参考
卷积计算方式:https://zhuanlan.zhihu.com/p/268179286
Depthwise卷积与Pointwise卷积:https://zhuanlan.zhihu.com/p/80041030
1. 卷积(计算过程、输入输出、参数个数、乘法次数)
ref: https://zhuanlan.zhihu.com/p/268179286
卷积,本质上是矩阵点乘和加法。
如下图所示,输入为蓝色部分即7x7的矩阵,卷积核为蓝色阴影部分即3x3的矩阵。卷积计算即在输入中依次选取和卷积核大小相等的矩阵,与卷积核依次进行矩阵点乘(对应位置进行相乘,并将结果累和),最后再加一个偏置项。所以,输出为绿色部分即5x5的矩阵。

单通道与多通道:输入可能是单通道如上图所示,实际应用中可能有单通道语音;也可能是多通道,如图像中的红蓝绿三个通道、语音中的多通道语音识别。
单卷积核与多卷积核:卷积核个数还可以是多个,那我们为什么需要多个卷积核进行卷积呢?对于一个卷积核,可以认为其具有识别某一类元素(特征)的能力;而对于一些复杂的数据来说,仅仅只是通过一类特征来进行辨识往往是不够的。因此,通常来说我们都会通过多个不同的卷积核来对输入进行特征提取得到多个特征图,然再输入到后续的网络中。
1.1 单通道单卷积核
单通道输入、单卷积核
输入:现有一张形状为[5,5,1]的单通道灰度图
卷积核:一个卷积核为[3,3]的矩阵,和偏置项
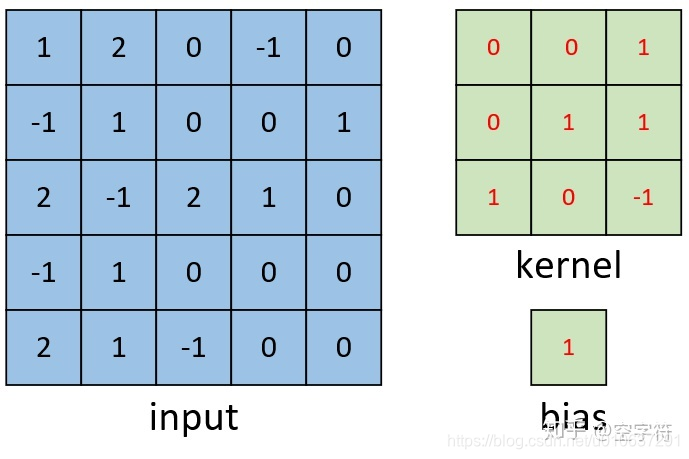
卷积计算过程
卷积计算过程如下:
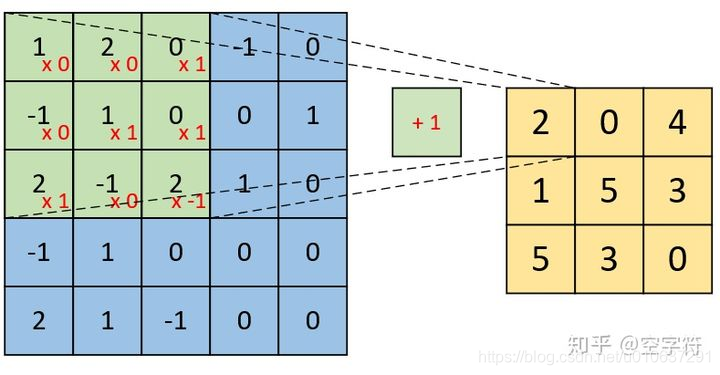
即:
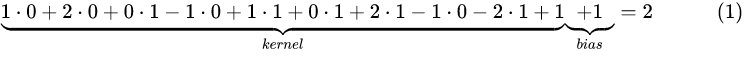
则:
输出、参数个数、乘法次数
输出:为单通道,矩阵大小为[3, 3]
参数个数:即单卷积核参数个数加偏置项,即3x3 + 1 = 10
乘法次数:
每次矩阵点乘的乘法次数为:卷积核大小即 3x3 = 9
总共乘法次数为:9 * 9 = 81
总共加法次数为:9
1.2 单通道多卷积核
单通道输入、多卷积核
输入:现有一张形状为[5,5,1]的单通道灰度图
2个卷积核:2个卷积核为[3,3]的矩阵,和2个偏置项:
其实可以看出,有几个偏置项就有几个卷积核(在use_bias=True的情况下)。
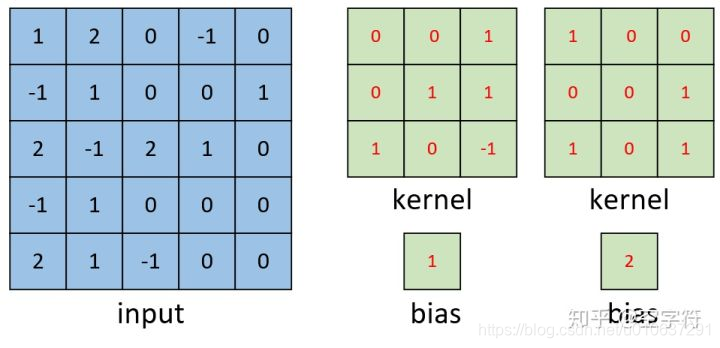
卷积计算过程
每个通道的卷积计算和单通道单卷积核计算过程一样:
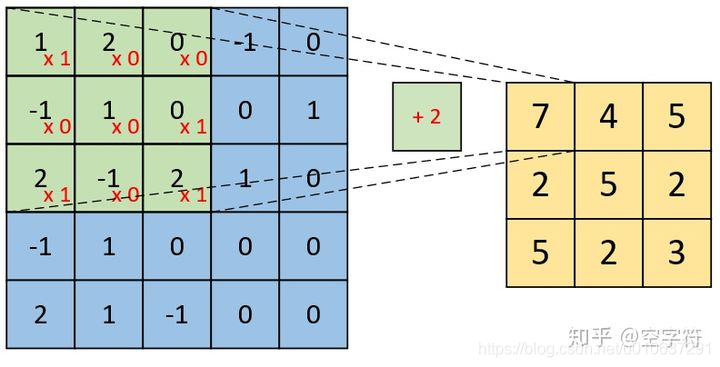
那么,多通道单卷积核就有多个单通道单卷积核计算过程:
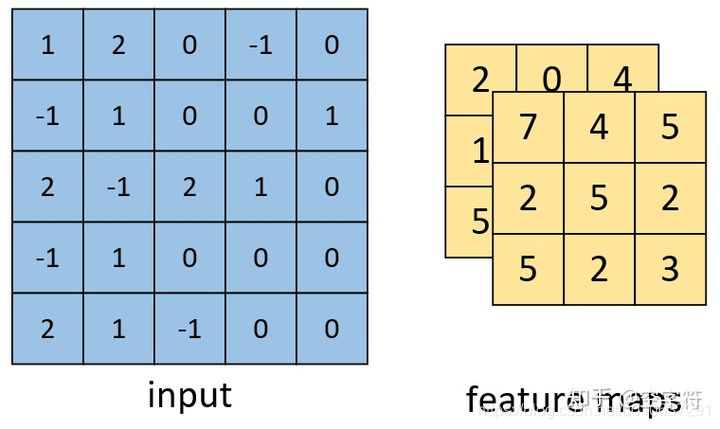
输出、参数个数、乘法次数
输出:为多通道,矩阵大小为[3, 3, 2]
参数个数:
即多卷积核参数个数加偏置项,即2 * ( 3 x 3 + 1) = 20
乘法次数:
每次矩阵点乘的乘法次数为:卷积核大小即 3x3 = 9
总共乘法次数为:2 * 9 * 9 = 162
总共加法次数为:9 * 2 = 18
1.3 多通道单卷积核
多通道输入、单卷积核
输入:现有一张形状为[5,5,3]的多通道红蓝绿三色图
单卷积核:1个卷积核为[3,3, 3]的矩阵,和1个偏置项
注:此时的单卷积核和单通道单卷积核中的单卷积核不同,维度由[3, 3] 变为了 [3, 3, 3],即变为了多通道的单卷积核;但偏置项个数为1,即还是一个单卷积核。
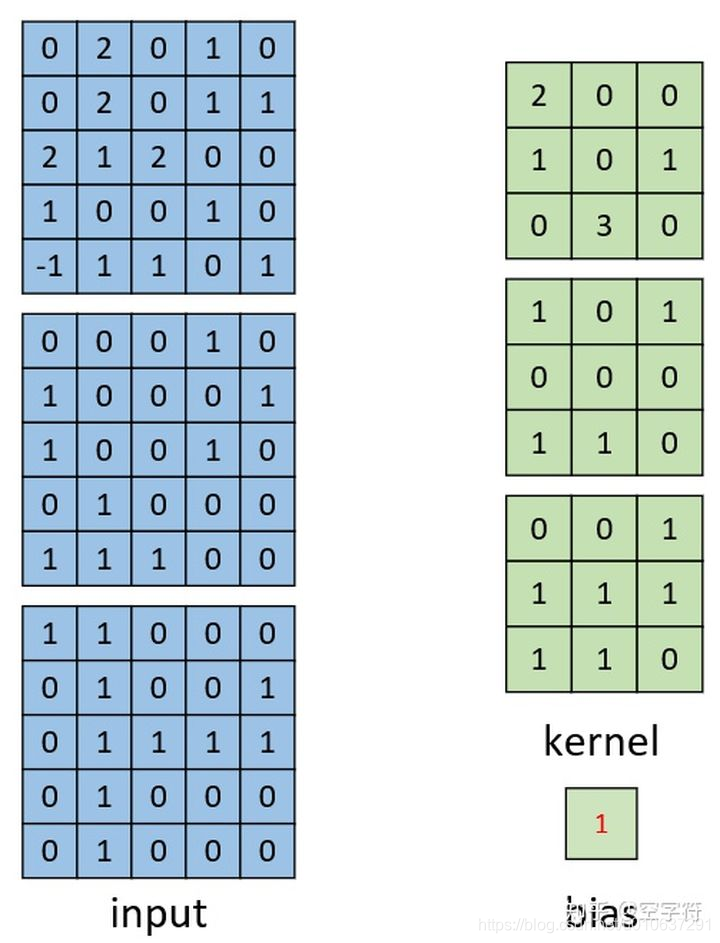
卷积计算过程
可看出输入和卷积核均为多个通道,此时即将每个通道的输入和卷积核进行点乘,累和后,与其他通道的累和结果进行相加,最后再加上偏置项:
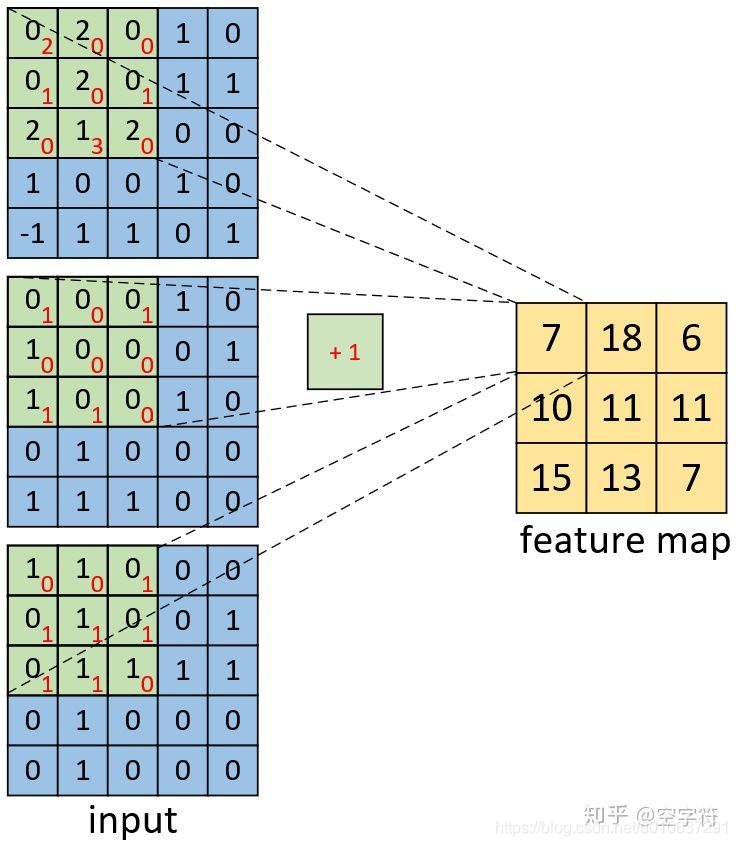
即:
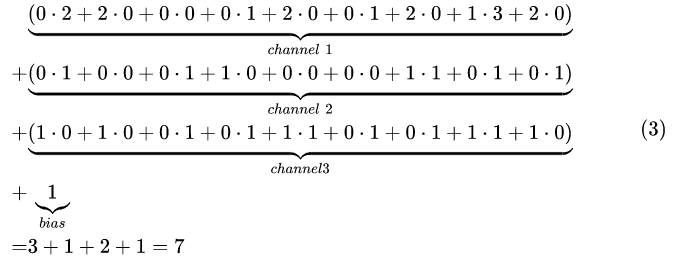
输出、参数个数、乘法次数
输出:为单通道,矩阵大小为[3, 3]
参数个数:即单卷积核参数个数加偏置项,即3x3x3 + 1 = 28
乘法次数:
每次矩阵点乘的乘法次数为:卷积核大小即 3x3 = 9
总共乘法次数为:9 * 3个通道 * 9个输出参数个数 = 243
总共加法次数为:9
1.4 多通道多卷积核
多通道输入、多卷积核
输入:现有一张形状为[5,5,3]的多通道红蓝绿三色图
多卷积核:2个卷积核为[3, 3, 3]的矩阵,和2个偏置项
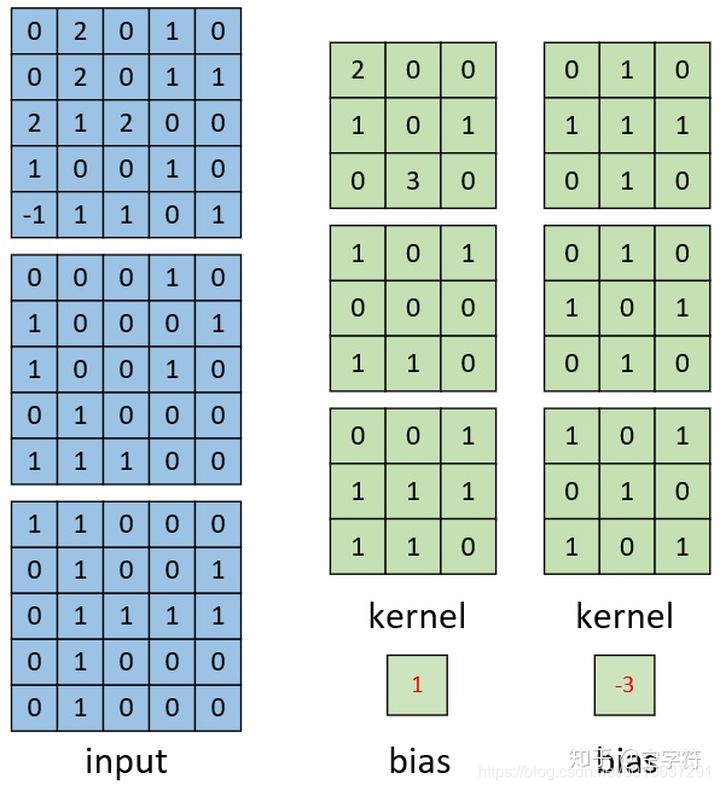
卷积计算过程
可看出多通道多卷积核与多通道单卷积核计算过程类似(而不是单通道多卷积核),因为此时卷积核的“通道个数”为3。
所以卷积计算过程即为多个 多通道单卷积核计算过程:
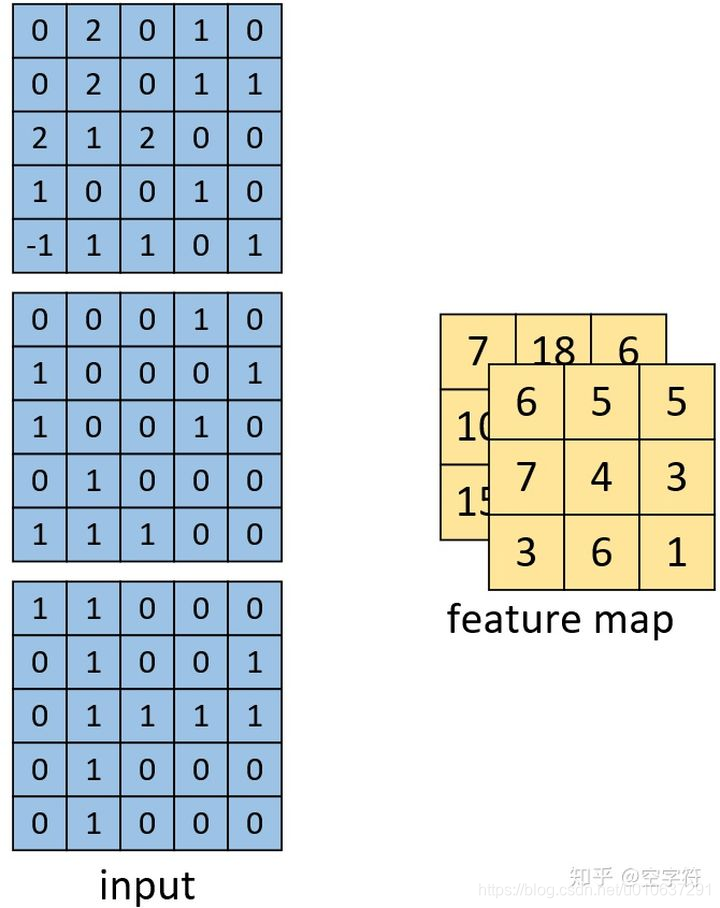
输出、参数个数、乘法次数
输出:为多通道,矩阵大小为[3, 3, 2]
参数个数:
即多个卷积核参数个数加偏置项,即2 x (3x3x3 + 1) = 56
乘法次数:
每次矩阵点乘的乘法次数为:卷积核大小即 3x3 = 9
总共乘法次数为:2个通道*(9 * 3个通道 * 9个feature个数 )= 486
总共加法次数为:9* 2个通道 = 18
2. 实现示例
2.1 单通道单卷积核
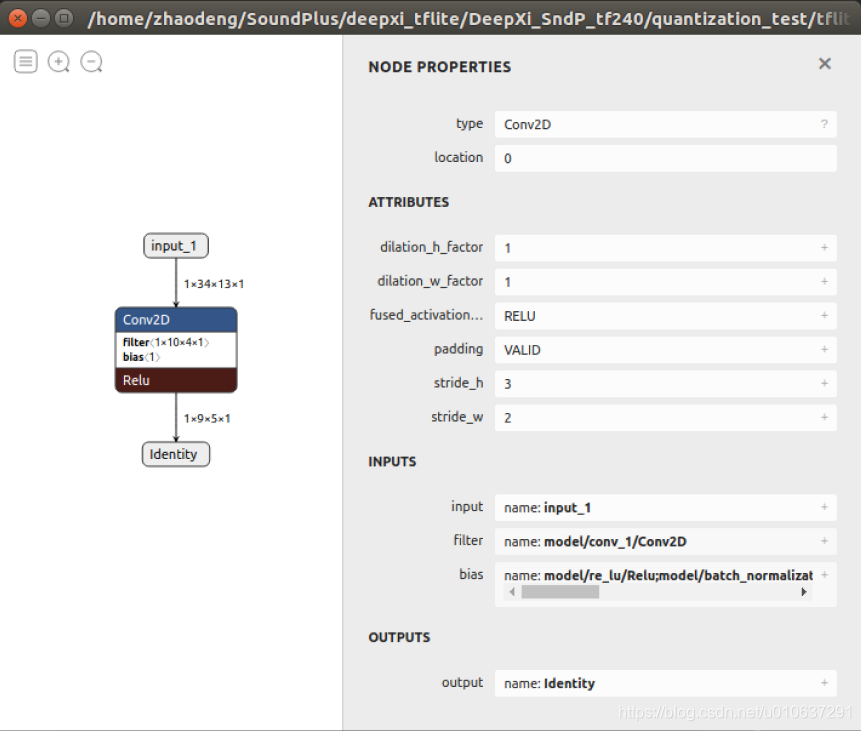
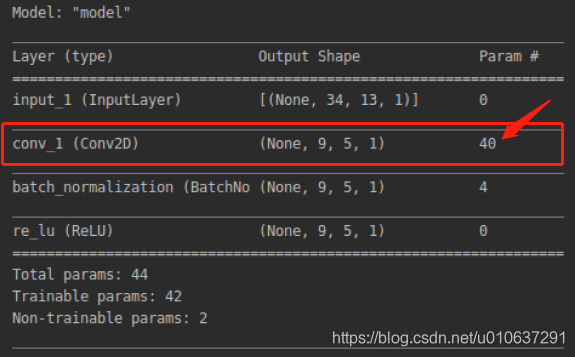
单通道输入:[1, 34, 13, 1]的单通道矩阵,即输入的batch_size = 1,width = 34, height = 13, channels = 1
单卷积核:
filters=1,
kernel_size=[10, 4]
use_bias=True:一个偏置项
strides=[3, 2]:卷积移动步长
padding=“VALID”:不进行padding
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=1, kernel_size=(10, 4), strides=(3, 2), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite")
return model
def convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite"):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(filename_tflite, "wb").write(tflite_model)
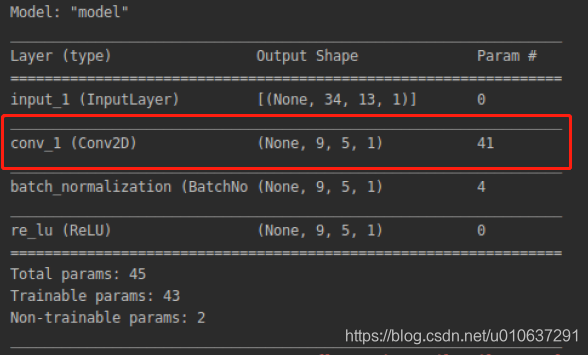
则:
输出:ceil((34-10+1)/3)=9, ceil((13-4+1)/2)=5
即[1, 9, 5, 1]: batch_size=1, width=9, height=5, channels=1
参数个数:10 * 4 + 1 = 41。注:当use_bias=False时,参数个数为40:
乘法次数:10 * 4 * (9 * 5)= 1800
加法次数:9 * 5 = 45
2.2 单通道多卷积核
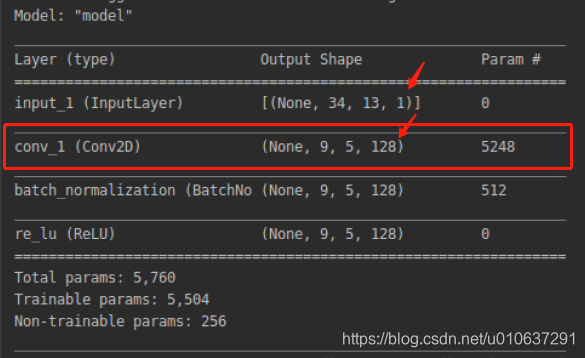
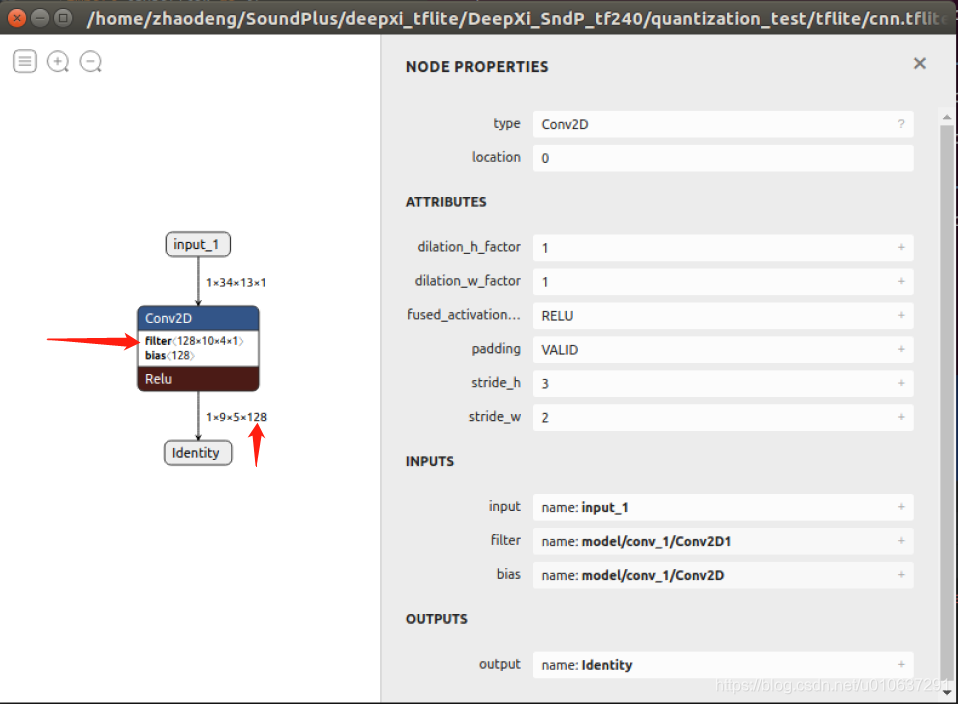
单通道输入:[1, 34, 13, 1]的单通道矩阵,即输入的batch_size = 1,width = 34, height = 13, channels = 1
多卷积核:
filters=128, 128个卷积核
kernel_size=[10, 4]
use_bias=True:一个偏置项
strides=[3, 2]:卷积移动步长
padding=“VALID”:不进行padding
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=128, kernel_size=(10, 4), strides=(3, 2), padding='VALID',
dilation_rate=(1, 1), use_bias=False, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite")
return model
def convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite"):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(filename_tflite, "wb").write(tflite_model)
则:
输出:ceil((34-10+1)/3)=9, ceil((13-4+1)/2)=5
即[1, 9, 5, 128]: batch_size=1, width=9, height=5, channels=128
参数个数:(10 * 4 + 1 )* 128 = 5248。注:当use_bias=False时,参数个数为10 * 4 * 128 = 5120:
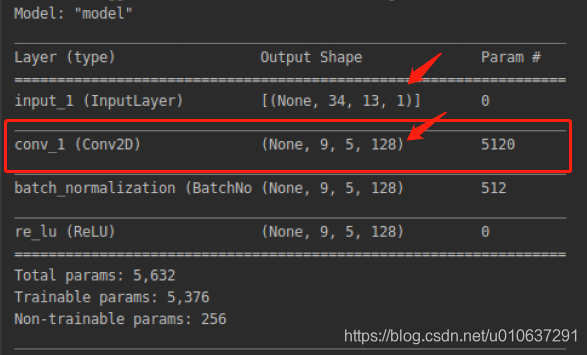
乘法次数:10 * 4 * (9 * 5)*128 = 921600
加法次数:9 * 5 * 128 = 5760
2.3 多通道单卷积核
多通道输入:[1, 9, 5, 128]的多通道矩阵,即输入的batch_size = 1,width = 9, height = 5, channels = 128
单卷积核:
filters=1, 1个卷积核
kernel_size=[3, 3]:其实是[3, 3, 128]
use_bias=True:一个偏置项
strides=[1, 1]:卷积移动步长
padding=“VALID”:不进行padding
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=128, kernel_size=(10, 4), strides=(3, 2), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
## HERE:filters=1
net = keras.layers.Conv2D(filters=1, kernel_size=(3, 3), strides=(1, 1), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_2')(net)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite")
return model
def convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite"):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(filename_tflite, "wb").write(tflite_model)
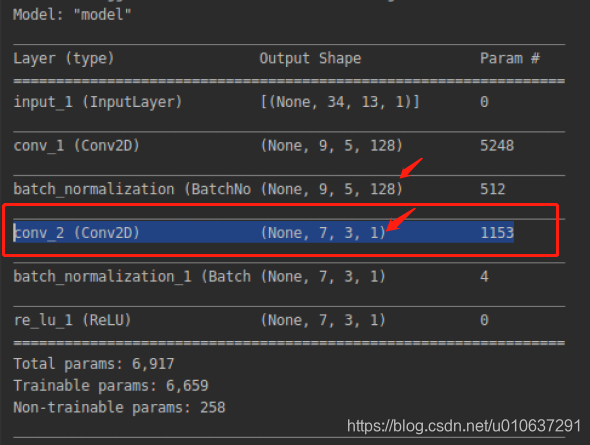
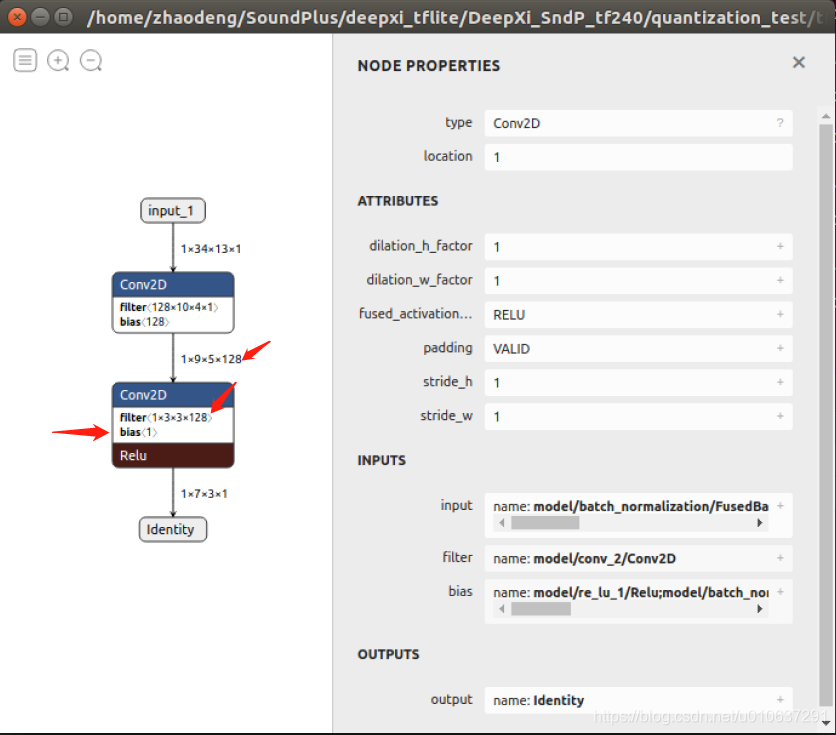
则:
输出:ceil((9-3+1)/1)=7, ceil((5-3+1)/1)=3
即[1, 7, 3, 1]: batch_size=1, width=9, height=5, channels=1
参数个数:3 * 3 * 128 + 1 = 1153。注:当use_bias=False时,参数个数为1152。
乘法次数: 3 * 3 * (7 * 3)* 128 = 24192
加法次数:7 * 3 = 21
2.4 多通道多卷积核
多通道输入:[1, 9, 5, 128]的多通道矩阵,即输入的batch_size = 1,width = 9, height = 5, channels = 128
多卷积核:
filters=128, 128个卷积核
kernel_size=[3, 3]:其实是[3, 3, 128]
use_bias=True:一个偏置项
strides=[1, 1]:卷积移动步长
padding=“VALID”:不进行padding
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=128, kernel_size=(10, 4), strides=(3, 2), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
## HERE:filters=128
net = keras.layers.Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_2')(net)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite")
return model
def convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite"):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(filename_tflite, "wb").write(tflite_model)
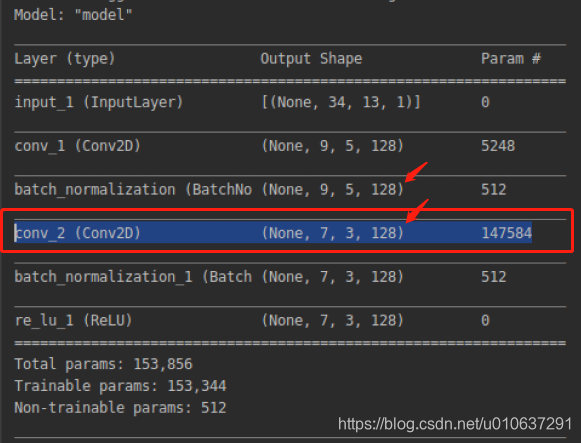
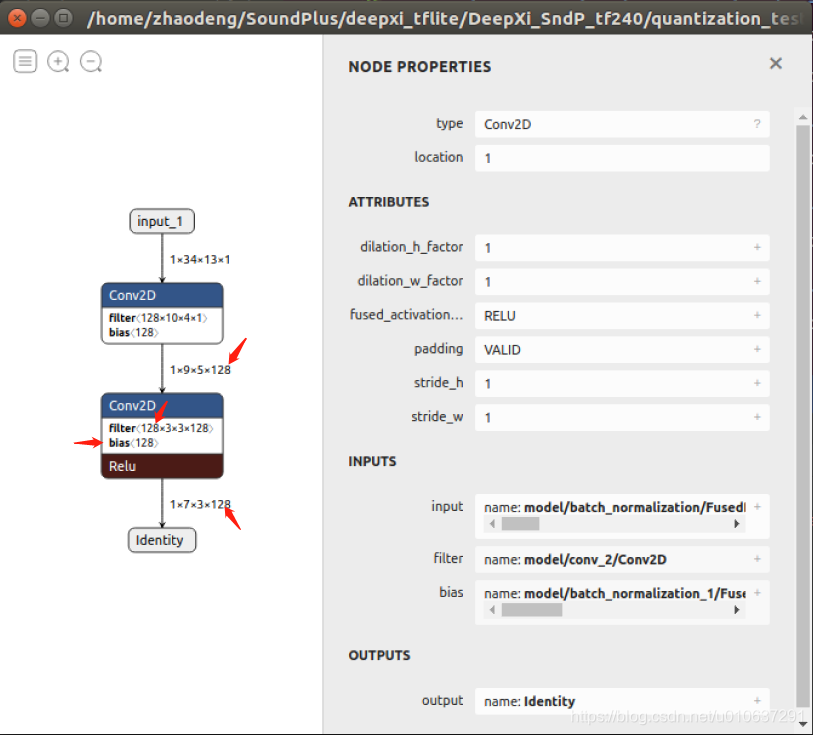
则:
输出:ceil((9-3+1)/1)=7, ceil((5-3+1)/1)=3
即[1, 7, 3, 128]: batch_size=1, width=9, height=5, channels=128
参数个数:(3 * 3 * 128 + 1 )* 128 = 147584 。注:当use_bias=False时,参数个数为(3 * 3 * 128 )* 128 = 147456 。
乘法次数: 3 * 3 * (7 * 3)* 128 * 128 = 3096576
加法次数:7 * 3 * 128 = 2688
3. Depthwise Seperable Conv(多通道多卷积核)
ref: https://zhuanlan.zhihu.com/p/80041030
多通道多卷积核的卷积操作应该是:
输入: [batch_size, width, height, channels],
卷积核个数:filters
卷积核尺寸:[kernel_width, kernel_height]
则:
卷积核shape: [kernel_width, kernel_height, channels, filters]
如上面的多通道多卷积核 的实现示例中:
输入: [batch_size, width, height, channels]=[1, 9, 5, 128]
卷积核个数:filters=128
卷积核尺寸:[kernel_width, kernel_height]=[3, 3]
卷积核shape: [kernel_width, kernel_height, channels, filters]=[3, 3, 128, 128]
该多通道多卷积核的卷积操作,可分为多个多通道单卷积核的卷积操作,即:
[width, height, channels]矩阵与[kernel_width, kernel_height, channels]矩阵的卷积。
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
3.1 Depthwise Convolution
Depthwise Convolution即将多个通道的输入数据([width, height, channels])与多个单卷积核([kernel_width, kernel_height, channels])进行依次矩阵点乘,即:
如下图所示,3个通道的输入数据,依次与3个单卷积核进行矩阵点乘,得到一个3维矩阵。即得到[output_width, output_height, channels]的矩阵,其中
output_width = ceil((width - kernel_width + 1) / stride_width)
output_height = ceil((height - kernel_height + 1) / stride_height)
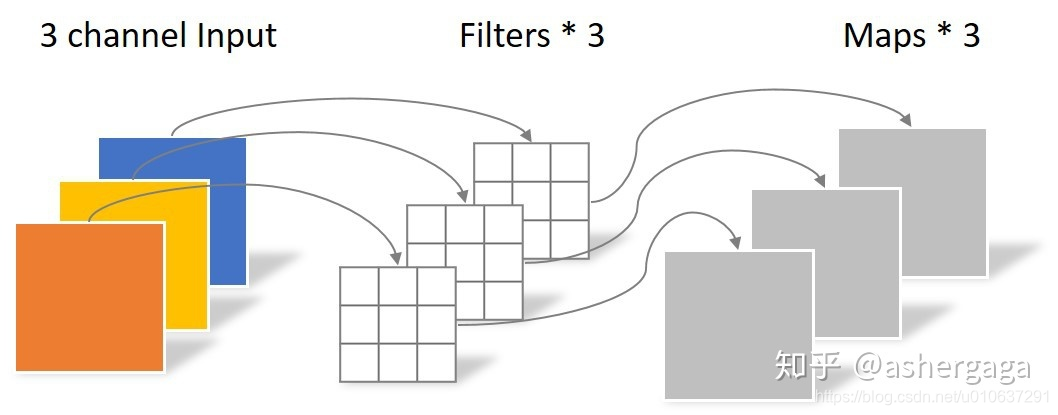
概述:
多通道输入:多通道数据[batch_size, width, height, channels]
多个单卷积核:[kernel_width, kernel_height, channels], 和多个偏置项
输出:多通道数据[batch_size, output_width, output_height, channels]
参数个数:(kernel_width * kernel_height + 1 ) * channels
乘法次数:kernel_width * kernel_height * (output_width * output_heigh)* channels
加法次数:output_width * output_heigh * channels
3.2 Pointwise Convolution
Pointwise Convolution则将这些Feature map进行组合生成新的Feature map。Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×channels,channels为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
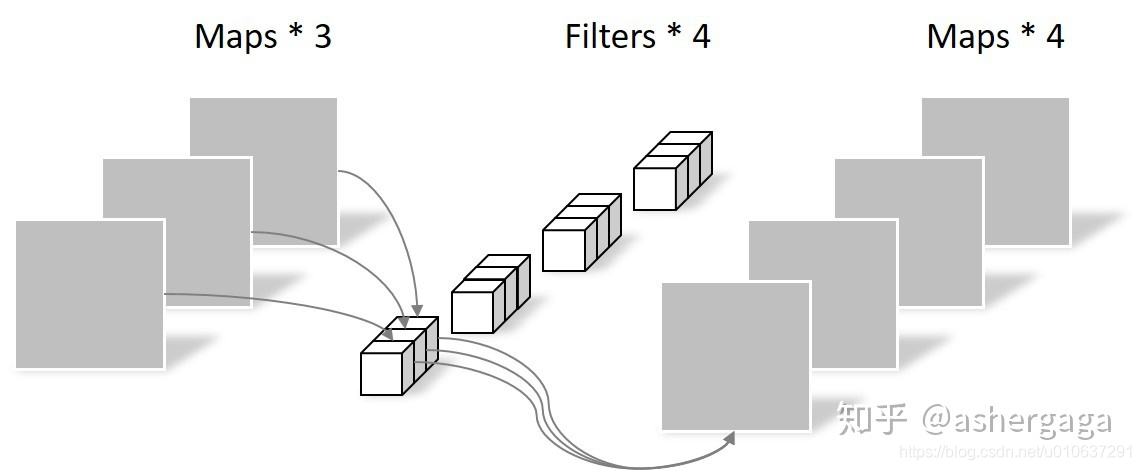
概述:
多通道输入:多通道数据[batch_size, width, height, channels]
多卷积核:[filters, 1, 1, channels], 和filters个偏置项
输出:多通道数据 [batch_size, width, height, channels]
参数个数:(1 * 1 * channels + 1) * filters
乘法次数:1 * 1 * channels (width * heigh) filters
加法次数:width * heigh * filters
3.3 实现示例
1)Depthwise Convolution:
多通道输入:[1, 9, 5, 128]的多通道矩阵,即输入的batch_size = 1,width = 9, height = 5, channels = 128
多个单卷积核:
多个卷积核,但是depthwise没有filters参数的设置,即默认filters=channels
kernel_size=[3, 3]:shape即[3, 3, 128]
use_bias=True:channels个偏置项
strides=[1, 1]:卷积移动步长
padding=“VALID”:不进行padding
输出:多通道数据[batch_size, output_width, output_height, channel],即[1, 7, 3, 128]
参数个数:(kernel_width * kernel_height + 1)* channels = (3 * 3 + 1)* 128 = 1280
乘法次数:kernel_width * kernel_height * (output_width * output_heigh)* channels = 3 * 3 * 7 * 3 * 128 = 24192
加法次数:output_width * output_heigh * channels = 7 * 3 * 128 = 2688
2)Pointwise Convolution:
多通道输入:[1, 7, 3, 128]的多通道矩阵,即输入的batch_size = 1,width = 7, height = 3, channels = 128
多卷积核:
filters=128,128个卷积核
kernel_size=[1, 1]:shape即[1, 1, 128]
use_bias=True:一个偏置项
strides=[1, 1]:卷积移动步长
padding=“VALID”:不进行padding
输出:多通道数据 [batch_size, width, height, channels] = [1, 7, 3, 128]
参数个数:(1 * 1 * channels + 1) * filters = 16512
乘法次数:1 * 1 * channels (width * heigh) filters = 344064
加法次数:width * heigh * filters = 2688
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=128, kernel_size=(10, 4), strides=(3, 2), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
# # Conv2D
# net = keras.layers.Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='VALID',
# dilation_rate=(1, 1), use_bias=True, name='conv_2')(net)
# net = keras.layers.BatchNormalization()(net)
# outputs = keras.layers.ReLU()(net)
# Depthwise convolution
net = keras.layers.DepthwiseConv2D(kernel_size=(3, 3), strides=(1, 1), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_depthwise')(net)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
# Pointwise convolution
net = keras.layers.Conv2D(filters=128, kernel_size=(1, 1), strides=(1, 1), padding='VALID',
dilation_rate=(1, 1), use_bias=True, name='conv_pointwise')(net)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite")
return model
def convert_keras_to_tflite_dynamic_range(model, filename_tflite="./tflite/cnn.tflite"):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(filename_tflite, "wb").write(tflite_model)
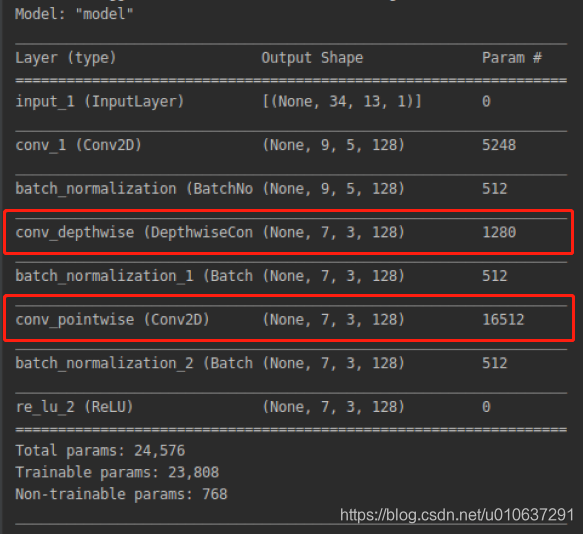
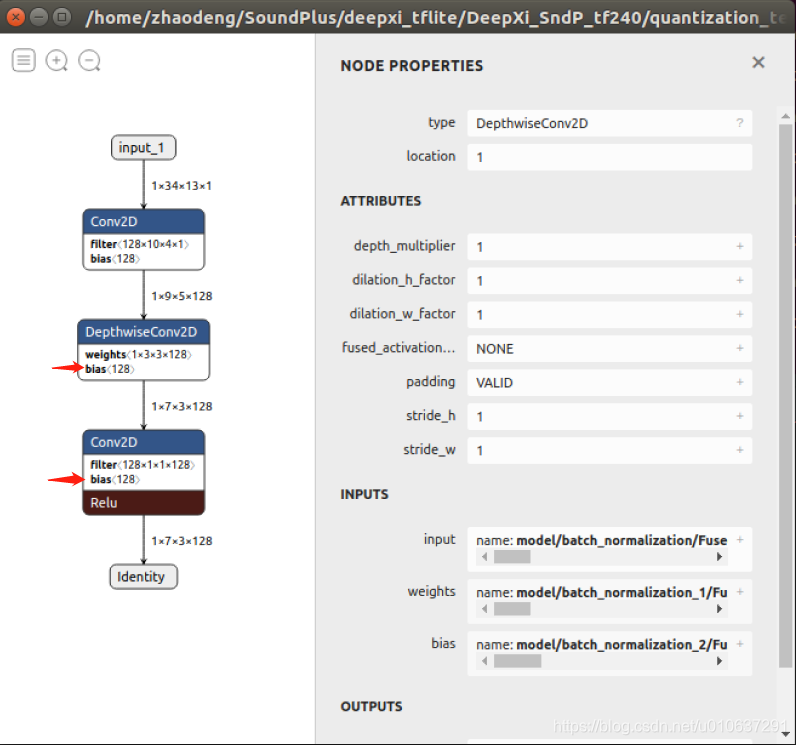
3.4 Depthwise Seperable Conv 与Conv 对比
参数个数
Conv2D: 147584
Depthwise Seperable Conv : 1280 + 16512=17792
乘法次数
- Conv2D:
乘法次数: 3 * 3 * (7 * 3)* 128 * 128 = 3096576
加法次数:7 * 3 * 128 = 2688
- Depthwise Seperable Conv :
Depthwise conv:
乘法次数:kernel_width * kernel_height * (output_width * output_heigh)* channels = 3 * 3 * 7 * 3 * 128 = 24192
加法次数:output_width * output_heigh * channels = 7 * 3 * 128 = 2688
Pointwise conv:
乘法次数:1 * 1 * channels (width * heigh) filters = 344064
加法次数:width * heigh * filters = 2688
可看出Depthwise Seperable Conv 比普通的Conv可用更少的参数量和更少的计算量实现相同的特征学习。