DeepIrisNet2: Learning Deep-IrisCodes from Scratch for Segmentation-Robust Visible Wavelength and Near Infrared Iris Recognition
深度irisnet2:从零开始学习深层虹膜图像分割鲁棒可见光和近红外虹膜识别 2019年 作者: Abhishek Gangwar
from Scratch 从0开始的意思
Abstract :
首先,我们介绍了一个名为DeepIrisNet2的基于深度学习的框架,用于可见光谱和近红外虹膜表示。该框架不需要经典的虹膜归一化步骤,也不需要非常精确的虹膜分割;允许在非理想的情况下工作。该框架包含空间转换层,在特定的中间层后以处理变形和监督分支,以减轻过拟合。此外,我们提出了一个双CNN虹膜分割管道,包括虹膜/瞳孔边界盒检测网络和语义像素分割网络。此外,为了得到紧凑的模板,我们提出了使用DeepIrisNet2生成二值虹膜码的策略。由于没有ground truth数据集用于CNN训练虹膜分割,我们构建了大规模的手标数据集并公开;i)虹膜,瞳孔边框,ii)标记虹膜纹理。该网络在具有挑战性的ND-IRIS-0405, UBIRIS上进行评估。v2, michei,和CASIA v4 interval数据集。所提出的方法显著地改进了现有的技术(the state-of-the-art ),并取得了优于之前所有方法的优异性能
- Introduction
近年来,非理想虹膜的虹膜识别对于在较少的环境约束条件下,从远距离和较少的用户合作下进行虹膜识别具有重要意义。随着这一趋势,各种各样的选择被探索,如可见光光谱虹膜识别(VS)和手机设备虹膜识别等。可见光光谱虹膜识别的主要优点是,相对于近红外光下的固定距离成像,它可以在移动和远距离情况下成像。众所周知的挑战如噪声虹膜挑战评估(Noisy Iris Challenge Evaluation )NICE I, II)虹膜生物识别比赛Iris biometrics competition [2]和移动虹膜挑战评估Mobile Iris CHallenge Evaluation(MICHE I, II)[6]重申了人们对可见光谱虹膜识别日益增长的兴趣。此外,最近的手机也有了与专用数码相机同等成像能力的摄像头,这使得它们能够进行虹膜识别。移动电话设备上的生物识别认证将扩大传统生物识别系统的功能和能力。(可见光下的虹膜识别和传统的红外识别。)
本文的重点是提出一个虹膜识别框架,以突破现有虹膜识别系统的实际的限制。特别地,我们提出了一种新的和鲁棒的基于深度CNN的虹膜识别框架,可以有效地工作在无约束的近红外或可见光谱虹膜采集。由于图像捕获的不受约束的特点,改图像对虹膜的精确分割产生了挑战,很可能没有清晰的虹膜纹理用于识别。为了回答这些问题,提出了框架介绍)本文提出了一种高度容忍分割误差的虹膜识别框架,并证明了在不使用传统的Daugman橡胶片模型进行虹膜归一化的情况下,可以实现高精度的虹膜识别3],2)一个新的基于深CNN的架构称为DeepIrisNet2为了提取虹膜纹理表示有效和紧凑的虹膜特征。
本文的主要贡献可以总结如下:
1:我们首先提出了一个简单而有效的监督学习框架,名为DeepIrisNet2,以获得高度有效的虹膜表示,这样虹膜对光照、尺度和仿射变换具有不变性。所提议的CNN是从头开始训练的,我们提供了关于训练超参数的广泛细节,以及他们的直觉选择,以发布完全可复制的CNN虹膜识别。
2.与传统的虹膜识别系统不同,提出的DeepIrisNet2直接使用rectilinear虹膜图像进行训练,而没有使用Daugman的橡胶板模型进行归一化,将直角坐标系转换为极坐标。
3:提出了一种新的基于双CNN的虹膜分割框架。第一阶段CNN检测虹膜和瞳孔边界盒,第二阶段CNN将边界盒检测到的区域作为输入,进行语义像素分割,得到真实的虹膜区域。该过程减少了计算量,并减轻了遮挡和其他噪声的影响。
4:我们建立了一个大规模的手工标记数据集,名为虹膜检测和分割Groundtruth数据库(IrisDSGD)由;虹膜标注,瞳孔边框,虹膜区域像素级标注。该数据集用于训练和评估我们的分割网。这个数据集将会被公开,这可能会吸引更多的研究小组进入这个领域。
5.我们提出了一种从DeepIrisNet2生成紧凑的二进制虹膜模板(Deep-IrisCodes)的方法。我们提出了从公共虹膜数据集创建大规模训练数据来训练DeepIrisNet2的方法。我们评估我们的方法具有挑战性的场景,如虹膜识别在可见光谱和移动电话环境下。我们总结实验,并证明提出的框架优于所有最先进的工作,在公共数据集;UBIRIS v2.0, ND-0405, MICHE-1, CASIA Interval v4。
本文的其余部分组织如下。相关的工作在第2节中给出。第3节解释了提出的虹膜分割CNN网。第4节讨论数据集,第5节讨论空间转化(ST)模块。第6节给出DeepIrisNet2网络的细节,第7节给出实验,第8节给出结论。 - Related Work
1993年,Daugman[3]提出了第一个完整的自动虹膜识别系统。他提出了一种基于归一化虹膜区域提取量化Gabor相位信息的IrisCode生成方法。在Daugman和Wildes[24]的开拓性工作的基础上,许多研究者提出了各种用于虹膜识别的特征提取方法,可分为:基于-纹理分析的[27]、强度变化分析的[28]、基于相位的[3]、零交叉[24]等。一些研究者还探索了特征提取方法和相应的虹膜识别系统,不依赖于虹膜模式到极坐标的变换,也不依赖于高度精确的分割[16,17,18,25],使得在图像采集条件不受约束的情况下,虹膜识别可行。这些方法基本上都是基于在尺度空间中寻找极值点,并对极值点进行滤波得到稳定点,然后提取这些稳定点周围的图像局部特征,并根据这些局部特征生成局部描述符进行匹配。但是,如果虹膜中没有提取足够的特征点或者没有正确地排除噪声点,识别性能会下降。
**一些虹膜识别方法在低级手工特征的基础上进一步学习高级特征[7,26,29],以获得更好的准确性。**虽然局部滤波器的参数是手工制作的,但我们可以粗略地将这些方法看作是一个两层模型。基于手工制作的过滤器的更深入的模型(#layers > 3)在文献中很少被报道。因为每个层的过滤器(或参数)是通常是手工独立设计的,而且层之间的动态很难通过人工观察处理。因此,从数据中学习各层的参数是最好的方法。(也就是说传统的人工设计的特征提取方法,也就是相对于一层模型,要是这样的模型多了,每层都是设计的,这样很难衔接每一层,目的性太强,这样算法不好。)
尽管cnn在很久以前就被提出了,但在过去的三年里已经取得了相当大的进展。由于深卷积神经网络在计算机视觉方面取得了突破性的成果,也有一些研究工作[1,42,43]也在虹膜识别任务中尝试了深度学习方法,有报道称虹膜识别准确率有显著提高。 - Proposed Iris Segmentation Methodology、
3.1. Bounding Box Detection Network
提出的虹膜边界盒检测CNN的灵感是你只看一次(YOLO)架构[5]。原来的YOLO网络包含24个卷积层和2个完全连接的层。但是,针对我们的问题,我们对网络进行了一些修改,并找到了一个更小、更高效的网络,如表3所示。我们的网络由18个conv. layer (CONV1 to CONV18)和3个完全连接的layer (FC1 to FC3)组成。添加FC1是为了通过减少对输入的采样来进一步减少参数的数量。·
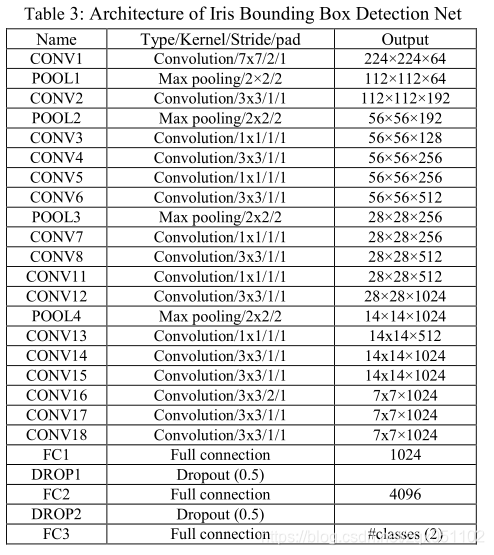
YOLO的方法是非常简单和快速的,因为与基于区域建议region proposal或滑动窗口的方法不同,它在训练和测试时使用了来自完整图像的特征。YOLO直接回归到边界盒位置和类概率。YOLO将每幅图像分成W-by-W区域,然后从每个区域直接回归,找到K个目标边界盒,并对N个类中的每一个分类打分。每个边界盒回归5个数字;这些是中心x,中心y,宽度,高度和边界框的置信度。一个区域中的所有边界框将拥有一组类分数N。因此,对于每幅图像,网络的输出是一个W×W×(5K+N)的向量。与原来的YOLO不同,我们的网络是针对2类问题(iris和瞳孔)进行训练的;N=2 W=11 K=2。最终的预测量为11×11×12=1452张量。我们首先在Imagenet数据集[34]上预先训练了一个网络。(在imagenet上训练分割,然后用这个权重去测试虹膜图像)利用预训练模型的权值,分别对红外和红外虹膜图像进行虹膜目标检测。使用我们的ground-truth 数据集进行训练;IrisDSGDBBox_VS和IrisDSGD-BBox_NIR(第4.1节)。(作者他们做的模板数据库)输入图像的大小被调整为448×448像素。在每种情况下,80%的图像用于训练,5%用于评估,15%用于测试。为了增加训练数据,我们使用因子{0.8,0.9,1.1}进行水平翻转和图像缩放。训练大约进行了1万次迭代,批大小为32,当精度停止增加时停止。最初,学习率被设置为0.001,动量被取为0.9,衰减为0.0005。在训练学习率降低了3倍(即原来的10倍)。(没明白)为了避免过度拟合,我们在FC1和FC2层使** **。检测到的样本边界盒如图3所示。

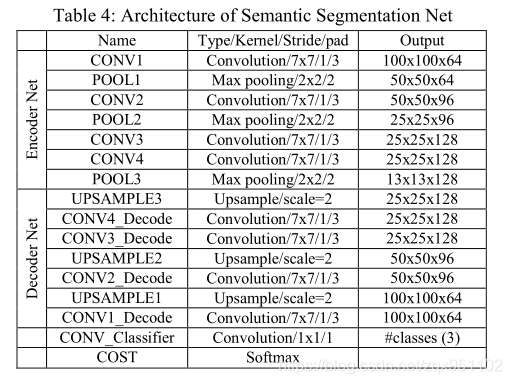
3.2. Pixel-wise Segmentation Network
在对图像进行边界盒CNN处理后,利用虹膜边界盒信息提取虹膜ROI,并将其调整为100×100像素的固定大小。需要注意的是,包围框内的ROI通常会包含一些不需要的像素,如巩膜、眼睑等。因此,为了获得更精确的虹膜纹理,我们提出了一种语义像素分割网络。所述网络包含编码器网络和相应的解码器网络,然后是像素级分类器。该方法的动机来自于Badrinarayanan等[4]中的SegNet架构。我们对原始的[4]网络进行了一些关键的修改,以获得一个更优的网络来完成我们的任务,将图像分割为3类;虹膜,瞳孔和背景。我们的网络如表4所示。编码器网络包含4个卷积层,解码器网络同样包含4个卷积层。在编码器和解码器网络的每个卷积层之后是批处理归一化[37]和ReLU非线性。在解码器网络中,利用最大池化索引对特征图进行上采样,保留了分割图像中的高频细节。译码器的最终输出输出给一个软最大分类器,以产生每个像素的类概率。分割后的样本图像如图3所示。分别使用VS和NIR图像的IrisDSGD-Iris_Mask_VS和IrisDSGD-Iris_Mask_NIR数据集(章节4.1)从头开始对我们的网络进行训练。
4. Data Sets
为了训练虹膜分割网,我们建立了groundthruth数据集。对于DeepIrisNet2,我们训练了不同类型的近红外和VS虹膜表示模型。我们创建了大规模数据集近红外和VS虹膜图像从公开可利用虹膜数据集。在默认设置下,对DeepIrisNet2的输入图像进行边界盒检测(第3.1节),然后进行像素级语义分割(第3.2节),并调整到100x100像素。
4.1. IrisDSGD dataset for Segmentation Networks IrisDSGD数据集分割网络
大规模数据集的可用性是[34]问题深度学习成功的关键因素之一。然而,对于虹膜的检测或分割,如此大规模的适合CNN训练的数据集是不公开的。为了解决这个问题,我们建立了一个大规模的手工标记数据集,称为虹膜检测和分割Groundtruth数据库(IrisDSGD)。IrisDSGD数据集的统计信息见表1和表2。数据集包含4个子集;BBox_VS和BBox_NIR: 通过在瞳孔和虹膜区域周围手动放置边界框创建的可见光图像和NIR图像的基本真实(Groundtruth)虹膜和瞳孔边界框信息,Iris_Mask_VS和Iris_Mask_NIR: Groundtruth虹膜模板包含一个为每个像素手工创建的标签作为虹膜/瞳孔或背景

4.2. NIR Dataset for DeepIrisNet2
使用ND-CrossSensorIris-2013[21]对我们的DeepIrisNet2网络进行近红外图像训练。数据库包含29986张来自LG4000的图像和116564张来自LG2200数据集的图像。这个数据集包含27个(sessions )会话的数据和676个不同的物体。两个数据集的身份被合并以获得一个更大的数据集。左右眼图像被赋予不同的类标签。此外,在训练集中增加了15%随机样本的4个转换版本和3个缩放版本,包含少于25张图片的身份被删除。最后,我们从1352个类标签中构建了一个近红外数据集,其中训练集包含大约30万张图像,验证集包含25000张图像。
4.3. Visible Spectrum Dataset for DeepIrisNet2
为了为可见光谱图像创建一个更大的训练集,我们结合了来自UBIRISv1[15],可见UTIRIS V.1[39],部分UBIRIS。v2数据库[22]。UBIRIS。v1数据库包含241个受试者的全部图像。UBIRIS。v2数据库包含261名受试者的共计11102张图像。这些图像具有很高的挑战性,并且是在不受约束的条件下多次拍摄的;有一定的距离,有点移动。我们从总共422类的211名左右眼受试者中选出8500张来自UBIRIS.v2的图片。UTIRIS数据集[39]包含从79个人的2个会话中捕获的840幅图像。在组合数据集中,对左右图像分别进行分类标注。最后,在组合数据集中,我们从820个类中获得了大约11154张图像。此外,我们通过对所有图像进行4次平移和3次尺度变换来抖动图像,从而增强了训练数据,总共得到145000幅图像,其中约130000幅用于训练,剩下的用于验证。
5. Spatial Transformer (ST) 空间转换
在[8]中,Jaderberg等人引入了空间转换器(ST)模块,可以插入到标准的神经网络中,在网络中执行数据的空间操作。图1显示了空间变压器模块及其组件。该模块的架构有三个主要的模块:1)本地化网络——它将输入特性作为输入,并通过许多隐藏层输出要应用于输入特征图的转换(Jθ)的参数(θ)。θ的大小取决于参数化的变换类型,例如对于仿射变换,θ是6-维度的。ii) Grid Generator—从输出图像中生成对应于每个像素的输入图像中坐标的Grid (G)。iii)采样单元——以特征图为输入,从输入的网格点采样,创建转换后的输出图像。
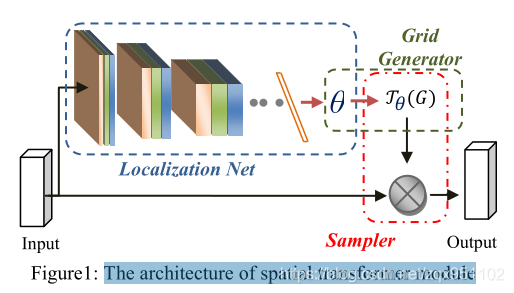
ST模块可以对输入图像进行适当的显式几何变换,包括为任务选择最相关的区域。ST可以学习转换,裁剪,旋转,缩放,或扭曲图像,基于转换参数计算由定位网络。转换的参数学习在端到端方式使用标准的反向传播算法,而不需要任何额外的数据或监督。ST的另一个优点是,通过处理与任务最相关的区域,ST还允许对这些区域进行进一步的计算。在[8]中,作者展示了使用ST模块进行细粒度鸟类分类和数字分类的学习意义转换。
在我们的DeepIrisNet2中,我们利用ST模块来预测虹膜图像中一个仿射变换的系数,例如平移、缩放、旋转。因此,(Jθ)二维仿射变换是Aθ。STN中的常规网格, G = Gi|Gi=x out yout 。在输入图像中提供与输出图像中的每个像素对应的坐标。如果取(x,y)为归一化坐标,如(x,y)∈[−1,1]×[−1,1],则给出一个仿射变换(Aθ)为

6. DeepIrisNet2 Architecture and Training
所提出的DeepIrisNet2网络是经过精心设计的,考虑了最近的文献建议和观察到其他非常成功的架构。我们尝试了各种配置,最终的网络配置如图2所示。DeepIrisNet2的架构与文献中针对各种任务提出的其他网络架构有很大的不同。DeepIrisNet2配置不仅提高了精度,而且收敛速度更快。我们分别训练了NIR和VS 虹膜识别使用近红外和可见光谱数据集在第4节中给出。对近红外图像和可见光光谱图像分别命名为DeepIrisNet2-NIR和DeepIrisNet2-VS。除了第一层外,这两个网络是一样的。我们网络的输入是固定大小的100乘100像素的图像。在训练过程中,通过从每个像素分别减去训练集上计算的平均灰度值和RGB值,对近红外图像和VS图像进行预处理。网络包含10个卷积层,第一层的kernel大小为5×5,其余的conv. layer的kernel大小为3×3。我们还在网络的某些中间层进行卷积层的叠加,而不需要在中间层之间进行空间池化,比如conv3-conv4, conv5-conv6, conv7-conv8-conv9.。通过去除这些层上输入的下采样操作,网络能够学习更复杂的高维表示。这是一个非常常见的做法,采取两到三个完全连接(FC)层,使用dropout在分类器层。文献中提出的大多数网络都采用了这种分类器级的设计来处理各种任务。在我们的DeepIrisNet2中,经验上我们采用了不同的方法,没有在分类器层使用多个FC层,而是在每个conv上添加了两个带有dropout正则化(dropout ratio设为0.5)的conv(即Conv9和conv10)。Dropout 有助于减少过度拟合。我们观察到这种设计不太容易出现过拟合。最后一个conv. layer(即conv10)的输出被送入C路Softmax(其中C是类的数量),它在类标签上产生一个分布。在整个网络中,除了Pool5是平均池外,空间池都是通过Max-pooling来实现的。之后我们在所有的卷积层使用ReLU激活函数,除了conv10。卷积层和线性层中的权重使用随机高斯分布从头开始初始化。我们训练我们的网络时使用了256个mini batch size,动量设置为0.9。训练通过权值衰减(L2惩罚乘数设为5x10−4)进行正则化。初始学习率被设置为0.01,然后当验证集的准确率停止提高时,学习率下降10倍。epoch的数量没有上限,当验证错误停止改进时,训练就停止了。总的来说,学习率下降了3倍。由于我们的DeepIrisNet2的网络非常深,所以我们尝试在中间层添加辅助分类器,就像之前的一些作品[32]中使用的那样。通过实验,我们发现在我们的网络中,将辅助分类器连接到Pool1、Pool2、Pool3和Poo
l4层可以获得最佳的结果。通过这种方法,我们的网络中包含了四个辅助分类器,它们都是浅卷积神经网络。不同辅助分类器的配置不同,具体如图2所示。我们观察了添加辅助分类器的各种好处,例如,a增加在网络中传播回来的梯度信号,以对抗深度架构下的梯度消失问题,b在较低的阶段有更多的区别特征(我们用从pool5阶段提取的特征),c网络中附加的正则化使得网络更难以过度拟合。在对网络进行训练时,将这些辅助分类器得到的损失加入到权值为0.3的主分支网络损失中。

CNNs中的pooling操作主要是为了获取输入特征图的子采样。池化操作是在没有重叠的当地社区上完成的,它创建每个子区域的精华。因此它也提供了一点位置和平移不变性。然而,由于预先定义的池化机制和对最大池化的小空间支持(例如2×2像素),这种空间不变性对于输入特征图的大变化不是很有效。
为了获得针对大变化的动态空间不变性,在我们的DeepIrisNet2架构中,我们整合了多个空间变形器模块[8],它能够生成输入特征图的自动转换,如上文第5节所述。特别地,在我们的网络中,第一个空间转换器模块是在输入层之后立即插入的,另外两个空间转换器模块是在Pool1和Pool2层之后添加的。不同空间变压器模块的网络是不同的,图2给出了深irisnet2中嵌入的不同空间变压器模块的详细信息。当输入到空间转换器模块的通道数多于一个时,对所有通道应用相同的转换。通过在DeepIrisNet2中使用多个空间转换器,我们对其进行了分析能够获得越来越抽象的表示的转换。
DeepIrisNet2包含11层,参数没有空间变压器模块。对于空间转换器模块,它包含14个层,如果我们再考虑池层,它也包含20个层。如果我们算上DeepIrisNet2所使用的每一块积木,那么总共的层数约为100层。网络中参数总数约为34M。基于我们的方法提出的虹膜识别管道如图3所示。
(STN层包含LN和GG也就是空间转换器层,主要是能够生成输入特征图的自动转换,这三个层结构不一样。pool1234层后外接四个辅助分类器,然后系数是0.3.再看卷积操作conv,右边图说明了,意思就是conv-bn-relu这样的顺序输出)
7. Experiments Analysis
7.1. Performance Analysis of Segmentation Nets
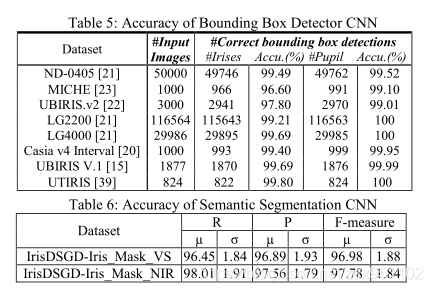
在边界盒检测CNN的情况下,我们使用15%的ground truth图像进行测试,这些图像在训练时没有用到。首先,我们通过使用受试者工作特征(ROC)曲线下的面积(也称为AUC)来计算准确性。对于Bor BBox_VS测试集(1350幅图像),我们得到了96.78%的准确率,对于BBox_NIR测试集(1500幅图像),我们报告的准确率为97.87%,这是相当可观的。其次,我们使用这个CNN在不同的数据集(不含ground truth)上检测虹膜对象,通过视觉检测计算检测精度。准确性见表5。
在语义pixel-wise分割网络,CNN的虹膜mask与ground truth mask,我们报告,(µ)均值和标准偏差(σ)精密§、recall ®和F-measure (F)指标[9]在完成了测试集。结果很好,如表6所示。
由于我们的虹膜分割管道与之前所有的方法都是完全不同的,我们无法与现有的其他方法进行比较分析。(很强)
7.2. Performance Analysis of DeepIrisNet2
我们分别训练了两种模型:DeepIrisNet2-VS和DeepIrisNet2-NIR用于可见光谱和近红外虹膜图像。为了实现i虹膜的表示,我们使用了从Pool5层提取的特征,其维数为1024。相似度得分采用余弦距离计算。为了公正的比较,
在默认设置下,测试数据集中的所有图像都用与训练数据集中相同的管道进行处理,并归一化为100×100像素。模糊的图像不应用于测试图像。
Experiment 1: Iris Recognition for VS iris images
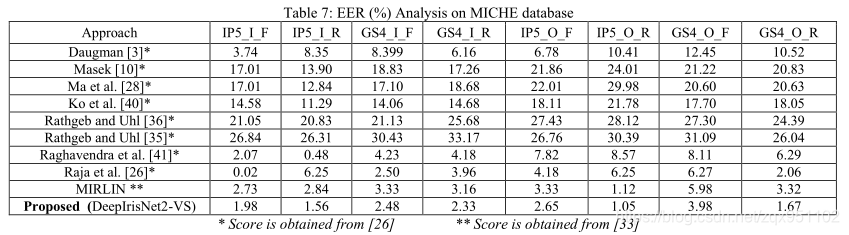
为了实证评估所提出的DeepIrisNet2在可见光谱虹膜捕获下的性能,我们对具有挑战性的UBIRIS.v2和MICHE数据集进行了性能分析测试。UBIRIS.v2的测试集包含大约2300张图片,其中有100个类别标签,这些图片不在训练/验证集中。MICHE-I数据集包含使用iPhone5、SamsungGalaxyS4和SamsungGalaxyTab2拍摄的图像。在室内和室外条件下,使用前置和后置摄像头拍摄图像。MICHE数据库的主要目的是评估使用内置摄像头的移动设备上虹膜识别算法的性能。在评估MICHE的过程中,我们部分遵循了Raja等人推测的实验。[26]。此外,以下[16,44],三星GalaxyTab2图像不考虑评估。在MICHE测试集中,大约拍摄了1200张来自iPhone5的图像和1200张SamsungGalaxyS4手机的图像,这些图像进一步分为四个子类别:前/后和室外/室内。最后,50%(150)张图像被拍摄到图库集,剩下的50%(150)张图像被拍摄到每个类别的集中。结果(EER)见表7。由于我们的网络是在不同的数据库上训练的,很容易观察到所提出的deepirisnet2vs网络不仅能很好地推广到新的数据库,而且具有很好的识别率。还应注意的是,我们几乎使用了每一类中的所有MICHE图像进行测试(共有75名受试者中的2500名),而之前的研究仅使用了[16,44]有限的(~50-100)图像报告准确性。
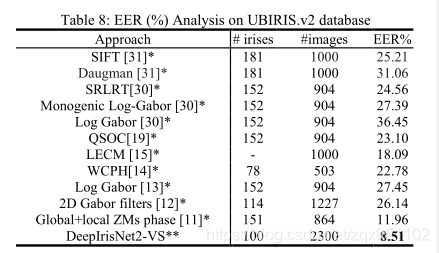
UBIRIS.v2数据库的性能分析(EER)如表8所示。表8还说明了各种算法之间的性能比较。可以清楚地看到,所提议的DeepIrisNet2 VS是相当有效的。我们也观察到,所提出的网路比所有先前的方法都有很大的优势。
Experiment 2: Iris Recognition for NIR iris images
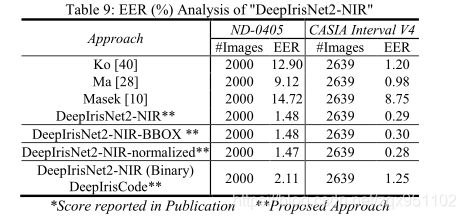
测试是在著名的具有挑战性的近红外数据集上进行的;ND-iris-0405,CasiaintervalV4[20]。测试数据集与用于网络训练的数据集完全不同。ND-iris-0405包含356名受试者的64980张图像;Casia Interval V4包含249名受试者的2639张图像。为了进行比较分析,我们还评估了著名的Ko等人。[28]1,Ma等人[38]1,Masek[10]方法。EER表9中报告了这些方法。综上所述,在ND-iris-0405和CASIA Interval V4数据库上,所提出的DeepIrisNet2近红外结构比强基线虹膜识别算法有了显著的改进,这进一步证实了所提出的DeepIrisNet2对NIR图像的有效性。
Experiment3: DeepIrisNet2 with Poorly Segmented Iris Images (Segmentation with Bounding Box data) 分割较差的虹膜图像
本实验旨在研究理想虹膜分割对虹膜识别准确率的影响。为此,使用第4.2节中分割不良的NIR数据集从头开始训练一个单独的网络。为此,在输入图像中,瞳孔和其他不需要的(噪声)区域使用边界框CNN(Sec。3.1)。该方法以瞳孔包围盒的中心为中心,以高宽平均值为直径,计算出圆形区域对瞳孔进行掩模。同样地,虹膜外部区域是利用虹膜边界盒信息来屏蔽的。图3所示为蒙蔽图像样本。我们把这个型号命名为DeepIrisNet2NIR-BBox。在该网络的训练过程中,我们观察到当训练在完美分割的影像上时,网路会更快地收敛,但是经过大约1000次的迭代,两个模型的训练和验证误差几乎相同。DeepIrisNet2近红外BBox的性能(EER)如表9所示,说明DeepIrisNet2 NIR和DeepIrisNet2-NIR-BBox报告的验证率几乎相同。DeepIrisNet2-NIR在分割较差的图像上的惊人性能可以归因于网络中引入了空间变换器(ST)模块。为了验证这一点,我们训练了两个没有ST模块的DeepIrisNet2近红外网络。在完全分割的虹膜的情况下,准确度有轻微的降低(0.35%),然而,在分割不良的虹膜的情况下,准确度的差异在1%左右。
Experiment 4: Non-Normalized Vs. Normalized images
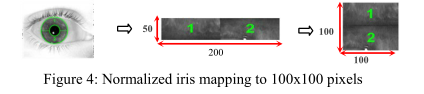
本实验旨在对我们的分割管道(第3节)分割的虹膜图像训练的DeepIrisNet2 NIR网络和使用Daugman橡胶板模型规范化虹膜图像的DeepIrisNet2 NIR网络进行比较分析。为了进行标准化,我们使用IrisSeg框架[9]对虹膜边界进行了定位,在标准化过程中,图像被展开并以矩形传输 以极坐标表示的图像,大小为50×200像素。按照[1]中采用的方法(图4),将归一化图像进一步映射到100×100像素的图像。在正常图像和归一化图像上训练的两个DeepIrisNet2-NIR模型被称为DeepIrisNet2-NIR和DeepIrisNet2-NIR-normalized。该网络的精度如表9所示。结果表明,使用归一化后的图像训练的网络收敛速度更快,性能稍好。
Experiment 5: Real-valued Features Vs. Binary Feature Vector (DeepIrisCode) 实值特征与二进制特征向量
为了生成二进制虹膜码,我们考虑了最后一层Pool5层的特征激活,输出1024维张量。然后通过阈值转换成二进制代码。阈值分割产生稀疏向量,因此这种表示通常会降低性能。需要注意的是,为了在Pool5上获得密集紧凑的实值输出,我们没有在conv10应用ReLU。如表9所示,DeepIrisNet2 NIR中pool5特征的二进制表示通过直接计算汉明距离牺牲了~0.5到1%的精确度。然而,二进制编码存储经济,虹膜匹配速度快。(就是说假如pool5后面接一个汉明距离分类作为分类器,这样好处是匹配速度快,存储便宜,但是二进制的存储方式,阈值选择时候会产生稀疏向量,这样会降低性能,精度下降)
8. Conclusion
在这项工作中,我们做出了多方面的贡献:i)我们提出了一种虹膜/瞳孔边界盒检测CNN和另一种用于虹膜纹理语义分割的CNN体系结构;ii)我们构建了一个包含虹膜手工标注、瞳孔边界框和虹膜掩模像素级标记的大规模数据集IrisDSGD,iii)我们提出了一个健壮的deep-CNN架构DeepIrisNet2,**它不需要Daugman的虹膜标准化步骤和完美的虹膜分割就可以有效地工作。(归一化后精度会提升一点,但是作者没用这个方法,直接输入的是100100大小的语义分割后的图像)**通过大量的实验分析表明,该方法不仅适用于新的图像,而且适用于新的subjects。在非常大和极具挑战性的数据集上,它表现出很有竞争力,获得了突破性的准确率,并达到了新的最先进的识别率。未来的工作将集中在训练端到端虹膜识别解决方案。
2019年的论文,这篇确实比DeepIrisNet1难理解多了。这篇发表在CS.CV计算机视觉方向的论文,Fri, 15 Feb 2019。
坐一天了 屁股疼 明天在好好研究 理解理解。 找了半天也没找到作者说可以公开的标注的数据集。。。IrisDSGD仔细读了第二遍,发现很多地方理解更深了。yolo用于检测虹膜的矩形框,然后用语义分割网络进行虹膜模板的分割,大小为100100像素,然后把这个图片输入到DeepIrisNet2架构中,这个分为红外下的数据集和自然光的数据集。然后进行一系列的实验说明。总体来说这篇论文很好,一整套思路还是很清晰的。恶补一下空间转换器知识和yolo的。
PS:个人理解,如有错误,还请赐教指出来改正,大家共同进步。
(完结!!)