分布式存储极致性能Redis
接上一部分
一、SRM(SpringBoot+Redis+Mybatis)(重写Redis的序列化)的缓存实战
1.1 新增Redis和Swagger2的配置类
RedisConfig.java
@Configuration
@Slf4j
public class RedisConfig {
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory) {
RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式为json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
SwaggerConfig.java
@Configuration
@EnableWebMvc
public class SwaggerConfig {
@Value("true")
private Boolean enabled;
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.enable(enabled)
.select()
.apis(RequestHandlerSelectors.basePackage("com.hmx.redis"))//你自己的package
.paths(PathSelectors.any())
.build();
}
public ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("redis6" + "\t" + new SimpleDateFormat("yyyy-MM-dd").format(new Date()))
.description("大厂redis")
.version("1.0")
.termsOfServiceUrl("https://www.hmx123.xyz/")
.build();
}
}
1.2 编写service层和controller层并编写dto层
UserService.java
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
public void addUser(User user) {
//1. 先插入mysql并成功
int i = userMapper.insertSelective(user);
if (i > 0) {
//2. 需要确保mysql数据插入成功再查询一次mysql中的数据
User user1 = userMapper.selectByPrimaryKey(user.getId());
//3. 将捞出的User存进redis,完成新增功能的数据一致性。
String key = CACHE_KEY_USER + user.getId();
redisTemplate.opsForValue().set(key, user);
}
}
public void deleteUser(Integer id) {
int i = userMapper.deleteByPrimaryKey(id);
if (i > 0) {
String key = CACHE_KEY_USER + id;
redisTemplate.delete(key);
}
}
public void updateUser(User user) {
int i = userMapper.updateByPrimaryKeySelective(user);
if (i > 0) {
//2. 需要确保mysql数据插入成功再查询一次mysql中的数据
User user1 = userMapper.selectByPrimaryKey(user.getId());
//3. 将捞出的User存进redis,完成新增功能的数据一致性。
String key = CACHE_KEY_USER + user.getId();
redisTemplate.opsForValue().set(key, user);
}
}
public User findUserById(Integer id) {
User user = null;
String key = CACHE_KEY_USER + id;
//1. 先从redis中查询数据,如果有直接返回结果,如果没有再去查询mysql
user = (User)redisTemplate.opsForValue().get(key);
if (user == null) {
//2. redis中无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
//3.1 redis+mysql 都无数据
return user;
} else {
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key, user);
}
}
return user;
}
}
UserController.java
@Api(value = "用户User接口")
@RestController
@Slf4j
@RequestMapping("/user")
public class UserController {
@Resource
private UserService userService;
@ApiOperation("数据库新增5条记录")
@RequestMapping(value = "/add", method = RequestMethod.POST)
public void addUser() {
for (int i = 0; i < 5; i++) {
User user = new User();
user.setUsername("zzyy" + i);
user.setPassword(IdUtil.simpleUUID().substring(0, 6));
//[0,2)
user.setSex((byte) new Random().nextInt(2));
userService.addUser(user);
}
}
@ApiOperation("删除一条记录")
@RequestMapping(value = "/delete/{id}", method = RequestMethod.POST)
public void deleteUser(@PathVariable Integer id) {
userService.deleteUser(id);
}
@ApiOperation("修改一条记录")
@RequestMapping(value = "/update", method = RequestMethod.POST)
public void updateUser(@RequestBody UserDTO userDTO) {
User user = new User();
BeanUtils.copyProperties(userDTO, user);
userService.updateUser(user);
}
@ApiOperation("查询一条记录")
@RequestMapping(value = "/find/{id}", method = RequestMethod.GET)
public User findUserById(@PathVariable Integer id) {
return userService.findUserById(id);
}
}
UsrtDTO.java
@NoArgsConstructor
@AllArgsConstructor
@Data
@ApiModel(value = "用户信息")
public class UserDTO {
@ApiModelProperty(value = "用户ID")
private Integer id;
@ApiModelProperty(value = "用户名")
private String username;
@ApiModelProperty(value = "密码")
private String password;
@ApiModelProperty(value = "性别 0=女 1=男")
private Byte sex;
@ApiModelProperty(value = "删除标志,默认0不删除,1删除")
private Byte deleted;
@ApiModelProperty(value = "更新时间")
private Date updateTime;
@ApiModelProperty(value = "创建时间")
private Date createTime;
}
1.3 启动项目使用swagger进行测试
swagger访问地址: http://localhost:5555/swagger-ui/index.html

1.3.1 测试新增



1.3.2 测试删除

1.3.3 测试修改



如果查看redis信息时显示的value是被压缩过而不是原始的key,value,可以在连接客户端时,加上–raw参数
redis-cli --raw

1.3.4 测试查询

最后可以测试一下把redis中数据删掉,然后再通过请求查询数据,数据是否会被回写到redis中。
1.4 优化(防止缓存击穿)
UserService.java
public User findUserById(Integer id) {
User user = null;
String key = CACHE_KEY_USER + id;
//1. 先从redis中查询数据,如果有直接返回结果,如果没有再去查询mysql
user = (User)redisTemplate.opsForValue().get(key);
if (user == null) {
//2. 对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis
//等待一下,避免击穿mysql,这里采用了类似DCL单例的思想
synchronized (UserService.class) {
user = (User) redisTemplate.opsForValue().get(key);
//3. 二次查redis还是null
if (user == null) {
//4. 查询mysql拿数据
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
} else {
//5. mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key, user, 7L, TimeUnit.DAYS);
}
return null;
}
}
}
return user;
}
二、redis经典五种数据类型介绍及落地运用
2.1 redis中的所有数据类型
- String(字符类型)
- Hash(散列类型)
- List(列表类型)
- Set(集合类型)
- SortedSet(有序集合类型,简称zset)
- Bitmap(位图)
- HyperLogLog(统计)
- GEO(地理)
- Stream(简单了解即可)(使用Redis作为MQ时用到的东西,但是基本上不会用redis作为MQ使用的)
2.2 redis注意事项及使用说明
- 命令不区分大小写,key区分大小写
- help @类型名词可以查看该类型所有的命令信息
2.3 redis中各个数据类型的应用场景
2.3.1 String
- 抖音无线点赞某个视频或者商品,点一下加一次
- 秒杀系统预减库存
2.3.2 Hash
JD购物车早期



2.3.3 list
- 微信公众号订阅的消息(一个人关注多个公众号)
- 商品评论列表(key是商品的id, value是商品评论信息商品编号为1001的商品品论)

2.3.4 set
- 微信抽奖小程序


2. 微信朋友圈点赞


3. 微博好友关注社交关系(共同关注的人)
4. QQ内推荐可能认识的人
zset(向有序集合中加入一个元素和该元素的分数)
- 根据商品销售对商品进行排序显示

- 抖音热搜


2.4 微信文章阅读量统计案例
- ArticleController.java
@RestController
@Slf4j
@Api(value = "喜欢的文章接口")
public class ArticleController
{
@Resource
private ArticleService articleService;
@ApiOperation("喜欢的文章,点一次加一个喜欢")
@RequestMapping(value ="/view/{articleId}", method = RequestMethod.POST)
public void likeArticle(@PathVariable(name="articleId") String articleId)
{
articleService.likeArticle(articleId);
}
}
- ArticleService.java
@Service
@Slf4j
public class ArticleService
{
public static final String ARTICLE = "article:";
@Resource
private StringRedisTemplate stringRedisTemplate;
public void likeArticle(String articleId)
{
String key = ARTICLE+articleId;
Long likeNumber = stringRedisTemplate.opsForValue().increment(key);
log.info("文章编号:{},喜欢数:{}",key,likeNumber);
}
}
测试


结论
中小厂可以用,QPS特别高的大厂不可以用
三、redis新类型bitmap/hyperloglog/GEO
3.1 面试题
- 手机App中的每天的用户登录信息: 1天对应1系列用户ID或移动设备ID;
- 电商网站上商品的用户评论列表: 1个商品对应了1系列的评论
- 用户在手机App上的签到打卡信息: 1天对应1系列用户的签到记录;
- 应用网站上的网页访问信息: 1个网页对应1系列的访问点击。
- 在移动应用中,需要统计每天的新增用户数和第二天的留存用户数
- 在电商网站的商品评论中,需要统计一个月内连续打卡的用户数
- 在签到打卡中,需要统计独立访客(UniqueVistor,UV)量
痛点
类似今日头条、抖音、淘宝这样的用户访问级别都是亿级的,请问如何处理?
3.2 亿级系统中常见的四种统计
- 聚合统计
- 统计多个集合元素的聚合结果,就是前面讲过的==交集并集等集合统计
- 交并差集和聚合函数的应用
- 排序统计
问题: 抖音视频最新评论留言的场景,请你设计一个展现列表?
list, zset
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用ZSet
list: 每个商品评价对应一个List集合,这个List包含了对这个商品的所有评论,而且会按照评论时间保存这些评论,**每来一个新评论就用LPUSH命令把它插入到List的队头。但是如果再演示第二页前,又产生了一个新评论,第2页的评论不一样了。原因: **
List是通过元素在List中的位置排序的,当有一个新元素插入时,原先的元素在List中的位置都后移了一位,原来在第一位的元素现在排在了第2位,当LRANGE读取时,就会读到旧元素。
zset:

- 二值统计
集合元素的取值就只有0和1两种。
在钉钉上班签到打卡的场景中,我们只用记录有签到(1)或没签到(0)
见 bitmap - 基数排序
统计一个集合中不重复元素的个数
3.3 bitmap(位图)
3.3.1 是什么?
Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。(PS:划重点 节省存储空间)

说明: 用String类型作为底层数据结构实现的一种统计二值状态的数据类型
位图本质是数组,他是基于String数据类型的按位的操作。该数组由多个二进制为组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是2^32位,他可以极大的基于存储空间,使用512M内存就可以存储42.9亿的字节信息(2^32=4294967296)
一句话: 由0和1状态表现的二进制位的bit数组
位图详细介绍
3.3.2 能干嘛?
- 用于状态统计: Y、N,类似AtomicBoolean
- 看需求
- 用户是否登录过
- 电影、广告是否被点击播放过
- 钉钉打卡上下班,签到统计
- 大厂真实案例
- 日活统计
- 连续签到打卡
- 最近一周的活跃用户
- 统计指定用户一年之中的登录天数
- 某用户按照一年365天,那几天登录过?哪几天没有登录?全年中登录的天数共计多少?
3.3.3 案例(京东签到领京豆)
3.3.3.1 需求说明

3.3.3.2 小厂方法,传统mysql方式
- 建表
drop table user_sign;
CREATE TABLE user_sign (
keyid BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT,
user_key VARCHAR (200), #京东用户ID
sign_date DATETIME, #签到日期(20210618)
sign_count INT# 连续签到天数
)
INSERT INTO user_sign ( user_key, sign_date, sign_count ) VALUES ( '20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx', '2020-06-18 15:11:12', 1 );
SELECT
sign_count
FROM
user_sign
WHERE
user_key = '20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
AND sign_date BETWEEN '2020-06-17 00:00:00'
AND '2020-06-18 23:59:59'
ORDER BY
sign_date DESC
困难和解决思路:
方法正确但是难以落地实现,签到用户量较小时这么设计能行,但京东这个体量的用户(估算3000W签到用户,一天一条数据,一个月就是9亿数据)对于京东这样的体量,如果一条签到记录对应着当日用记录,那会很恐怖…
如何解决这个痛点?
1 一条签到记录对应一条记录,会占据越来越大的空间。
2 一个月最多31天,刚好我们的int类型是32位,那这样一个int类型就可以搞定一个月,32位大于31天,当天来了位是1没来就是0。
3 一条数据直接存储一个月的签到记录,不再是存储一天的签到记录。
3.3.3.3 大厂方法,基于Redis的Bitmaps实现签到日历
在签到统计时,每个用户一天的签到用1个bit位就能表示,一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型
3.3.4 基本命令

setbit: Bitmap的偏移量是从0开始算的
setbit和getbit案例(按照年)
按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。
假如是亿级的系统,
每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
bitmap的底层编码说明,get命令如何操作
- 实际上是二进制的ascill码对应
- redis里用type命令查看bitmap实质是String类型
- man ascii在linux操作系统中查看ascii表
- 设置命令
两个setbit命令对k1进行设置后,对应的二进制串就是0100 0001二进制串就是0100 0001对应的10进制就是65,所以见下图:

strlen: 统计字节数占用多少
bitcount:
1. 全部键里面含有1的有多少个

3. 一年365天,全年天天登陆占用多少字节

bitop
连续2天都签到的用户
加入某个网站或者系统,它的用户有1000W,做个用户id和位置的映射
比如0号位对应用户id:uid-092iok-lkj
比如1号位对应用户id:uid-7388c-xxx

3.4 hyperloglog
3.4.1 名词
UV(Unique Vistor)
独立访客,可以理解为客户端IP
需要去重统计
PV(Page View)
页面浏览量
不用去重
DAU(Daily Active User)
日活跃用户量:
登录了或者使用了某个产品的用户数(去重复登录的用户数)
常用于反应网站、互联网应用或者网络游戏的运营情况
MAU(Monthly Active User)
月活跃用户量:
3.4.2 看需求
- 统计某个网站的UV,统计某个文章的UV
- 用户搜索网站关键词的数量
- 统计用户每天搜索不同词条个数
3.4.3 是什么
去重复统计功能的基数估计算法-就是HyperLogLog

基数
是一种数据集,去重复后的真实个数

基数统计:
用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
一句话:
去重脱水后的真实数据
3.4.5 HyPerLogLog如何做的?如何演化出来的?
基数统计就是HyperLogLog
3.4.5.1 去重统计的方式
HashSet:
bitmap:
如果数据显较大亿级统计,使用bitmaps同样会有这个问题。
bitmap是通过用位bit数组来表示各元素是否出现,每个元素对应一位,所需的总内存为N个bit。
基数计数则将每一个元素对应到bit数组中的其中一位,比如bit数组010010101(按照从零开始下标,有的就是1、4、6、8)。
新进入的元素只需要将已经有的bit数组和新加入的元素进行按位或计算就行。这个方式能大大减少内存占用且位操作迅速。
But,假设一个样本案例就是一亿个基数位值数据,一个样本就是一亿
如果要统计1亿个数据的基数位值,统计字节数占用多少,内存减少占用的效果显著。
这样得到统计一个对象样本的基数值需要12M。
如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用bitmaps还是不适用大数据量下(亿级)的基数计数场景,
但是bitmaps方法是精确计算的。
结论
样本元素越多内存消耗急剧增大,难以管控+各种慢,
对于亿级统计不太合适,大数据害死人,
办法
概率算法
通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,
通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。
HyperLogLog就是一种概率算法的实现。
3.4.5.2 原理说明
- 只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容。
- 有误差
- 非精确统计
- 牺牲准确率来换取空间,误差仅仅只是0.81%左右
经典面试题
1.为什么redis集群的最大槽数是16384个?
Redis集群并没有使用一致性hash而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。但为什么哈希槽的数量是16384(2^14)个呢?
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。
换句话说值是分布在0~65535之间。那作者在做mod运算的时候,为什么不mod65536,而选择mod16384?
https://github.com/redis/redis/issues/2576

正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。
这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽)。
同时,由于其他设计折衷,Redis集群不太可能扩展到1000个以上的主节点。
因此16k处于正确的范围内,以确保每个主机具有足够的插槽,最多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。请注意,在小型群集中,位图将难以压缩,因为当N较小时,位图将设置的slot / N位占设置位的很大百分比。

(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
3.4.6 基本命令



3.4.7 案例(天猫网站首页以及UV的Redis统计方案)
需求
- UV的统计需要去重,一个用户一天内的多次访问只能算作一次
- 淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
- 每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加
方案
用mysql:
傻xxx
用redis的hash结构存储:

redis的hash结构,技术上没错,但是无法落地,按照天猫、淘宝的体量,一个月60G
用hyperloglog的方案:

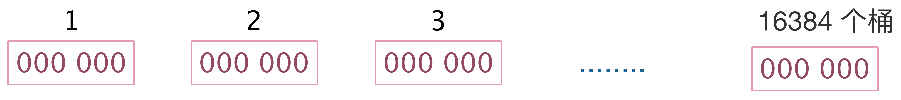
为什么是12Kb?
每个桶取6位,16384*6÷8 = 12kb,每个桶有6位,最大全部都是1,值就是63
代码
HyperLogLogController.java
@Api(value = "案例实战总03:天猫网站首页亿级UV的Redis统计方案")
@RestController
@Slf4j
public class HyperLogLogController {
@Resource
private RedisTemplate redisTemplate;
@ApiOperation("获得ip去重复后的首页访问量,总数统计")
@RequestMapping(value = "/uv",method = RequestMethod.GET)
public long uv() {
//pfcount
return redisTemplate.opsForHyperLogLog().size("hll");
}
}
HyperLogLogService.java
@Service
@Slf4j
public class HyperLogLogService
{
@Resource
private RedisTemplate redisTemplate;
/**
* 模拟有用户来点击首页,每个用户就是不同的ip,不重复记录,重复不记录
*/
@PostConstruct
public void init() {
log.info("------模拟后台有用户点击,每个用户ip不同");
//自己启动线程模拟,实际上产不是线程
new Thread(() -> {
String ip = null;
for (int i = 1; i <=200; i++) {
Random random = new Random();
ip = random.nextInt(256)+"."+random.nextInt(256)+"."+random.nextInt(256)+"."+random.nextInt(256);
Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip);
log.info("ip={},该ip访问过的次数={}",ip,hll);
//暂停3秒钟线程
try {
TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) {
e.printStackTrace(); }
}
},"t1").start();
}
}
测试


3.5 GEO
3.5.1 简介
移动互联网时代LBS应用越来越多,交友软件中附近的小姐姐、外卖软件中附近的美食店铺、打车软件附近的车辆等等,那这种附近各种形形色色的XXX地址位置选择是如何实现的?
地球上的地理位置是使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],只要我们确定一个点的经纬度就可以名曲他在地球的位置。
例如滴滴打车,最直观的操作就是实时记录更新各个车的位置,
然后当我们要找车时,在数据库中查找距离我们(坐标x0,y0)附近r公里范围内部的车辆
使用如下SQL即可:
select taxi from position where x0-r < x < x0 + r and y0-r < y < y0+r
但是这样会有什么问题呢?
1.查询性能问题,如果并发高,数据量大这种查询是要搞垮数据库的
2.这个查询的是一个矩形访问,而不是以我为中心r公里为半径的圆形访问。
3.精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差
3.5.2 Redis在3.2版本以后增加了地理位置的处理
3.5.3 原理
核心思想就是将球体转换为平面,区块转换为一点

主要分为三步
将三维的地球变为二维的坐标
在将二维的坐标转换为一维的点块
最后将一维的点块转换为二进制再通过base32编码
3.5.3.1 GeoHash核心原理解析
https://www.cnblogs.com/LBSer/p/3310455.html
3.5.3.2 地理知识说明
经纬度
经度与纬度的合称组成一个坐标系统。又称为地理坐标系统,它是一种利用三度空间的球面来定义地球上的空间的球面坐标系统,能够标示地球上的任何一个位置。
经线和纬线
是人们为了在地球上确定位置和方向的,在地球仪和地图上画出来的,地面上并线。
和经线相垂直的线叫做纬线(纬线指示东西方向)。纬线是一条条长度不等的圆圈。最长的纬线就是赤道。
因为经线指示南北方向,所以经线又叫子午线。 国际上规定,把通过英国格林尼治天文台原址的经线叫做0°所以经线也叫本初子午线。在地球上经线指示南北方向,纬线指示东西方向。
东西半球分界线:东经160° 西经20°。
经度和维度
经度(longitude):东经为正数,西经为负数。东西经
纬度(latitude):北纬为正数,南纬为负数。南北纬


3.5.3.3 经纬度查询
https://jingweidu.bmcx.com/
http://api.map.baidu.com/lbsapi/getpoint/
3.5.4 基本命令
GEOADD添加经纬度坐标


命令如下:
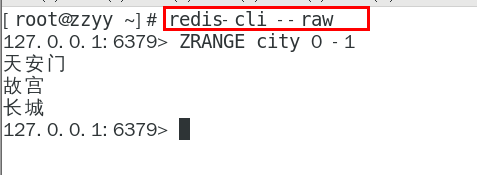
GEOADD city 116.403963 39.915119 “天安门” 116.403414 39.924091 “故宫” 116.024067 40.362639 “长城”
中文乱码如何处理
GEOPOS返回经纬度


GEOHASH返回坐标的geohash表示


- geohash算法生成的base32编码值
- 3维变2维变1维

GEODIST 两个位置之间距离


后面参数是距离单位:
m 米
km 千米
ft 英尺
mi 英里
GEORADIUS(以半径为中心,查找附近的XXX)
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大
COUNT 限定返回的记录数。
当前位置(116.418017 39.914402),阳哥在王府井

GEORADIUSBYMEMBER


3.5.5 案例(美团地图位置附近的酒店推送)
3.5.5.1 需求分析
- 微信附近的人或者一公里以内的各种营业厅、加油站、理发店、超市…
- 找个单车
- 附近的酒店
3.5.5.2 架构设计
- Redis的新类型GEO

3.5.5.3 代码
关键点:

@RestController
public class GeoController
{
public static final String CITY ="city";
@Autowired
private RedisTemplate redisTemplate;
@ApiOperation("新增天安门故宫长城经纬度")
@RequestMapping(value = "/geoadd",method = RequestMethod.POST)
public String geoAdd()
{
Map<String, Point> map= new HashMap<>();
map.put("天安门",new Point(116.403963,39.915119));
map.put("故宫",new Point(116.403414 ,39.924091));
map.put("长城" ,new Point(116.024067,40.362639));
redisTemplate.opsForGeo().add(CITY,map);
return map.toString();
}
@ApiOperation("获取地理位置的坐标")
@RequestMapping(value = "/geopos",method = RequestMethod.GET)
public Point position(String member) {
//获取经纬度坐标
List<Point> list= this.redisTemplate.opsForGeo().position(CITY,member);
return list.get(0);
}
@ApiOperation("geohash算法生成的base32编码值")
@RequestMapping(value = "/geohash",method = RequestMethod.GET)
public String hash(String member) {
//geohash算法生成的base32编码值
List<String> list= this.redisTemplate.opsForGeo().hash(CITY,member);
return list.get(0);
}
@ApiOperation("计算两个位置之间的距离")
@RequestMapping(value = "/geodist",method = RequestMethod.GET)
public Distance distance(String member1, String member2) {
Distance distance= this.redisTemplate.opsForGeo().distance(CITY,member1,member2, RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
/**
* 通过经度,纬度查找附近的
* 北京王府井位置116.418017,39.914402,这里为了方便讲课,故意写死
*/
@ApiOperation("通过经度,纬度查找附近的")
@RequestMapping(value = "/georadius",method = RequestMethod.GET)
public GeoResults radiusByxy() {
//这个坐标是北京王府井位置
Circle circle = new Circle(116.418017, 39.914402, Metrics.MILES.getMultiplier());
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(10);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,circle, args);
return geoResults;
}
/**
* 通过地方查找附近
*/
@ApiOperation("通过地方查找附近")
@RequestMapping(value = "/georadiusByMember",method = RequestMethod.GET)
public GeoResults radiusByMember() {
String member="天安门";
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(10);
//半径10公里内
Distance distance=new Distance(10, Metrics.KILOMETERS);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,member, distance,args);
return geoResults;
}
}
测试






