目录
3.4 分层聚类,Hierarchical clustering
0. 摘要
本文是对NILM2018的一篇论文的阅读笔记。注意在下文中“该论文/本论文”和“本文”是指向不同的对象。
Lucas Pereira,Nuno Nunes: An Experimental Comparison of Performance Metrics for Event Detection Algorithms in NILM
在该论文中对23种性能度量应用于NILM中事件检测算法进行基于实验的分析,分析各种性能度量之间关系并进行了聚类分析。分析结果表明,相比其它传统的机器学习问题,这些性能度量应用于NILM事件检测算法的表现迥然不同。这些差异主要来源于事件检测问题中的天然的非平衡的特性(skewedness?),即正确判断的数量(True Positives and True Negatives)远远高于错误判断的数量(False Positives and False Negatives)
1. 背景介绍
性能度量(Performance metrics)主要分为两类:
- 用于事件检测(energy detection: ED)的性能度量
- 用于能量估计(energy estimation: EE)的性能度量
ED性能度量衡量的是NILM算法跟踪随时间变化的总功率变化的能力;EE性能度量衡量的是负荷分解的准确度,每时每刻的各种电器的实际消耗功率值与分解结果之间的差异。
本论文的焦点是关于NILM中事件检测算法的性能度量的。作者研究了在4种数据集上23种事件检测性能度量与5种事件检测算法相结合的工作状况。
实验分以下三个步骤:
步骤1:在4种数据集上,对5种算法进行参数扫描评估
步骤2:分别计算以上各种条件下的性能度量值
步骤3: 对所得的所有的性能度量值进行相关性分析,重点考察了线性(Pearson)和非线性(Spearman)相关性。进一步还使用hierarchical clustering和dendrograms(树形图)等手段进行了进一步的度量相关性分析。
2. 算法、数据集和性能度量
2.1 性能度量
本实验中采用以下23种面向事件检测的性能度量
[1] Confusion matrix based metrics(论文中说是13种,实际上所列是14种。其中,最后一个DPSperc似乎应该在后面的实验分析中没有采用):
- Accuracy(A)
- Error-rate (E)
- Precision (P)
- Recall (R)
- F0.5
- F1
- F2
- Standardized Mathews Correlation Coefficient (SMCC)
- False Positive Rate (FPR)
- True Positive Percentage (TPP)
- False Positive Percentage (FPP)
- Precision-Recall Distance to Perfect Score (DPS_PR)
- TPR-FPR Distance to Perfect Score (DPS_Rate)
- TPP-FPP Distance to Perfect Score (DPS_Perc)
[2] Area Under Curve metrics: Four variations of ROC-AUC are selected
(1) the Wilcoxon based ROC-AUC (WAUC)
(2) the Wilcoxon based ROC-AUC Balanced (WAUCB)
(3) the Geometric Mean AUC (GAUC)
(4) the Biased AUC (BAUC)
[3] Domain specific metrics (DSM)
(1) the Total Power Change due to False Positives (TPC_FP )
(2) the Total Power Change due to False Negatives (TPC_FN)
(3) the Average Power Change due to False Positives (APC_FP )
(4) the Average Power Change due to False Negatives (APC_FN)
(5) the TPC Distance to Perfect Score (DPStpc)
(6) the APC Distance to Perfect Score (DPSapc).
2.2 事件检测算法
本论文考察了以下5种事件检测算法:

2.3 数据集
本论文考察了以下4种数据集:
(1) BLUED PA
(2) BLUED PB
(3) UK-DALE H1
(4) UK-DALE H2
当然,这里所说的4种数据集是作者的说法。前两种来自于BLUED数据集,分别是A相的(有功)功率数据和B相的(有功)功率数据。后两种都来自于UK-DALE数据集,分别是House1和House2的数据。
由于UK-DALE数据中原本没有事件的时间戳信息,所以作者为了进行这项实验,手动(manually,应该是写一个脚本自动进行吧,真要纯人工标注还不得把人标废了)标注了事件的时间戳信息。作者判断功率变化事件的基准是功率变化在30W之上(chenxy:这个估计跟应用场景以及性能指标要求其实是有关系的),即判定为有效的事件。
以上4个数据集的一些统计数据如下表所示。

上表中,BLUED的A相和B相的事件数分别为887、1562,但是原始数据集中给出的A相和B相的事件数应该分别是904,1578,估计是有些事件的功率变化量少于上面作者所定的30W的门限被作者剔除了?
从表中可以看出,各种事件的功率变化量其实都相当大,功率变化量从30瓦左右到5、600瓦以上。其次,两个事件之间的最短间隔时间很短,比如说UK-DALE-H1的数据25%-百分位是4秒,这意味着有25%的事件间隔在4秒以内,对于事件检测来说要求分辨出相隔如此近的事件不是一件容易的事情。
3. 研究方法
实验分以下三个步骤:
步骤1:在4种数据集上,对5种算法进行参数扫描评估
步骤2:分别计算以上各种条件下的性能度量值
步骤3: 对所得的所有的性能度量值进行相关性分析,重点考察了线性(Pearson)和非线性(Spearman)相关性。进一步还使用hierarchical clustering和dendrograms(树形图)等手段进行了进一步的度量相关性分析。
以下分别具体描述。
3.1 训练与测试
要点1:如上所述,定义30W功率变化量为事件判断门限
要点2:采用有用功率作为检测输入数据
要点3:总共训练了47950中模型,每个模型分别在4个数据集上训练和测试得到109800个{模型,数据}组合。论文中没有说明47950和109800怎么来的。猜测对于同一算法,不同的算法参数就算是一个模型。每种模型也不是完全等同地4个数据集上训练(如果是的话就应该是4*47950=191800了)。不过,模型数以及{模型,数据}组合是如此之大,统计性足够了。哪个算法或者哪个模型少训练几次也无关紧要。
3.2 性能度量计算
对于每一个{模型,数据}组合,分别计算性能度量值。
首先自然是TP(True Positive), FP(False Positive), TN(True Negative), FN(False Negative).
其中Positive表示有事件,Negative表示无事件。TP就表示在某一时刻有事件而且模型也的确在该时刻检测到了事件,余者依此类推。
但是,NILM中的事件检测问题跟传统机器学习的分类问题。事件检测本身除了”有”和”无”外,还有一个时间维度信息,即事件发生在什么时刻。要检测到的事件的发生时刻与真实事件发生的时刻也一致才能算式TP。但是略有偏差算不算呢?略有偏差算的话,那偏差到多大就不算呢?这个问题必须先确定一个判断基准。
在本论文中,先确定了事件发生时刻的tolerance interval(间隔偏差容限),只有检测到的事件发生时刻在真实事件时刻(GT: Ground Truth)左右的如下所示的区间范围内,才认为是TP:

Tol的设定区间为[0,3s],按如下可变步长进行设定:

(chenxy: 这个地方有些含糊:(1) \tau集合中的元素值的前4项为绝对的数值,可是单位是什么呢?(2)按可变步长是什么意思呢?两个tol之间的差距可能是以上集合中的任意一个,随机选择?)
接下来,同样由于事件有时间维度的信息,创建混淆矩阵也与传统机器学习的分类模型的不太一样。
- TP的统计。从前向后遍历扫描每个真实事件(GT),在它的由以上式区间范围内的检测事件中,最靠近它的或者是(当存在等距离的两个检测事件)较早检测到的那一个作为与该GT匹配的事件。其它的事件则要与下一个GT进行匹配判断。
- FN。如果一个GT的间隔偏差容限范围内没有检测事件,则判定为一个FN
- FP。未找到匹配的GT的检测事件判定为一个FP
- TN。总的样本数(等价于任何可能发生事件的时刻数)减去(TP+FN+FP)的都算TN
注意,以上TN的定义决定了TN的肯定远远大于所有其它三项的总数之和。这可以看作是摘要中所说的事件检测问题的不平衡属性的最主要原因。当然,TP的数量通常也远远大于FP+FN之和。
3.3 Pairwise correlation
接下来就是对所有收集到的性能度量值进行(每对之间的,pairwise)皮尔逊和斯皮尔曼相关系数的计算。总共27个度量值(前面提及的23个,加上TP/TN/FP/FN),共(27*26)/2=351,即351对皮尔逊相关系数、351对斯皮尔曼相关系数。
每个模型在每个数据集上评估运行10次,每次用不同的tolerance,因此针对皮尔逊相关和斯皮尔曼相关分别得到200个相关矩阵(200 = 10 tolerance * 5 algorithms * 4 datasets)。基于这些相关矩阵,进一步计算跨数据集相关矩阵(cross dataset correlation matrices)。
这里有一些疑问:
疑问1:上面式(2)中其实只有9种tolerance,所以这里的10 tolerance是笔误?
疑问2:前面提过一共尝试了47950种模型(应该是5种算法,每种算法又有很多种参数组合)。这47950跟上面的200=10*5*4又是啥关系呢?是不是说从那47950种模型中最后给每种算法择优选择了一种最优的(参数)模型用于后面的评估?原论文语焉不详。。。毕竟只是一个workshop的论文?
3.4 分层聚类,Hierarchical clustering
基于以上所得的跨数据集相关矩阵进一步利用分层聚类技术进行了聚类分析。为此我们首先定义了dissimilarity如下所示:

其中,|C|表示每对度量之间的相关系数的绝对值。D则表是dissimilarity distance,越大就表示越不相似。
其次,我们采用average-group distance定义了linkage function,如下所示:
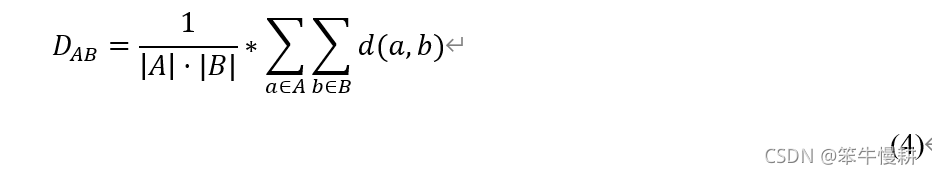
4. 实验结果、解读和讨论
欲知后事如何,且听下回分解^-^(写累了,歇一会儿)
关于斯皮尔曼相关系数可以参考:
斯皮尔曼相关系数介绍及其计算例![]() https://blog.csdn.net/chenxy_bwave/article/details/121427036皮尔逊相关系数的5个假设
https://blog.csdn.net/chenxy_bwave/article/details/121427036皮尔逊相关系数的5个假设![]() https://blog.csdn.net/chenxy_bwave/article/details/121435591
https://blog.csdn.net/chenxy_bwave/article/details/121435591