Saliency Maps
Saliency maps 是一个很快的方法来说明图片中的哪些部分影响了模型对于最后那个正确分类label的判断
**Saliency Maps告诉我们图像中的每个像素对该图像分类评分的影响程度。**为了计算它,我们计算对应于正确类的非归一化分数(标量)对于图像中每个像素的梯度。如果图像形状为 ( 3 , H , W ) (3,H,W) (3,H,W),那么这个梯度的尺寸也是 ( 3 , H , W ) (3,H,W) (3,H,W)。这个梯度告诉我们:图像中的一个像素的微小变化将使分类评分发生多大的变化。为了计算显著性图,我们取梯度的绝对值,然后取3个输入通道上的最大值;最终的Saliency Maps因此具有形状 ( H , W ) (H,W) (H,W),并且是非负的。
-
代码补全
def compute_saliency_maps(X, y, model): """ Compute a class saliency map using the model for images X and labels y. Input: - X: Input images; Tensor of shape (N, 3, H, W) - y: Labels for X; LongTensor of shape (N,) - model: A pretrained CNN that will be used to compute the saliency map. Returns: - saliency: A Tensor of shape (N, H, W) giving the saliency maps for the input images. """ # Make sure the model is in "test" mode model.eval() # Make input tensor require gradient X.requires_grad_() saliency = None ############################################################################## # TODO: Implement this function. Perform a forward and backward pass through # # the model to compute the gradient of the correct class score with respect # # to each input image. You first want to compute the loss over the correct # # scores (we'll combine losses across a batch by summing), and then compute # # the gradients with a backward pass. # ############################################################################## # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** scores=model(X) scores=scores.gather(1,y.view(-1,1)).squeeze() #取出每个正确分类的得分 scores.backward(torch.FloatTensor([1.0,1.0,1.0,1.0,1.0])) #正确分类得分对于图像中像素的梯度 saliency=X.grad.data #取出梯度 saliency=saliency.abs() #绝对值 saliency,i=torch.max(saliency,dim=1) #三通道最大值 saliency=saliency.squeeze() # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** ############################################################################## # END OF YOUR CODE # ############################################################################## return saliency -
绘图后结果

可以看到,红色部分都是有梯度的,也就是说这些点会对正确分类产生影响
Fooling Images
我们可以扰乱一个输入的图片,使它对于人类来说看起来是一样的,但是会被我们的与训练的模型分错类。生成的图像也被称为“fooling image”
给定一幅图像和一个目标类(和给定的图像不一个类),我们可以对图像进行梯度上升以最大化目标类,当网络将该图像分类为目标类时停止。
-
代码补全
def make_fooling_image(X, target_y, model): """ Generate a fooling image that is close to X, but that the model classifies as target_y. Inputs: - X: Input image; Tensor of shape (1, 3, 224, 224) - target_y: An integer in the range [0, 1000) - model: A pretrained CNN Returns: - X_fooling: An image that is close to X, but that is classifed as target_y by the model. """ # Initialize our fooling image to the input image, and make it require gradient X_fooling = X.clone() X_fooling = X_fooling.requires_grad_() learning_rate = 1 ############################################################################## # TODO: Generate a fooling image X_fooling that the model will classify as # # the class target_y. You should perform gradient ascent on the score of the # # target class, stopping when the model is fooled. # # When computing an update step, first normalize the gradient: # # dX = learning_rate * g / ||g||_2 # # # # You should write a training loop. # # # # HINT: For most examples, you should be able to generate a fooling image # # in fewer than 100 iterations of gradient ascent. # # You can print your progress over iterations to check your algorithm. # ############################################################################## # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** for i in range(100): scores = model(X_fooling) _, index = scores.max(dim=1) if index == target_y: break target_score = scores[0, target_y] target_score.backward() im_grad = X_fooling.grad X_fooling.data += learning_rate * (im_grad / im_grad.norm()) X_fooling.grad.zero_() # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** ############################################################################## # END OF YOUR CODE # ############################################################################## return X_fooling

可以看到,我们朝着目标target class修改后,人眼看上去没什么区别,但将差别放大十倍,可以看到,还是有区别的。这在一定程度上反映了模型将图片判定为 stingray 这个类时关注的一些点。
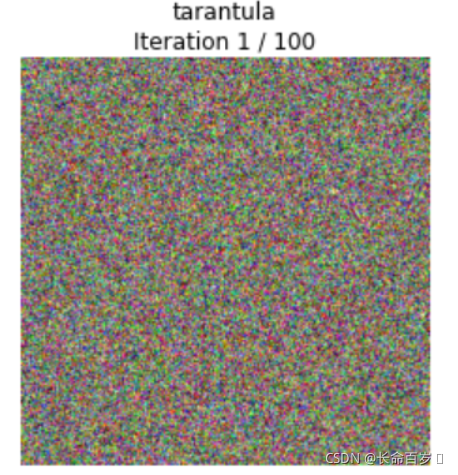
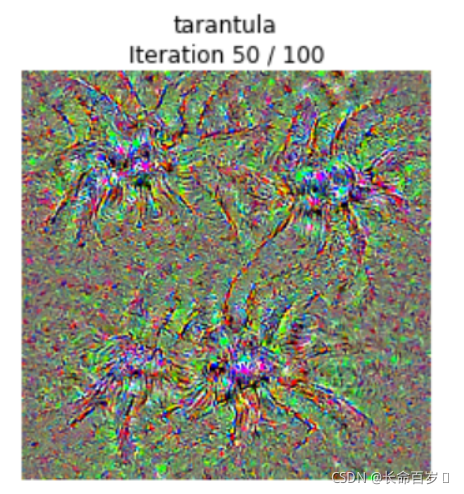
Class visualization
我们可以合成一张图片来最大化一个特定类的打分;这可以给我们一些直观感受,来看看模型在判断图片是当前这个类的时候它在关注的是图片的哪些部分。
从一张随机噪声图开始,通过不断向target class应用梯度上升迭代参数,我们可以得到一张让网络判断为target class的图像。
I ∗ = arg max I ( s y ( I ) − R ( I ) ) I^* = \arg\max_I (s_y(I) - R(I)) I∗=argmaxI(sy(I)−R(I))
-
I I I是图像
-
y y y是 target class
-
S y ( I ) S_y(I) Sy(I)是神经网络判断图像 I I I 在分类 y y y 上的得分
-
R ( I ) R(I) R(I) 是正则项。本次实验中使用 L 2 L_2 L2 norm : R ( I ) = λ ∥ I ∥ 2 2 R(I) = \lambda \|I\|_2^2 R(I)=λ∥I∥22
-
我们的目的是:让产生的图像在神经网络中正确分类的得分最大。这个目标可以通过梯度上升来实现(计算的是正确分类的得分对生成图像的梯度)。
-
将通过显示 L 2 L_2 L2 norm 和 隐式正则化来定期模糊生成图像
-
代码补全
def create_class_visualization(target_y, model, dtype, **kwargs): """ Generate an image to maximize the score of target_y under a pretrained model. Inputs: - target_y: Integer in the range [0, 1000) giving the index of the class - model: A pretrained CNN that will be used to generate the image - dtype: Torch datatype to use for computations Keyword arguments: - l2_reg: Strength of L2 regularization on the image - learning_rate: How big of a step to take - num_iterations: How many iterations to use - blur_every: How often to blur the image as an implicit regularizer - max_jitter: How much to gjitter the image as an implicit regularizer - show_every: How often to show the intermediate result """ model.type(dtype) l2_reg = kwargs.pop('l2_reg', 1e-3) learning_rate = kwargs.pop('learning_rate', 25) num_iterations = kwargs.pop('num_iterations', 100) blur_every = kwargs.pop('blur_every', 10) max_jitter = kwargs.pop('max_jitter', 16) show_every = kwargs.pop('show_every', 25) # Randomly initialize the image as a PyTorch Tensor, and make it requires gradient. img = torch.randn(1, 3, 224, 224).mul_(1.0).type(dtype).requires_grad_() for t in range(num_iterations): # Randomly jitter the image a bit; this gives slightly nicer results ox, oy = random.randint(0, max_jitter), random.randint(0, max_jitter) img.data.copy_(jitter(img.data, ox, oy)) ######################################################################## # TODO: Use the model to compute the gradient of the score for the # # class target_y with respect to the pixels of the image, and make a # # gradient step on the image using the learning rate. Don't forget the # # L2 regularization term! # # Be very careful about the signs of elements in your code. # ######################################################################## # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** score = model(img) loss = score[0, target_y] - l2_reg * img.norm()**2 loss.backward() img.data += learning_rate * img.grad img.grad.zero_() model.zero_grad() # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** ######################################################################## # END OF YOUR CODE # ######################################################################## # Undo the random jitter img.data.copy_(jitter(img.data, -ox, -oy)) # As regularizer, clamp and periodically blur the image for c in range(3): lo = float(-SQUEEZENET_MEAN[c] / SQUEEZENET_STD[c]) hi = float((1.0 - SQUEEZENET_MEAN[c]) / SQUEEZENET_STD[c]) img.data[:, c].clamp_(min=lo, max=hi) if t % blur_every == 0: blur_image(img.data, sigma=0.5) # Periodically show the image if t == 0 or (t + 1) % show_every == 0 or t == num_iterations - 1: plt.imshow(deprocess(img.data.clone().cpu())) class_name = class_names[target_y] plt.title('%s\nIteration %d / %d' % (class_name, t + 1, num_iterations)) plt.gcf().set_size_inches(4, 4) plt.axis('off') plt.show() return deprocess(img.data.cpu())
生成结果(狼蛛图片,谨慎观看)