调用API的思路:
- 获得api的token
- 按官方文档发送链接
- 分析返回的结果
步骤一:获取API的token
如果不知道token是啥,或是不知道怎么获取token,请参考:https://blog.csdn.net/weixin_35757704/article/details/120664069
这里给出一个工具方法:
def get_baidu_token() -> str:
"""获得百度的token"""
import requests
ak = "ZXGxxxxx" # 第2步中的API Key
sk = "RwAxxxxx" # 第2步中的Secret Key
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={0}&client_secret={1}'.format(
ak, sk)
response = requests.get(host)
if response:
return response.json()['access_token']
步骤二:按官方文档发送链接
文档链接:https://ai.baidu.com/ai-doc/NLP/fk6z52f2u
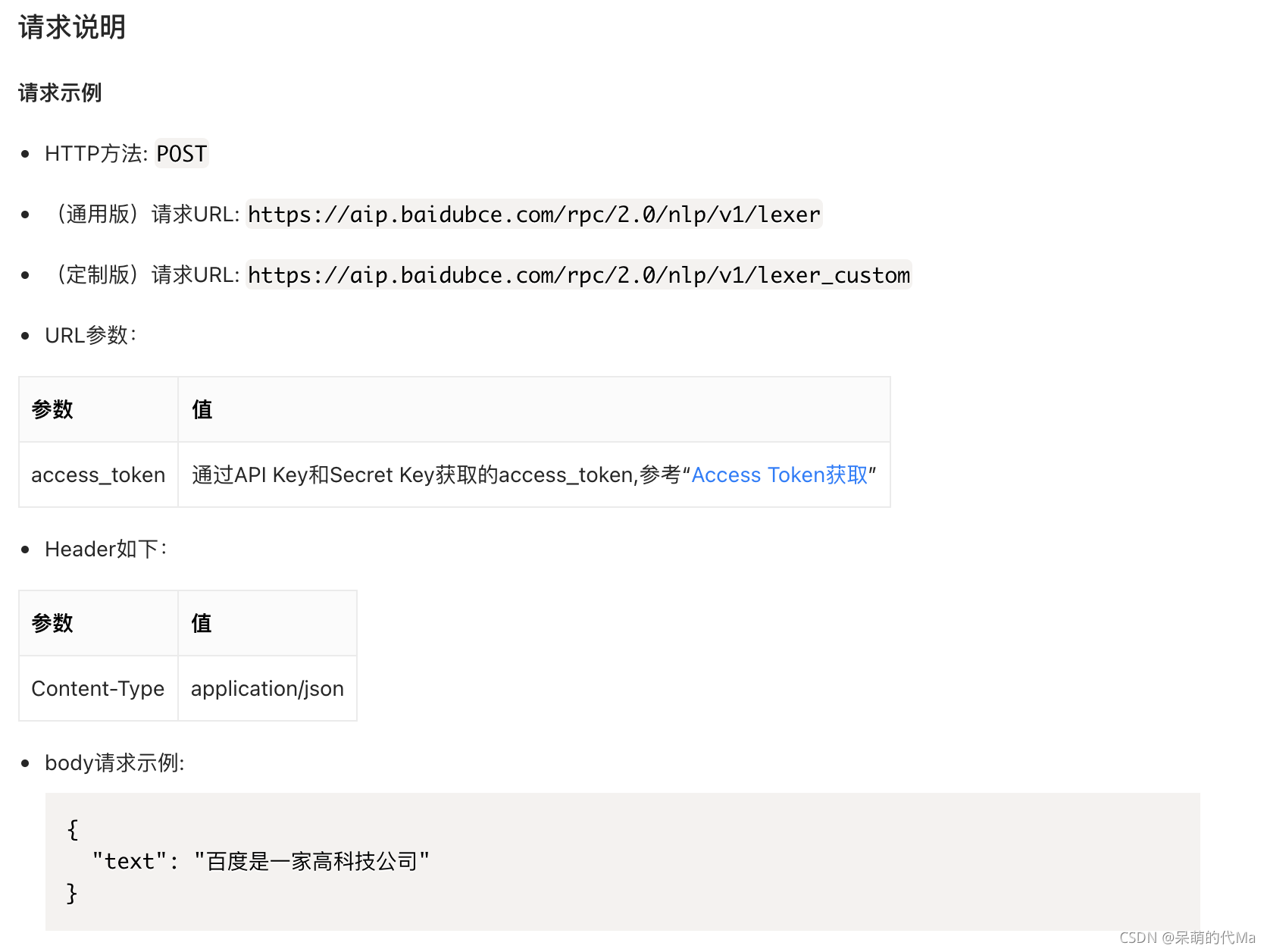
可以看到几个要点:
- POST请求
- 需要````access_token```
- Header添加
Content-Type属性,值为application/json - body添加
text属性,值为想要分析的内容
由此构建以下代码:
import json
def get_baidu_service(analyze_text, token) -> json: # 传入待分析的文本,与token
import urllib3
http = urllib3.PoolManager(cert_reqs='CERT_NONE') # 防止ssl报错
http_request = http.request(
method="POST", # post 请求
url="https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?access_token=" + token, # 百度API接口
body=json.dumps({
"text": analyze_text}), # body里添加text属性
headers={
# header添加Content-Type属性
'Content-Type': 'application/json;charset=UTF-8'
},
)
if http_request.status == 200:
return str(http_request.data, "GBK") # 返回json格式的字符串
步骤三:分析返回的结果
这里就是看自己需要什么结果了,以打印地点名词为例:
def analyze_baidu_service(analyze_result: str):
data: dict = json.loads(analyze_result) # 以字典形式读取json格式的字符串
for item in data['items']:
if item['ne'] == "LOC": # 如果是地点名词,就打印出来
print(item["item"])
# 打印结果:
# 太和殿
# 奉天殿
# 奉天殿
完整代码
import json
def get_baidu_token() -> str:
"""获得百度的token"""
import requests
ak = "ZXGxxxxx" # 第2步中的API Key
sk = "RwAxxxxx" # 第2步中的Secret Key
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={0}&client_secret={1}'.format(
ak, sk)
response = requests.get(host)
if response:
return response.json()['access_token']
def get_baidu_service(analyze_text, token) -> json:
import urllib3
http = urllib3.PoolManager(cert_reqs='CERT_NONE')
http_request = http.request(
method="POST",
url="https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?access_token=" + token,
body=json.dumps({
"text": analyze_text}),
headers={
'Content-Type': 'application/json;charset=UTF-8'
},
)
if http_request.status == 200:
return str(http_request.data, "GBK")
def analyze_baidu_service(analyze_result: str):
data: dict = json.loads(analyze_result) # 以字典形式读取json格式的字符串
for item in data['items']:
if item['ne'] == "LOC": # 如果是地点名词,就打印出来
print(item["item"])
# 太和殿
# 奉天殿
# 奉天殿
if __name__ == '__main__':
text = "太和殿始建于明朝永乐四年(1406年),建成于永乐十八年(1420年),初名奉天殿。[2]奉天殿初建时的体量,据《明世宗实录》卷四百七十记载:“原旧广三十丈,深十五丈云”,即面阔95米,进深48米,面积达4522平方米。"
analyze_data = get_baidu_service(text, token=get_baidu_token())
analyze_baidu_service(analyze_data)