -ef|grep redis
启动客户端
/usr/local/bin/redis-cli
cli键入ping
若输出PONG,则说明redis客户端已经与服务端连通。
关闭服务端
- 客户端运行
shutdown /usr/local/bin/redis-cli -p 6379 shutdown
redis基础数据结构操作
String
String是redis最基础的存储类型,是二进制安全的所以可存储图片或者二进制对象,一个redis最大可以存储512M。
常用命令
添加键值对
set <key><value>
#setNX:当数据库中key不存在时,可以将key-value添加数据库
#setXX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
#setEX:key的超时秒数
#setPX:key的超时毫秒数,与EX互斥
查询对应键值
get <key>
将给定的 追加到原值的末尾
append <key> <value>
获得值的长度
strlen <key>
将 key 中储存的数字值增1,注意只能对数字值操作,如果为空,新增值为1
incr <key>
将 key 中储存的数字值减1,只能对数字值操作,如果为空,新增值为-1
decr <key>
List
简介
list底层是双向队列,所以list对两端操作速度较快,但涉及中间节点操作的画,会相对慢一些。
需要了解的是这种数据结构在数据量较好的时候是以ziplist进行存储,ziplist是一块连续的内存存储单元,但数据量到一定程度之后就会编程quicklist。quicklist如下图所示,即使用前驱节点和后继节点连接无数个ziplist。

常用命令
从左边/右边插入一个或多个值。
lpush/rpush <key> <value1> <value2> <value3> ....
从左边/右边弹出一个值。
lpop/rpop <key>
从列表右边弹出一个值,插到列表左边。
rpoplpush <key1> <key2>
按照索引下标获得元素(从左到右)
lrange <key><start><stop>
lrange mylist 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
按照索引下标获得元素(从左到右)
lindex <key><index>
获得列表长度
llen <key>
在的后面插入插入值
linsert <key> before <value> <newvalue>
从左边删除n个value(从左到右)
lrem <key><n><value>
将列表key下标为index的值替换成value
lset <key> <index> <value>
Set
简介
redis中的set与java中的hashset一样,即没有value的hashMap。
常用命令
将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
sadd <key><value1><value2> .....
取出该集合的所有值
smembers <key>
判断集合是否为含有该值,有1,没有0
sismember <key> <value>
返回该集合的元素个数。
scard<key>
删除集合中的某个元素。
srem <key> <value1> <value2> ....
随机从该集合中吐出一个值
spop <key>
随机从该集合中取出n个值。不会从集合中删除
srandmember <key> <n>
把集合中一个值从一个集合移动到另一个集合
smove <source> <destination> <value>
返回两个集合的交集元素。
sinter <key1> <key2>
返回两个集合的并集元素。
sunion <key1> <key2>
返回两个集合的差集元素(key1中的,不包含key2中的)
sdiff <key1> <key2>
Hash
简介
相当于java中Map,当数据量较小时,存储使用的是ziplist,当数据量达到一定程度时用的是hashtable。
常用命令
给集合中的 键赋值
hset <key> <field> <value>
从集合取出 value
hget <key1> <field>
批量设置hash的值
hmset <key1><field1><value1><field2><value2>...
查看哈希表 key 中,给定域 field 是否存在。
hexists <key1> <field>
列出该hash集合的所有field
hkeys <key>
列出该hash集合的所有value
hvals <key>
为哈希表 key 中的域 field 的值加上增量 1 -1
hincrby <key> <field> <increment>
将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
hsetnx <key> <field> <value>
Zset
简介
与set差不多,但是zset的每个成员都会多一个score,这个score用于对集合排序,所以使用zset可以使你拥有一个不重复但是score可以重复的不同成员的列表。
其底层实现也很精妙,通过hash的key来保证value唯一,用hash的value存储score。
然后使用跳表通过score给这些数据排序,保证查询速度。
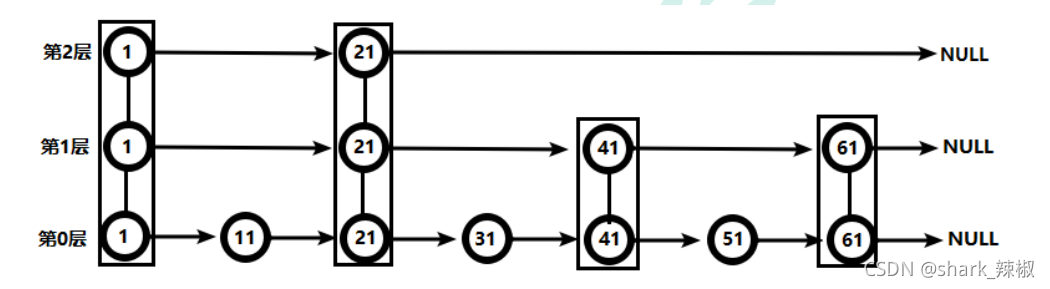
这里以一个简单的场景介绍一下跳表。
如下图所示,若以链表存储以下数据结构,查询51需要6次。

而跳表如下图所示,最上层2^0 , 往下2^1 , 再往下2^2。使用这样的结构间隔间隔的存储key值。
以下图为例:
- 最上层看到第一个节点为1,小于51,继续往后。
- 往后是21,还是太小继续往后,找不到,于是往下层找。
- 下一层后一个节点是41,小于51。
- 于是往后发现大于61,继续往下。这时就发现51查找只需4次。
常用命令
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zadd <key> <score1> <value1> <score2> <value2>…
返回有序集 key 中,下标在
之间的元素带WITHSCORES,可以让分数一起和值返回到结果集。
zrange <key><start><stop> [WITHSCORES]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrangebyscore key minmax [withscores] [limit offset count]
同上,改为从大到小排列。
zrevrangebyscore key maxmin [withscores] [limit offset count]
为元素的score加上增量
zincrby <key><increment><value>
删除该集合下,指定值的元素
zrem <key> <value>
统计该集合,分数区间内的元素个数
zcount <key> <min> <max>
返回该值在集合中的排名,从0开始。
zrank <key> <value>