前几天科目二一把100分过,舒服。

不过看了下科目三更难,希望考科目三的时候顺利一点。
好,言归正题,最近要实现一下大规模渲染,需要用到GPUInstancing,所以记录一下。
按惯例,上官方:GPUInstancing
首先我们知道渲染流程有三大阶段:应用阶段、几何阶段、光栅阶段。
而渲染绘制的关键瓶颈就是DrawCall,也就是调用一次GPU绘制的过程。需要我们在渲染流程应用阶段“整理”给GPU需要绘制的数据,一共需要CPU调用磁盘IO、内存IO、总线BUS等。这个过程因为涉及硬件结构和交互多,所以属于耗时的一个操作。常见的优化DrawCall方式有两种:
1.合批(多合一):就是多个需要绘制的几何数据合并成一个大的几何数据,减少几何阶段“整理”数据的次数,例如:图集合并、网格合并
2.预缓存:就是如果做不到合批的情况下,预先将磁盘中的几何数据加载到内存中,那么应用阶段“整理”数据的时候可以省去磁盘IO耗时、内存分配耗时等,例如:对象池、流关卡
3.剔除:就是将视口无法照射到(渲染到)的object剔除出渲染提交队列,减少几何数据的“个数”,例如:遮挡剔除
设想有一个场景,相同的物体很多,比如相同的建筑物、花草树木、小动物等。如果用传统的摆模,那DrawCall就太大量了,如果用网格合并(美术3Dmax中合并、unity自带静动合并、程序mesh合并等),对于cpu和内存的消耗也随着场景复杂度提高而提高。甚至就算是整个场景合并成一个DrawCall,但是这个DrawCall也“太肥了”,GPU“吃下”这个DrawCall的过程也很耗时。

我们先来直观感受一下unity静动合批的情况,首先代码生成30*30*30=27000个cube,然后关闭unity的静动合批,观察DrawCall:

DrawCall有107445个,可能有小伙伴吓了一跳,27000个物体DrawCall翻了4倍,其实和Shadow有关,在Quality里面关闭Shadow即可(当然常规方法是烘培),如下:

接下来我们分别开启静态网格合并和动态网格合并,如下:

图:标记static和勾选static batching后的运行参数

图:取消标记static和勾选dynamic batching后的参数
我们可以整理一个表格:
| CPU一帧耗时(ms) | GPU一帧耗时(ms) | Batches一帧批提交(次) | SavedByBatches一帧节省的批提交(次) | FPS帧率 | |
| No Batching | 48.9 | 12.4 | 27002(-2) | 0 | 20.4 |
| Static Batching | 42.9 | 0.7 | 35(-2) | 26967 | 23.3 |
| Dynamic Batching | 45.1 | 3.6 | 33(-2) | 26969 | 22.2 |
表:参数统计(-2)是因为unity默认DrawCall+1和天空盒DrawCall+1
通过表格可以看出几点情况:
1.合批是有策略(规则)的,并不是完全的n合1,而是n合m(受顶点数量等限制)
2.静态批处理帧率更高,且对GPU负担最小,理论上最省电
3.看得出我的CPU(i5 3470)(准确的说应该是整个应用阶段)处理Static/Dynamic Batching消耗也挺高(40+ms)。同时我的GPU是GTX750,处理几万个DrawCall也可以达到60-90fps左右,结果最后fps数值都很相近(20+)
下面我们来看一看GPU Instancing,官方第一句话就是:
Use GPU Instancing to draw (or render) multiple copies of the same Mesh
at once, using a small number of draw calls. It is useful for drawing objects such as buildings, trees and grass, or other things that appear repeatedly in a Scene
. 绘制场景中重复出现的花草树木建筑的拷贝,而且是GPU层进行的拷贝,那么理想情况就是我们提交一份例如树木的几何数据,GPU内部就可以拷贝绘制无数份这颗树木,当然这无数份树木的Transform数据(TRS)还是要通过应用阶段提交的,但是相比以前的无数小DrawCall或者一个“肥”DrawCall要好多了。
还是直接来实验一下运作过程:
Shader "GPUInstancing/InstancedSimpleLightShader"
{
Properties
{
_MainColor ("Color", Color) = (1,1,1,1)
_LightFactor("Light",Color) = (1,1,1,1)
_DiffuseFactor("Diffuse",Color) = (1,1,1,1)
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing //开启gpuinstancing
#include "UnityCG.cginc"
#include "Lighting.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
};
struct v2f
{
float3 worldP2S : TEXCOORD0;
float3 worldNormal : TEXCOORD1;
float4 vertex : SV_POSITION;
};
float4 _MainColor;
float4 _LightFactor;
float4 _DiffuseFactor;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldP2S = normalize(WorldSpaceLightDir(v.vertex));
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = _MainColor;
float3 light = _LightColor0.rgb * _LightFactor;
float3 diffuse = _LightColor0.rgb* max(dot(i.worldNormal,i.worldP2S),0)*_DiffuseFactor;
col *= fixed4(light+diffuse,1);
return col;
}
ENDCG
}
}
}
只需要一句简单的预编译即可开启GPUInstancing: #pragma multi_compile_instancing,效果如下
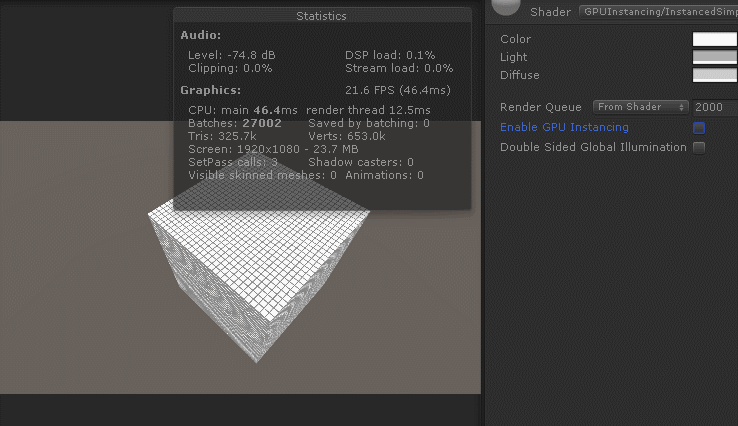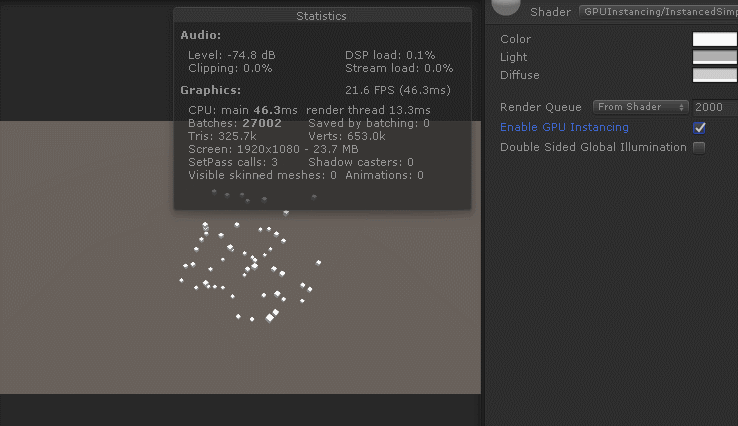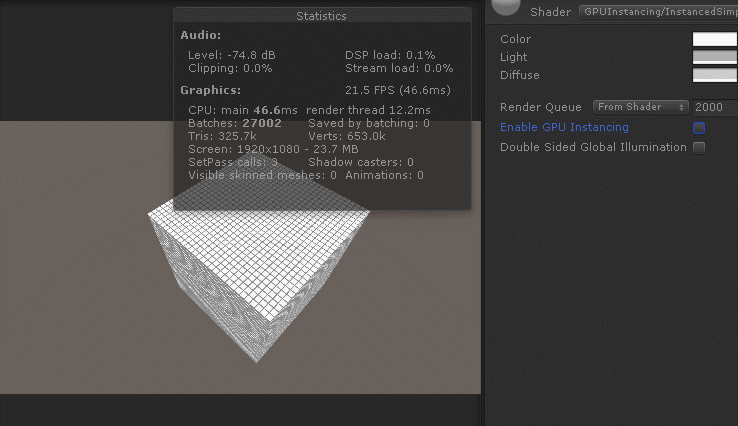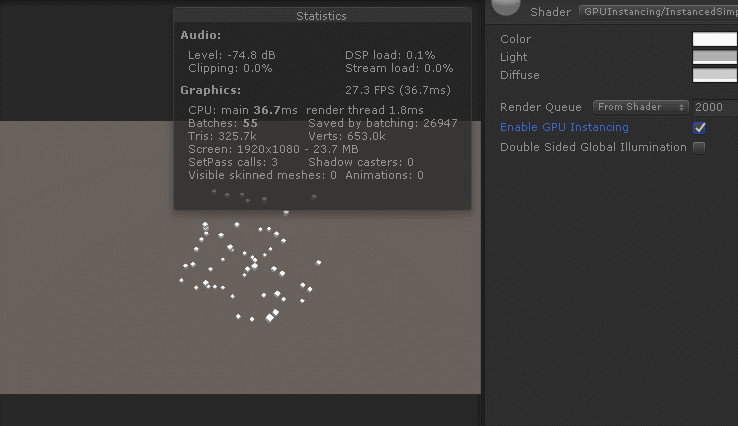
可以看得出来GPUInstancing对于CPU应用阶段和GPU渲染阶段都有效率提升。CPU一帧耗时在三者之中最低,GPU一帧耗时处于动态合批和静态合批之间。综合效率最好,帧率最高。
不过同时也看出一个问题,GPUInstancing中我们没有处理每个Mesh的TRS,所以GPUInstancing中一组cube的TRS都相同(也就是被Instancing的那个cube),我们得改改代码:
Shader "GPUInstancing/InstancedSimpleLightShader"
{
Properties
{
_MainColor ("Color", Color) = (1,1,1,1)
_LightFactor("Light",Color) = (1,1,1,1)
_DiffuseFactor("Diffuse",Color) = (1,1,1,1)
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing //开启gpuinstancing
#include "UnityCG.cginc"
#include "Lighting.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
UNITY_VERTEX_INPUT_INSTANCE_ID //打包TRS等信息,生成一个instanceID
};
struct v2f
{
float3 worldP2S : TEXCOORD0;
float3 worldNormal : TEXCOORD1;
float4 vertex : SV_POSITION;
};
float4 _MainColor;
float4 _LightFactor;
float4 _DiffuseFactor;
v2f vert (appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v); //根据v的instanceID设置TRS等信息
o.vertex = UnityObjectToClipPos(v.vertex);
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldP2S = normalize(WorldSpaceLightDir(v.vertex));
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = _MainColor;
float3 light = _LightColor0.rgb * _LightFactor;
float3 diffuse = _LightColor0.rgb* max(dot(i.worldNormal,i.worldP2S),0)*_DiffuseFactor;
col *= fixed4(light+diffuse,1);
return col;
}
ENDCG
}
}
}
加了如下两句宏之后,每个cube的TRS就正常了
1.UNITY_VERTEX_INPUT_INSTANCE_ID
2.UNITY_SETUP_INSTANCE_ID(v);
我对这两句宏的意义是这么理解的:
UNITY_VERTEX_INPUT_INSTANCE_ID定义在appData中,相当于告诉GPU储存这个cube几何数据的TRS等数据,然后生成一个instanceID,且GPU显存中就是用一个hashtable数据结构储存好了CPU一次整体提交的所有cube的TRS数据。
UNITY_SETUP_INSTANCE_ID(v);则是根据每个v的instanceID通过hashtable提取相应的TRS等数据,然后在vert函数中变换使用,所以能够将每个cube的TRS还原。
如图:
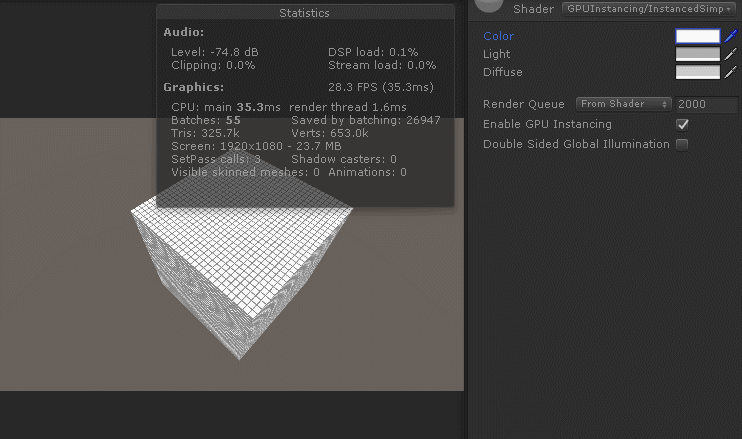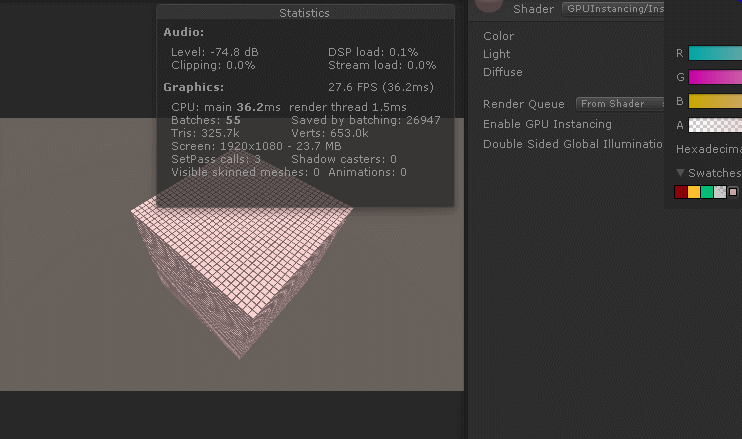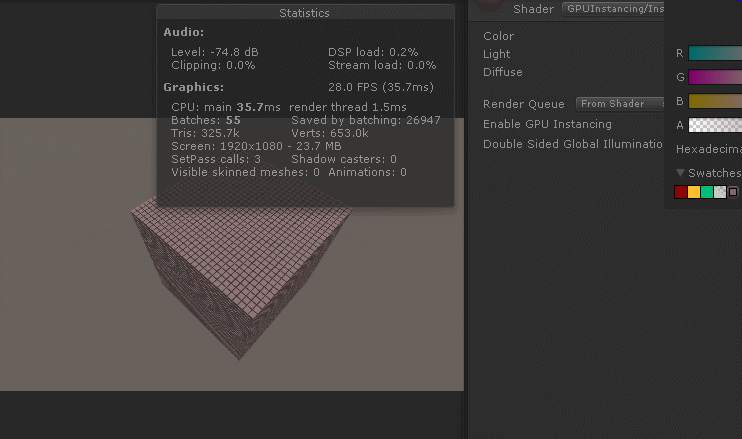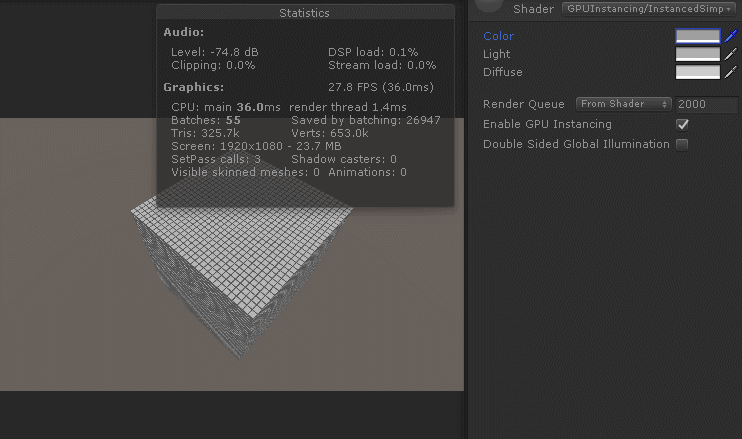
但是我们会发现,如果改变material中maincolor的颜色值,所有的cube颜色值都会被改变(这不是废话吗?我们用的sharedmaterial,当然牵一发而动全身)。不过如果我们想每个cube的颜色值也不同怎么办?我们前面都已经通过instanceID修改每个cube的TRS了,改个颜色值很难吗?接下来继续实现:
首先是c#CPU代码:
void Start()
{
MaterialPropertyBlock prop = new MaterialPropertyBlock();
for (int i = 0; i < transform.childCount; i++)
{
Renderer render = transform.GetChild(i).GetComponent<Renderer>();
Color col = new Color(Random.Range(0f, 1f), Random.Range(0f, 1f), Random.Range(0f, 1f), 1);
prop.SetColor("_Color", col);
render.SetPropertyBlock(prop);
}
}我们首先使用c#初始化MaterialPropertyBlock,储存一个随机的颜色值,然后传递到每个render中。
然后是shaderGPU代码:
Shader "GPUInstancing/InstancedSimpleLightShader"
{
Properties
{
_MainColor ("Color", Color) = (1,1,1,1)
_LightFactor("Light",Color) = (1,1,1,1)
_DiffuseFactor("Diffuse",Color) = (1,1,1,1)
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing //开启gpuinstancing
#include "UnityCG.cginc"
#include "Lighting.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
UNITY_VERTEX_INPUT_INSTANCE_ID //打包TRS等信息,生成一个instanceID
};
struct v2f
{
float3 worldP2S : TEXCOORD0;
float3 worldNormal : TEXCOORD1;
float4 vertex : SV_POSITION;
};
float4 _MainColor;
float4 _LightFactor;
float4 _DiffuseFactor;
UNITY_INSTANCING_BUFFER_START(Props) //定义pre-instance property,定义需要接收的属性
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_INSTANCING_BUFFER_END(Props)
v2f vert (appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v); //根据v的instanceID设置TRS等信息
o.vertex = UnityObjectToClipPos(v.vertex);
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldP2S = normalize(WorldSpaceLightDir(v.vertex));
return o;
}
fixed4 frag (v2f i) : SV_Target
{
//fixed4 col = _MainColor;
fixed4 col = UNITY_ACCESS_INSTANCED_PROP(Props,_Color); //获取pre-instance(也就是c#)中生成的随机color
float3 light = _LightColor0.rgb * _LightFactor;
float3 diffuse = _LightColor0.rgb* max(dot(i.worldNormal,i.worldP2S),0)*_DiffuseFactor;
col *= fixed4(light+diffuse,1);
return col;
}
ENDCG
}
}
}
shader代码中需要注意:
1.
UNITY_INSTANCING_BUFFER_START(name) UNITY_INSTANCING_BUFFER_END(name) |
Every per-instance property must be defined in a specially named constant buffer. Use this pair of macros to wrap the properties you want to be made unique to each instance. |
使用上面两个宏包含定义pre-instance property中用来访问的属性,比如我们需要访问_Color这个颜色(float4)字段,UNITY_DEFINE_INSTANCED_PROP(float4, _Color)就匹配了c#代码中MaterialPropertyBlock中的随机"_Color"。
2.UNITY_ACCESS_INSTANCED_PROP(Props,_Color);
使用这个宏可以访问c#传递来的MaterialPropertyBlock中的字段_Color(float4),就可以在frag函数中渲染随机颜色。
效果如下:

总结:GPUInstancing是不是很好用?即可以达到提升程序渲染效率的目的,又可以实现不同的渲染Property策略。
不过同时也可以看的出来,GPUInstancing对于GPU的消耗还是要比静态批处理要高一倍以上的,如果碰到一个CPU强大GPU不行的硬件环境,还是静态批处理好些,所以不同的场景情况采取合适的处理方法。
最后GPUInstancing比较适合相同mesh的大批量渲染情况。我们还可以组合处理,如场景中静态网格进行静态批处理、运动的同材质物体动态批处理、大量相同mesh和material(不同pre-instance property)的花草树木等使用GPUInstancing。总之就是根据实际情况来选择。