一, API操作前的准备工作
〇, 目的
实现在Windows环境下, 从客户端机器远程操作集群.
具体的步骤:
- 配置客户端机器的环境变量
- 配置maven相关的环境变量
- 使用IDE, 新建maven工程
- 在pom文件中增加相应的依赖
- reload maven工程, 下载依赖
1. 1 客户端环境变量的配置
-
下载windows环境下的hadoop依赖文件, 解压到自定义目录下(非中文目录, 这里使用C:\hadoop_dependency\hadoop-3.1.0), 然后在系统变量中添加新的变量:
HADOOP_HOME="C:\hadoop_dependency\hadoop-3.1.0"

-
往
Path变量中添加,%HADOOP_HOME%/bin

-
在1中提到的安装目录中, 找到并双击
winutils, 使其启动, cmd窗口闪退则为成功, 若是提示缺少xx, 请加装 .new framework.
这个文件不管是在windows下使用hadoop以及在windows下远程调用hadoop集群都要使用的。


这个文件不管是在windows下使用hadoop以及在windows下远程调用hadoop集群都要使用的。
- 下载并配置maven, 下载-解压-添加环境变量(MAVEN_HOME 和 添加到path)


- 验证maven环境变量, cmd中输入
mvn -version

2.1 在IDE中新建maven项目并往pom文件中添加相关的依赖
- 打开IDE, file-> newproject, 点击next

- 修改GAV名称(V, version, 通常不做修改), 并点击finish

- [可选] 修改Maven的安装路径, 设置文件和本地仓库地址

- 在
pom.xml中添加必要的依赖
直接复制并覆盖原有的pom.xml, 注意GAV的一致性
注意:hadoop的版本号必须与集群中hadoop版本号一致!!!, 在这里因为我们是Windows远程连接Linux集群, 所以务必确认Linux系统中Hadoop的版本号.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.sb</groupId>
<artifactId>HDFSClientDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
2.2 重新加载maven项目, 自动下载依赖
- 右键点击项目名称
HDFSClientDemo, 选择maven-->reload project,开始自动下载所需的依赖文件.
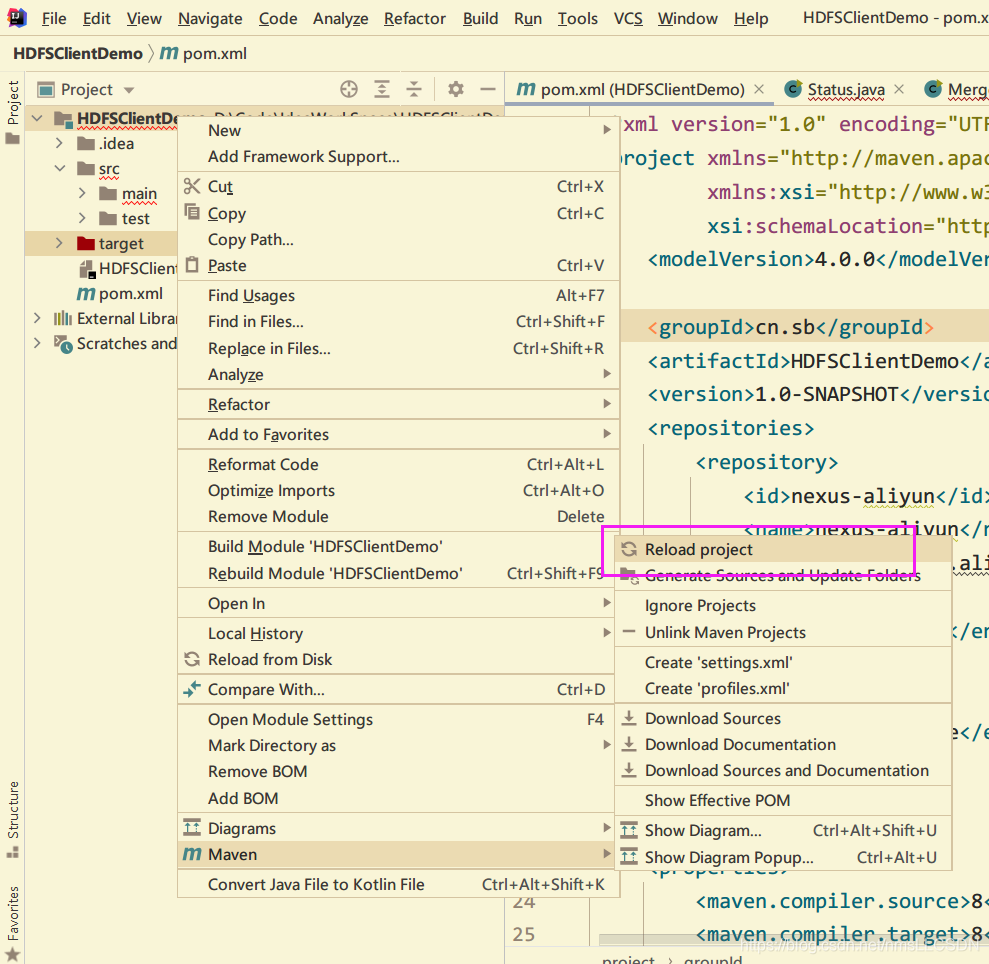
我们可以在IDE右下状态栏上点击
background tasks查看下载进度.
二, 具体操作
2.0 客户端(HDFS, ZooKeeper等)API操作的常用套路
//1. 获取一个客户端对象(通常这个对象会需要几个必要的参数, 必须先声明哈)
//2. 执行相关的操作命令
//3. 关闭资源
2.1 在HDFS上新建文件夹
如果我们想使用
hdfs://bigdata01:8020的话, 记得在windows的hosts文件中添加相应的映射噢!
package cn.cyy.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MkdirDemo {
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
//准备原料: 地址, 配置, 用户
URI uri = new URI("hdfs://192.168.182.100:8020");
Configuration configuration = new Configuration();
String user = "win10";
//开始工作
//1. 获取HDFS客户端对象 (Filesystem.get)
FileSystem fs = FileSystem.get(uri, configuration, user);
//2. 执行相关的命令
fs.mkdirs(new Path("/apiTest"));
//3. 关闭资源
fs.close();
}
}
由上面的代码, 我们可以发现
第一步获取HDFS客户端对象以及相应的准备工作和第三部关闭客户步都是可以独立出来的, 所以我们可以利用JUnit的一些特性优化代码如下:
注:
关于JUnit, @Before 测试前执行的代码段, @Test 测试部分, @After 测试完成后执行的代码段
package cn.cyy.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MkdirDemoUP {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//准备原料
URI uri = new URI("hdfs://192.168.182.100:8020");
Configuration configuration = new Configuration();
String user = "win10";
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
fs.close();
}
@Test
public void testMkdir() throws IOException {
fs.mkdirs(new Path("/apiTest"));
}
}
2.2 API操作中配置参数的优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath 下的用户自定义配置文
件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
验证:
2.3 从客户机上传文件到集群
由于上面
@After获取集群HDFS对象资源和Before关闭资源操作相同, 所以我们只给出@Test部分
- 栗子: 把windows客户机的D盘
/user/hadoop目录下的xyz文件, 上传到hdfs 的apiTest目录中.
使用到的Java方法,
copyFromLocalFile(boolean delSrc, boolean overwrite, Path/Path[] srcs, Path dst )
@Test
public void testCopyFromLocal() throws IOException {
//参数含义:
//1. delSrc, 布尔值, 是否删除客户机上的源文件
//2. overwite, 布尔值, 是否覆盖hdfs上已存在的文件
//3.srcs, Path值, 要上传文件在客户机的源路径
//4. dst, Path值, 上传文件到hdfs的目标路径
//fs.copyFromLocalFile(false, false, new Path("D:/user/hadoop/xyz"), new Path("/apiTest"));
fs.copyFromLocalFile(false, false, new Path("D:/user/hadoop/xyz"), new Path("/apiTest"));
}

注意: 在上传文件到hdfs时候可能遇到的错误:
org.apache.hadoop.fs.ChecksumException: Checksum errorhadoop在使用文件的时候如果文件夹内有CRC文件,就会做校验的。若是修改了文件内容,就会导致CRC校验文件校验失败, 从而有 checksum error。
解决方法: 删除相应的CRC文件.
2.4 从集群下载文件到客户机
- 栗子: 从hdfs下载 jdk-8u212-linux-x64.tar.gz到客户机D盘’/user/hadoop’目录下.
使用都的Java方法:
fs.copyToLocalFile(boolean delSrc, Path src, Path dst);
@Test
public void testCopyToLocal() throws IOException {
//参数含义:
//1. delSrc, 布尔值, 是否删除hdfs上的源文件
//2.src, Path值, hdfs上源文件的目录
//4. dst, Path值, 客户机的下载目标地址
//fs.copyToLocalFile(delSrc, src, dst);
fs.copyToLocalFile(false, new Path("/jdk-8u212-linux-x64.tar.gz"),
2.5 删除集群中的文件
使用到的Java方法:
delete(Path src, Boolean recursive);删除目录要是非空目录的话, recursive为 true哦!
- 栗子: 删除hdfs上 “/apiTest” 目录中的"xyz"文件.
@Test
public void testDelete(){
//1. Path src, 待删除hdfs上文件的路径
//2. Boolean recursive, 单文件和空目录-false, 非空目录-true
fs.delete("/apiTest/xyz", false);
}
2.6 对集群中的文件进行更名, 移动
使用的Java方法为
rename( Path path1, Path path2)我们可以利用
renamne方法, 完成对文件名, 目录名的修改, 还能使用它来移动文件, 同时, 想改名的话也可以直接改噢!
- 举个栗子:
@Test
public void testRename(){
//1. 修改文件名称
fs.rename(new Path("/jdk-8u212-linux-x64.tar.gz"), new Path("/jdk1.8"));
//2. 移动文件到其他目录. 同时还能改个名
fs.rename(new Path("jdk1.8"), new Path("/apiTest/jdk-1.8"));
//3. 修改目录名称
fs.rename(new Path("/apiTest/test00/"), new Path("/apiTest/test/"));
}
2.7 查看集群文件的详情
我们通过Java方法,
listFiles(Path path, Boolean recursive)得到文件信息的一个集合,注意噢, 这个方法的返回值是一个集合
RemoteIterator<LocatedFileStatus>, 我们通过可以通过遍历集合得到文件的各项信息.
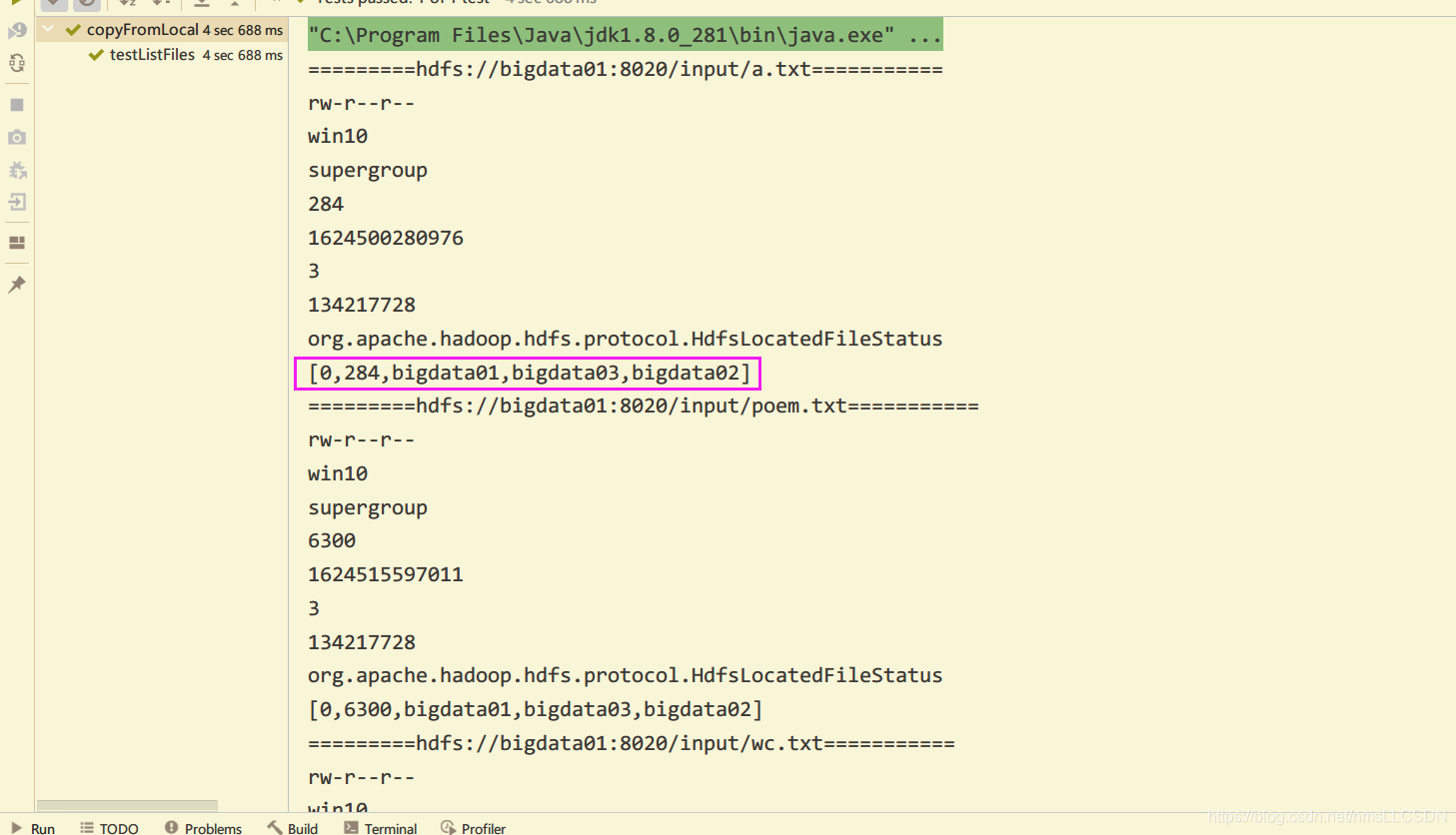
- 举个栗子: 查看 hdfs根目录下各个文件的参数
@Test
public void testListFiles() throws IOException {
RemoteIterator<LocatedFileStatus> fileStatus = fs.listFiles(new Path("/"), true);
while(fileStatus.hasNext()){
LocatedFileStatus fs = fileStatus.next();
System.out.println("========="+fs.getPath()+"===========");
System.out.println(fs.getPermission());
System.out.println(fs.getOwner());
System.out.println(fs.getGroup());
System.out.println(fs.getLen());
System.out.println(fs.getModificationTime());
System.out.println(fs.getReplication());
System.out.println(fs.getBlockSize());
System.out.println(fs.getClass().getName());
//查看每个文件的块信息(开始读块号, 结束读块号, 存储到集群的哪个主机上)
BlockLocation[] blockLocations = fs.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
- 输出结果如下:
tips: 快速生成输出语句的小技巧;
2.8 集群文件和文件夹的判断
我们通过
listStatus来得到一个存储每个文件的各种信息的数组, 然后遍历数组, 通过数组变量(也就是一个文件信息的集合)的isFile()判断当前文件是目录还是文件.
这个数组有哪些内容呢?
文件路径. 修改时间. 大小, 拥有者等等.
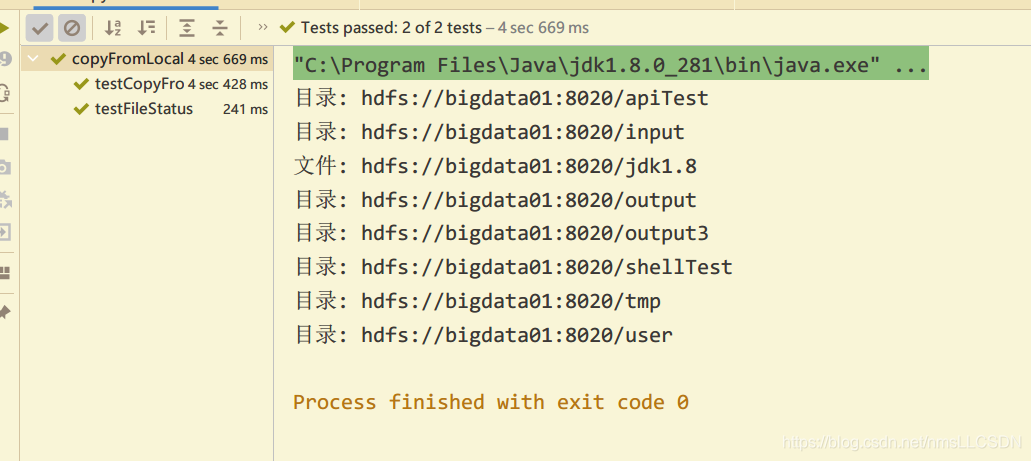
@Test
public void testFileStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus status : fileStatuses) {
if (status.isFile()) {
System.out.println("文件: "+status.getPath());
}else{
System.out.println("目录: " + status.getPath());
}
}
}
综合所有源码如下:
package cn.cyy.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
public class BasicHDFSAPI {
/**
* 0. 提前准备工作
* 1. 得到HDFS客户端对象
* 2. 操作HDFS
* 3. 关闭资源
*/
//全局变量, hdfs客户端操作对象
FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//0. 提前准备, URI, Configuration, User
URI uri = new URI("hdfs://bigdata01:8020");
Configuration configuration = new Configuration();
String user = "win10";
fs = FileSystem.get(uri, configuration, user);
}
@Test
public void testHDFSAPI() throws IOException {
//1. 新建文件夹
//fs.mkdirs(new Path("/API"));
//2. 上传文件到集群
// fs.copyFromLocalFile(false, false, new Path("D:/learning-life/Hadoop/笔记"),
// new Path("/API"));
//3. 从集群下载文件到客户机
// fs.copyToLocalFile(false, new Path("/API/笔记"),new Path("D:/CODE"));
//4. 从集群删除文件
// fs.delete(new Path("/API/笔记/随堂笔记.txt"), false);
//5. 在集群中移动文件 和 更名文件
// fs.rename(new Path("/API/笔记/随堂绘图.pdf"), new Path("/API/随堂笔记.txt"));
//6. 列出集群某个文件夹里文件的详情
RemoteIterator<LocatedFileStatus> listFile = fs.listFiles(new Path("/API"), true);
while(listFile.hasNext()){
LocatedFileStatus fileStatus = listFile.next();
System.out.println("=============="+fileStatus.getPath()+"=============");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getClass().getName());
System.out.println(Arrays.toString(fileStatus.getBlockLocations()));
}
}
@Test
public void testFileStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus status : fileStatuses) {
if (status.isFile()) {
System.out.println("文件: "+status.getPath());
}else{
System.out.println("目录: " + status.getPath());
}
}
}
@After
public void close() throws IOException {
fs.close();
}
}