翻译:
An Experimental Study of Deep Convolutional Features For Iris Recognition
深度卷积特征用于虹膜识别的实验研究 2016年
ABSTRACT
Iris是一种广泛应用于身份认证的生物识别技术。虹膜识别是一种新型的识别方法。它们中的大多数都是基于生物识别专家设计的手工特征。由于深度学习在计算机视觉问题上的巨大成功,人们对将卷积神经网络在一般图像识别中学习到的特征应用于分割、人脸识别和目标检测等其他任务产生了浓厚的兴趣。本文研究了vgg- net中提取的深度特征在虹膜识别中的应用。该方法在两个著名的虹膜数据库上进行了测试,得到了良好的结果,准确率达到了99.4%,超过了之前的最佳结果。
1 INTRODUCTION
为了使应用程序更个人化或更安全,我们需要能够将每个人与其他所有人区分开来。生物特征是一种流行的身份验证方式,除了需要的人自己,任何人都不能模仿它。许多工作围绕着识别和验证生物特征数据,包括但不限于面部、指纹、虹膜模式和掌纹[1]-[4]。虹膜识别系统广泛应用于保安应用,因为它包含丰富的特征,而且不会随时间而发生重大变化。
虹膜识别在过去已经有很多算法。早期的算法之一是由John Daugman开发的,使用了2D Gabor小波变换[5]。在最近的一项工作中,Kumar[6]提出使用基于Haar小波、DCT和FFT的特征组合来实现高精度。在[7]中,Farouk提出了一种利用弹性图匹配和Gabor小波的方案。每个虹膜被表示为一个标记图,并定义一个相似度函数来比较两个图。在[8]中,Belcher使用了基于区域的SIFT描述子进行虹膜识别,取得了较好的效果。Pillai[9]提出了一种基于随机投影和稀疏表示的统一框架来实现鲁棒和精确的虹膜匹配。Minaee在最近的工作[10]中提出了一种基于纹理和散射变换特征的算法,与之前的算法相比,该算法获得了较高的准确率。这种方法也从多层表示中提取特征,但使用预定义的过滤器。读者参考[3]对虹膜识别的全面调查。
在大多数虹膜识别工作中,首先对虹膜区域进行分割,然后将其映射到极坐标下的矩形区域。然后,从该区域提取特征。大多数这些特性都是手工制作的,可以很好地用于特定类型的数据或生物识别。传统方法的主要问题是,它们需要进行大量的预处理和参数调优,才能在给定数据集上正常工作,而且它们在其他生物特征数据集甚至是相同生物特征的不同数据集上的效率无法保证。为了克服这个问题,在过去的几年里,我们做了很多努力来学习一些可以在许多任务中转移的通用特性。沿着这个方向,深度神经网络已经在各种数据集上取得了最先进的结果,最著名的是AlexNet[11],它是在ImageNet竞赛(包含大约120万手动标记图像1000个类别)[15]上训练的。在深度学习框架中,将图像作为多层神经网络的输入,由神经网络找出最佳的像素组合方式,以最大限度地提高识别精度。在[16]中,通过实验研究表明,通过训练深度网络进行图像识别所获得的特征可以转移到其他任务和数据集中,并取得了显著的性能。从那时起,不同网络的特征,如alexnet, ZF-Net, vggnet和resnet[11]-[14]被用于各种任务,如纹理合成,目标检测和图像分割。
在这项工作中,我们探索了利用vggn - net提取的深度特征在虹膜识别中的应用。我们将经过训练的模型作为一个特征提取引擎,用于虹膜图像的特征提取,不进行任何微调,看看一般特征是否适用于生物特征识别。然后利用主成分分析对特征进行降维,再利用多类支持向量机进行识别。我们对CASIA 1000虹膜数据集[38]和IIT虹膜数据集[39]进行了广泛的实验研究。CASIA-1000数据集的四张虹膜样本图像如图1所示。(本文的工作重点,试探性的工作)

值得一提的是,在我们的框架中,我们跳过了分割步骤,以查看这些特性对类内部变化的健壮性,尽管在CASIA-1000数据集存在很多变化,该算法取得了很高的准确率。
有趣的是,虽然vgg- net被训练用来对不同类别的物体进行分类,但是该网络的CNN特征对于虹膜识别的效果还不错,即对不同主体的虹膜图像进行分类(即所有图像都属于同一个物体类别,这里是指虹膜)。
2. FEATURES
在许多计算机视觉和目标识别算法中,提取好的特征和图像描述符是一个非常重要的步骤。在过去的几年里,人们设计了许多特征,这些特征对许多图像类别都提供了很好的表达,例如:尺度不变特征变换(SIFT)、梯度方向直方图(HOG)和单词包(BoW)[17]-[19]。这些特征大多是由计算机视觉专家设计的,通常被称为手工制作的特征。不同的应用程序,如医学图像分析[20]-[21],可能使用一组非常不同的手工制作的特性。最近,特征学习算法和多层表示引起了人们的广泛关注,其中最著名的是卷积神经网络[22],它将图像直接作为输入输入到深度神经网络中,算法本身从图像中找到最佳的特征集。在过去的几年中,基于卷积神经网络的Deep architecture在许多计算机视觉基准中取得了最先进的结果,包括AlexNet、ZF-Net、GoogLeNet、vgg.net和ResNet,在2012年和2015年ImageNet竞赛中取得了很好的结果。从这些网络的特性显示被转移到其他数据集和任务[16],这意味着训练网络ImageNet图像用于从其他数据集,然后提取特征分类器训练的这些特性在其他数据集进行识别,如Caltech101或Caltech256。它们还被广泛用于其他计算机视觉任务,如分割、目标跟踪、纹理合成、着色和超分辨率[23]-[26]。
这将是有趣的分析的应用深度训练一个事先学习的特性,对虹膜识别的问题,这是不同于物体识别,目标是不区分不同类型的对象,但区分属于不同的人相同的图像。(区分这个虹膜是谁的问题,而不是判断是不是像imagenet那样,判断属于哪个物体)在本研究中,我们将从vgg- net中提取的深度特征应用于虹膜识别,这是迄今为止我们所知还没有研究过的。在这里,我们对vgg.net做一个快速的概述。
2.1. VGG-Net Architectur
vgg.net是ILSVRC 2014 (ImageNet大型视觉识别比赛)的亚军,由Karen Simonyan和Andrew Zisserman[13]提出。图2显示了vgg.net的总体架构。它表明,网络的深度是良好性能的关键组成部分。他们的最终最佳网络包含16个CONV/FC层和5个池化层。总的来说,它有大约1.38亿个参数(其中大部分位于FC第一层,权重大小为102M)。VGGNet的一个优点是它的均匀架构非常好(看着堆叠的很整洁的意思),它只执行3x3卷积其中stride 为1和pad为 1,从网络开始到结束只执行2x2池化操作(没有填充)。
读者可以参考[13]和[36],以获得关于该网络各层的架构和参数数量的更多细节。我们从该网络的不同层次提取特征,并评估其虹膜识别性能。

我们进一步对深层特征进行PCA[27]来降低其维数,并对不同维数的特征进行性能评估。(用vgg提取特征有很多参数,所以需要pca主成分分析法,提取斜向量上最有用的前几个向量作为主要向量,代替数据。)
2.2. Alternative Hierarchical Representation With Pre-defined Filters 预定义过滤器的可选层次结构表示
我们想要提到的是,还有其他类型的深层架构,它们不学习过滤器,而是使用预定义的权重。分散卷积网络是将信号分解成不同尺度和不同方向的多层网络。然后从每幅变换图像中提取一些统计特征,并将所有变换图像中的特征串联起来,形成整体的特征表示。散射网络在过去的[29]-[31]中也被用于生物特征识别。为了说明这个网络是如何工作的,第二层散射网络对虹膜样本图像的输出如图3所示。可以看到,每幅图像都包含了沿某一方向、某一尺度的边缘信息。然而,由于过滤器不是后天习得的,而且在不同的任务中是固定的,因此这种架构可能不是一些视觉应用程序的最佳架构。然而,在训练数据量非常有限,不足以训练和卷积神经网络的情况下,它们可能非常有用。(就是把虹膜归一化的图像在某些卷积层后输出,计算机看见的图像就是长这样的特征图)

3. RECOGNITION ALGORITHM 识别算法
特征提取后,需要一个分类器为每幅测试图像找到对应的标签。有各种分类器可以用于这个任务,包括softmax回归(或多项式逻辑回归),支持向量机[32]和神经网络[33]。在本研究中,我们使用了图像分类中比较流行的多类支持向量机。本文简要介绍了支持向量机的二值分类方法。有关多类设置和非线性版本的进一步细节和扩展,请读者参阅[34]和[35]。假设我们要分离训练数据集(x1, y1), (x2, y2),…, (xn, yn)分为两个类,其中xi∈Rdis特征向量,yi∈{−1,+1}为类标签。假设这两个类是线性可分的,我们可以用超平面w将它们分离。x + b = 0。在超平面的所有可能选择中,支持向量机找出边际最大的超平面。最大边缘超平面可以通过以下优化问题得到:

上述优化为凸优化,可以用凸优化技术求解。一种常用的方法是引入拉格朗日乘子- i来解决对偶问题,从而得到一个分类器f(x) = sign(Pn i=1 reiyiw)。(x + b),其中采用支持向量机学习算法计算出各点的值。支持向量机还有一个软边界版本,允许错误标记的例子。为了对一组有M个类的数据进行多类支持向量机测试,我们可以训练M个二值分类器,这些二值分类器可以区分每一个类和所有其他类,并选择能够分类到最大边际的测试样本的类。在另一种方法中,我们可以训练一组?二进制分类器,每个分类器从另一个分类器中分离一个类,然后选择被大多数分类器选择的类。支持向量机用于多类分类的方法还有很多。
4. EXPERIMENTAL RESULTS AND ANALYSIS
在本节中,我们将提供实验结果的详细描述。在给出结果之前,让我们先描述一下算法的参数值。对于每一张图像,我们从vggnet的不同层、fc6和之前的一些层中提取特征。fc6层的输出是一个4096维的向量,但在之前的层中,我们有256/512个不同大小的滤波器输出。我们取每个滤波器输出的平均值,从每一层形成一个特征向量,以评估从不同层提取的特征的性能。对于SVM,我们使用LIBSVM库[41],使用线性核函数,代价C = 1。
我们已经在两个iris数据库(CASIA-Iris-1000和印度理工学院德里分校)上测试了我们的算法。CASIA-Iris-1000包含了来自1000名受试者的20000张虹膜图像,这些虹膜图像是使用ikcam -100相机[38]采集的。CASIA-Iris-1000中阶级内部变化的主要来源是眼镜和镜面反射。印度理工学院德里数据库包含2240张虹膜图像,这些图像来自224个不同的人。这些图像的分辨率为320x240像素[39]。我们将所有图像的大小调整为224x224,以适合vggnet输入。
对于每个人来说,大约一半的图像用于训练,剩下的用于测试。我们首先评估fc6层特征的识别精度。首先将主成分分析应用于所有特征,评估不同数量的主成分分析特征的识别精度。图4和图5分别显示了使用不同数量的PCA特征对IIT德里和CASIA数据集的识别准确率。有趣的是,即使使用很少的PCA特征,我们也能得到非常高的准确率。可以看出,使用100个PCA特征,对IIT数据库的准确率达到98%以上,而使用更多的PCA特征,准确率仅提高1%左右。
在另一个实验中,我们评估了从vggnet不同层提取的深层特征的性能。为了进行公平的比较,我们将每一层的特征数限制为256个(如果有的层有超过256个输出过滤器,选取前256个)。图6显示了在印度理工学院德里数据库上使用vgg.net不同层次的特征所取得的识别准确率。
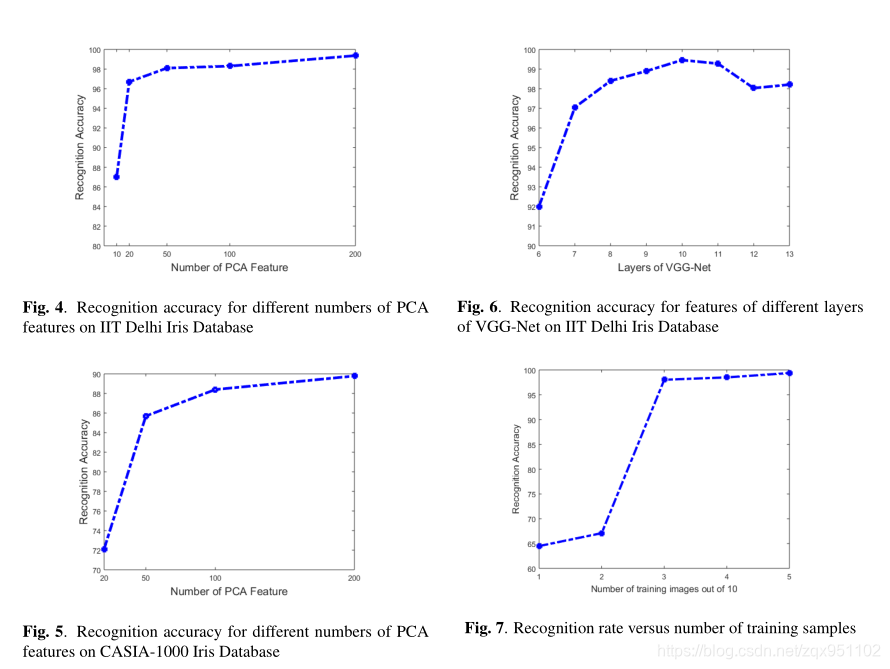
可以看出,在第7层之后的任意一层中提取特征,准确率都可以达到98%以上。利用第10层的特征,识别准确率达到高峰,然后下降。一个可能的原因是,通过进入深度网络的更高层次,他们开始捕获更抽象、更高层次的信息,这些信息对不同的虹膜模式没有太大区别,而前一层的中层特征对同类识别有更强的区别能力。(这结论有点像我第一篇虹膜识别那个论文的结论。。)
我们还评估了该方案对用于训练的训练样本数量的鲁棒性。我们将每个人的训练样本数量从1到5(10个样本中的一个)进行变化,并找到识别的准确性。图7显示了该算法对于不同训练样本的IIT数据库的准确率。可以看出,10个样本中使用3个样本的识别准确率比使用1个或2个样本的识别准确率有较大的提高,并且通过增加训练样本的数量,识别准确率保持相对不变。
表1给出了在IIT数据库上所提出的方案和其他最近的算法的性能比较。**散射变换方案[**10]也使用了多层表示,并取得了很高的准确率。通过使用深度特征,我们能够在该数据集上达到最高的准确率。这主要是由于深度特征的丰富性,能够捕获手工制作特征中丢失的许多信息,从而提供非常高的识别能力。该方法的一个主要优点是不需要将虹膜从眼部图像中分割出来,但是对于一些困难的情况,分割可以提高结果。

实验使用MATLAB 2015在alaptopwithCorei5CPUrunningat2.2GHz上进行。为了增强特性,MatConvNet包用于从vgg.net[40]中提取特性。
5. CONCLUSION
在这项工作中,我们评估了深度特征的应用,从vgg.net提取,然后是一个简单的分类算法的虹膜识别问题。深层特征这些年来一直是关注的中心,并被用于许多不同的应用。虽然在本工作中使用的原始卷积网络是针对一个非常不同的任务(对象识别)进行训练的,但可以证明特征可以很好地转移到生物特征识别中。该算法在两个著名的数据集上进行了测试,取得了良好的效果,并在其中一个数据库上取得了较好的效果。我们想指出的是,之前的大多数虹膜识别算法都涉及大量的预处理和参数调优,但在我们的框架中,没有进行预处理和架构优化。这一结果可以通过训练一个专门用于虹膜识别的深度网络来进一步提高,这有待于进一步的研究。
本文总结:作者证明了 vgg可以用于提取虹膜特征,也就是说这些深度学习的网络架构 不光可以用在imagenet上,也可以适用于虹膜识别的分类上。作者提出的新的vgg提取特征,然后pca降低维度,然后训练svm分类。
PS:个人理解,如有错误,还请赐教指出来改正,大家共同进步。
(完结!!)