分布式存储极致性能Redis
一、布隆过滤器BloomFilter
1.1 面试题
现有50亿个电话号码,现有10万个电话号码,
如何要快速准确的判断这些电话号码是否已经存在?
1、通过数据库查询-------实现快速有点难。
2、数据预放到内存集合中:50亿*8字节大约40G,内存太大了。
1.2 是什么?
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
它实际上是一个很长的二进制数组+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。
但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

- 一句话
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在
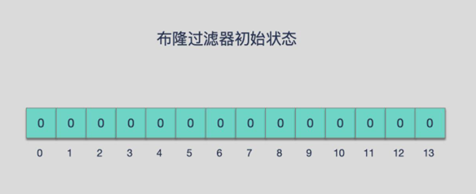
- 本质就是判断具体数据存不存在一个大的集合中
- 布隆过滤器是一种类似set的数据结构,只是统计结果不太准确
1.3 特点考点
- 高效地插入和查询,占用空间少,返回的结果是不确定性的。
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
- 布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
- 误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
结论备注
- 有,是可能有
- 无,是肯定无
1.4 布隆过滤器的使用场景
- 解决缓存穿透
缓存穿透是什么
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透到Mysql数据库
- 黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
1.5 布隆过滤器原理
1.5.1 Java中的传统hash
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值

如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
1.5.2 布隆过滤器实现原理和数据结构
布隆过滤器原理
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
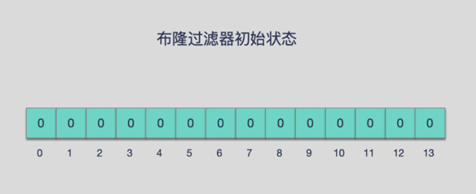
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,
每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
结论:
有,是可能有
无,是肯定无
1.5.3 进一步
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。

查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了
如果这些点,有任何一个为零则被查询变量一定不在,
如果都是 1,则被查询变量很可能存在,
为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。

1.5.4 再说一次(三步骤)
1.5.4.1 初始化
布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0

1.5.4.2 添加
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
例如,我们添加一个字符串wmyskxz

1.5.4.3 判断是否存在
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,
只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在;
如果这几个位置全都是 1,那么说明极有可能存在;
因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;
此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了…

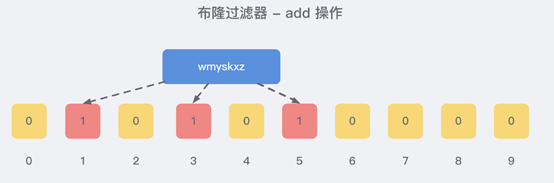
1.5.4.4 布隆过滤器误判率,为什么不要删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,
因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。
如果我们直接删除这一位的话,会影响其他的元素
特性
一个元素判断结果为没有时则一定没有,
如果判断结果为存在的时候元素不一定存在。
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
1.5.5 小总结
- 是否存在
- 有,是很可能有
- 无,是肯定无(可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中)
- 使用时最好不要让实际元素数量远大于初始化数量
- 当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进行
1.6 布隆过滤器优缺点
优点:
高效地插入和查询,占用空间少
缺点:
- 不能删除元素。
因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,
你删除一个元素的同时可能也把其它的删除了。 - 存在误判
不同的数据可能出来相同的hash值
1.7 布谷鸟过滤器(了解)
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。论文《Cuckoo Filter:Better Than Bloom》
作者将布谷鸟过滤器和布隆过滤器进行了深入的对比。相比布谷鸟过滤器而言布隆过滤器有以下不足:
查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数
二、缓存预热+缓存雪崩+缓存击穿+缓存穿透
2.1 缓存雪崩
在某一时刻出现大规模的key失效,导致大量的请求落在数据库上,导致数据库压力过大,可能瞬间就导致数据库宕机。
2.1.1 解决方案
- redis缓存集群高可用实现
- 主从+哨兵
- Redis Cluster
- ehcache本地缓存+Hystrix或者阿里sentinel限流&降级
- 开启Redis持久化机制AOF/RDB,尽快回复缓存集群
2.2 缓存穿透
缓存穿透是指用户请求的数据再缓存中不存在,数据库中也不存在,导致请求都要去数据库中查一遍。如果有恶意攻击不断请求系统中不存在的数据,会导致大量请求落在数据库上,可能导致数据库宕机。
2.2.1 解决方案

- 方案1:空对象缓存或者缺省值
- 方案2:Google布隆过滤器Guava解决缓存穿透
- 方案3:Redis布隆过滤器解决缓存穿透
2.2.2 方案1:空对象缓存或者缺省值
一般都OK

But黑客或者恶意攻击
- 黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。
可能会导致你的数据库由于压力过大而宕掉 - id相同打你系统
第一次打到mysql,空对象缓存后第二次就返回null了,避免mysql被攻击,不用再到数据库中去走一圈了 - id不同打你系统
由于存在空对象缓存和缓存回写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
2.2.3 方案2:Google布隆过滤器Guava解决缓存穿透
- Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器
Guava’s BloomFilter 源码剖析
https://github.com/google/guava/blob/master/guava/src/com/google/common/hash/BloomFilter.java
Coding实战
建Module
添加POM
<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
写yml
server.port=5555
# =====================druid相关配置=======================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://yourip/redis?serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
spring.datasource.druid.test-while-idle=false
# ====================redis相关配置======================
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=yourip
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制) 默认-1,记得加入单位ms,不然idea报红色
spring.redis.lettuce.pool.max-active=9
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认-1,记得加入单位ms,不然idea报红色
spring.redis.lettuce.pool.max-wait=-1ms
# 连接池中的最大空闲连接 默认8
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接 默认0
spring.redis.lettuce.pool.min-idle=0
主启动
新建测试案例,hello入门
@Test
public void bloomFilter(){
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100);
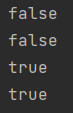
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
取样本100W数据,查查不在100W范围内的其它10W数据是否存在
public class BloomfilterDemo{
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)
public static double fpp = 0.03;
// 构建布隆过滤器
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);
public static void main(String[] args){
//1 先往布隆过滤器里面插入100万的样本数据
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里
List<Integer> list = new ArrayList<>(10 * _1W);
for (int i = size+1; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
System.out.println(i+"\t"+"被误判了.");
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
结论
现在总共有10万数据是不存在的,误判了3033次,
原始样本:100W
不存在数据:101W—110W
我们计算下误判率:===========》


debug源码分析下,查看下hash函数
从这里我们可以看到源码中默认会设置0.03的误判率,并且0.03的误判率会使用5个hash函数

fpp(误判率): False positive probability
查看误判率为0.03的100W个元素的布隆过滤器的创建:

查看误判率为0.01的100W个元素的布隆过滤器的创建:

对比:
误判率越高,所需bit数组就越大,hash函数就越多,程序效率越低。
布隆过滤器说明

2.2.4 方案3:Redis布隆过滤器解决缓存穿透
Guava缺点说明
Guava 提供的布隆过滤器的实现还是很不错的 (想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用 ,而现在互联网一般都是分布式的场景。
为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了
案例: 白名单过滤器
- 误判问题,但是概率小可以接受,不能从布隆过滤器删除
- 全部合法的key都需要放入过滤器+redis里面,不然数据就是返回null
白名单架构说明

code
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
public class RedissonBloomFilterDemo {
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少
public static double fpp = 0.03;
static RedissonClient redissonClient = null;//jedis
static RBloomFilter rBloomFilter = null;//redis版内置的布隆过滤器
@Resource
RedisTemplate redisTemplate;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://xxx:6379").setDatabase(0);
//构造redisson
redissonClient = Redisson.create(config);
//通过redisson构造rBloomFilter
rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter",new StringCodec());
rBloomFilter.tryInit(size,fpp);
// 1测试 布隆过滤器有+redis有
rBloomFilter.add("10086");
redissonClient.getBucket("10086",new StringCodec()).set("chinamobile10086");
// 2测试 布隆过滤器有+redis无
//rBloomFilter.add("10087");
//3 测试 ,布隆过滤器无+redis无
}
private static String getPhoneListById(String IDNumber) {
String result = null;
if (IDNumber == null) {
return null;
}
//1 先去布隆过滤器里面查询
if (rBloomFilter.contains(IDNumber)) {
//2 布隆过滤器里有,再去redis里面查询
RBucket<String> rBucket = redissonClient.getBucket(IDNumber, new StringCodec());
result = rBucket.get();
if(result != null) {
return "i come from redis: "+result;
}else{
result = getPhoneListByMySQL(IDNumber);
if (result == null) {
return null;
}
// 重新将数据更新回redis
redissonClient.getBucket(IDNumber, new StringCodec()).set(result);
}
return "i come from mysql: "+result;
}
return result;
}
private static String getPhoneListByMySQL(String IDNumber)
{
return "chinamobile"+IDNumber;
}
public static void main(String[] args) {
String phoneListById = getPhoneListById("10086");
//String phoneListById = getPhoneListById("10087"); //请测试执行2次
//String phoneListById = getPhoneListById("10088");
System.out.println("------查询出来的结果: "+phoneListById);
//暂停几秒钟线程
try {
TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) {
e.printStackTrace(); }
redissonClient.shutdown();
}
}
布隆过滤器有,redis中也有



布隆过滤器有,redis也没有
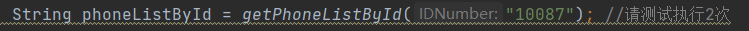
第一次测试:

第二次测试

布隆过滤器没有,redis也没有


重要总结

黑名单使用

2.2.5 在centos7下布隆过滤器2种安装方式
采用docker安装RedisBloom,推荐
- Redis 在 4.0 之后有了插件功能(Module),可以使用外部的扩展功能,可以使用 RedisBloom 作为 Redis 布隆过滤器插件。
- 使用docker安装
docker run -p 6378:6378 --name=bloomfilter -d redislabs/rebloom
docker exec -it bloomfilter /bin/bash
redis-cli
- 布隆过滤器常用操作命令
bf.add key 值 布隆过滤器添加某一个key(只是将该key被hash之后的对应bit数组的下标置为1)

bf.exists key 值 布隆过滤器判断某一个key是否存在
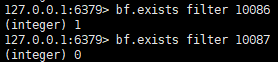
bf.madd 一次性添加多个元素
bf.mexists 一次性查询多个元素是否存在
bf.reserve key error_rate的值 initial_size的值 设置误判率和存放元素的size
编译安装
# 下载 编译 安装Rebloom插件
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.2.tar.gz
# 解压
tar -zxvf v2.2.2.tar.gz
cd RedisBloom-2.2.2
# 若是第一次使用 需要安装gcc++环境
make
# redis服启动添加对应参数 这样写还是挺麻烦的
# rebloom_module="/usr/local/rebloom/rebloom.so"
# daemon --user ${REDIS_USER-redis} "$exec $REDIS_CONFIG --loadmodule # $rebloom_module --daemonize yes --pidfile $pidfile"
# 记录当前位置
pwd
# 进入reids目录 配置在redis.conf中 更加方便
vim redis.conf
# :/loadmodule redisbloom.so是刚才具体的pwd位置 cv一下
loadmodule /xxx/redis/redis-5.0.8/RedisBloom-2.2.2/redisbloom.so
# 保存退出
wq
# 重新启动redis-server 我是在redis中 操作的 若不在请写出具体位置 不然会报错
redis-server redis.conf
# 连接容器中的 redis 服务 若是无密码 redis-cli即可
redis-cli -a 密码
# 进入可以使用BF.ADD命令算成功
2.3 缓存击穿
缓存击穿就是某个热点key突然失效,然后大量的请求读缓存没有读取到,从而导致高并发访问数据库,引起数据库压力剧增。这种现象就叫做缓存击穿。
- 解决方案1: 互斥更新、随机退避、差异失效时间
- 解决方案2: 对于访问频繁的热点key,干脆就不设置过期时间
- 解决方案3: 互斥独占锁防止击穿
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。

2.3.1 案例(淘宝聚划算功能实现+防止缓存击穿)
2.3.1.1 技术方案实现

2.3.1.2 redis数据类型选型

2.3.1.3 springboot+redis实现高并发的淘宝聚划算业务
建module
改pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>redis</artifactId>
<groupId>com.hmx</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>redis_20210511</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<hutool.version>5.5.8</hutool.version>
<druid.version>1.1.18</druid.version>
<mapper.version>4.1.5</mapper.version>
<pagehelper.version>5.1.4</pagehelper.version>
<mysql.version>8.0.25</mysql.version>
<swagger2.version>3.0.0</swagger2.version>
<mybatis.spring.version>2.1.1</mybatis.spring.version>
<junit.version>4.13.2</junit.version>
</properties>
<dependencies>
<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
<!--加密和解密-->
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.10</version>
</dependency>
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!--使用 Spring Boot 的 Actuator 的 Starter,它提供了生产就绪的特性来帮助你监控和管理你的应用程序-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--swagger-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
<!--SpringBoot与redis整合-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--SpringCache Spring框架的缓存支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!--SpringCache连接池依赖包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.6.1</version>
</dependency>
<!--springboot集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--mybatis和springboot整合-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.version}</version>
</dependency>
<!--springboot整合RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!--通用基础配置junit/devtools/test/log4j/lombok/hutool-->
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.7</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
<version>${junit.version}</version>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--通用Mapper tk单独使用,自己带着版本号-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>${mapper.version}</version>
</dependency>
<!--mybatis自带版本号-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<!--persistence-->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>persistence-api</artifactId>
<version>1.0.2</version>
</dependency>
<!--数据库连接-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>${basedir}/src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>${basedir}/src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.5.2</version>
</plugin>
</plugins>
</build>
</project>
写yml
# 项目启动端口
server.port=5555
# 项目名
spring.application.name=redis0511
# ======================Logging 日志相关的配置======================
# 系统默认,全局root配置的日志形式,可以注释掉
logging.level.root=warn
# 开发人员自己设置的包结构,对那个package进行什么级别的日志监控
logging.level.com.hmx.redis=info
# 开发人员自定义日志路径和日志名称
logging.file.name=E:/mylog/logs/redis1026.log
#%d{HH:mm:ss.SSS} - 日志输出时间
#%thread - 输出日志的进程名字,这在web应用以及异步任务处理中很有用
#%-5level - 日志级别,并且使用5个字符串靠左对齐
#%Logger - 日志输出者的名字
#%msg - 日志消息
#%n - 平台的换行符
#Logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %Logger- %msg%n
logging.pattern.console=%d{
yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %Logger- %msg%n
logging.pattern.file=%d{
yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %Logger- %msg%n
# =====================druid相关配置=======================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://yourip/redis?serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
spring.datasource.druid.test-while-idle=false
# ====================redis相关配置======================
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=yourip
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制) 默认-1,记得加入单位ms,不然idea报红色
spring.redis.lettuce.pool.max-active=9
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认-1,记得加入单位ms,不然idea报红色
spring.redis.lettuce.pool.max-wait=-1ms
# 连接池中的最大空闲连接 默认8
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接 默认0
spring.redis.lettuce.pool.min-idle=0
# =========mybatis相关配置===============
mybatis.mapper-locations=classpath:com/hmx/redis/mapper/*.xml
mybatis.type-aliases-package=com.hmx.redis.entity
# ==========swagger================
spring.swagger2.enabled=true
# ================rabbitmq相关配置===============
#spring.rabbitmq.host=127.0.0.1
#spring.rabbitmq.port=5672
#spring.rabbitmq.username=guest
#spring.rabbitmq.password=guest
#spring.rabbitmq.virtual-host=/
# ================redis 布隆过滤器相关配置====================
#redis.bloom.url=192.168.111.147
#redis.bloom.post=6379
#redis.bloom.init-capacity=10000
#redis.bloom.error-rate=0.01
主启动
业务类
配置RedisConfig
@Configuration
@Slf4j
public class RedisConfig {
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory) {
RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式为json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
entity
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(value = "聚划算活动producet信息")
public class Product {
private Long id;
/**
* 产品名称
*/
private String name;
/**
* 产品价格
*/
private Integer price;
/**
* 产品详情
*/
private String detail;
}
常量:
public class Constants {
public static final String JHS_KEY="jhs";
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
public static final String REBLOOM="rebloom:uid:";
}
采用定时器将参与聚划算活动的特价商品新增进入redis中
@Service
@Slf4j
public class JHSABTaskService {
@Autowired
private RedisTemplate redisTemplate;
//@PostConstruct ,平时注释,用时打开
public void initJHSAB(){
log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List<Product> list=this.products();
//先更新B缓存
this.redisTemplate.delete(Constants.JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_B,list);
this.redisTemplate.expire(Constants.JHS_KEY_B,20L,TimeUnit.DAYS);
//间隔一分钟 执行一遍
try {
TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) {
e.printStackTrace(); }
log.info("runJhs定时刷新..............");
}
},"t1").start();
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List<Product> products() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
}
controller
@RestController
@Slf4j
@Api(value = "聚划算商品列表接口")
public class JHSProductController {
@Autowired
private RedisTemplate redisTemplate;
/**
* 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮
* http://localhost:5555/swagger-ui.html#/jhs-product-controller/findUsingGET
*/
@RequestMapping(value = "/product/find",method = RequestMethod.GET)
@ApiOperation("按照分页和每页显示容量,点击查看")
public List<Product> find(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_B, start, end);
if (CollectionUtils.isEmpty(list)) {
//TODO 走DB查询
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
}

Bug和隐患说明
- QPS上1000后导致缓存击穿



进一步升级加固案例
- 定时轮询,互斥更新,差异失效时间
Service
@Service
@Slf4j
public class JHSABTaskService {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct//平时注释,用时打开
public void initJHSAB(){
log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取20件特价商品,用于加载到聚划算的页面中
List<Product> list=this.products();
//先更新B缓存
this.redisTemplate.delete(Constants.JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_B,list);
this.redisTemplate.expire(Constants.JHS_KEY_B,20L,TimeUnit.DAYS);
//再更新A缓存
this.redisTemplate.delete(Constants.JHS_KEY_A);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_A,list);
this.redisTemplate.expire(Constants.JHS_KEY_A,15L,TimeUnit.DAYS);
//间隔一分钟 执行一遍
try {
TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) {
e.printStackTrace(); }
log.info("runJhs定时刷新..............");
}
},"t1").start();
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List<Product> products() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
}

Controller
@RestController
@Slf4j
@Api(value = "聚划算商品列表接口AB")
public class JHSABProductController {
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping(value = "/pruduct/findab",method = RequestMethod.GET)
@ApiOperation("按照分页和每页显示容量,点击查看AB")
public List<Product> findAB(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_A, start, end);
if (CollectionUtils.isEmpty(list)) {
log.info("=========A缓存已经失效了,记得人工修补,B缓存自动延续5天");
//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存B
this.redisTemplate.opsForList().range(Constants.JHS_KEY_B, start, end);
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
}