Flink流处理(下)
流的切分
也就是分流操作,这个对应的是一套方法,分流合流。每一个方法又对应了两个步骤。然后每一种方法又对应了几个小方法。套娃了解一下~~最后那就是输出操作,先前是直接print()打印输出了,那么现在必然不是这样的,例如我做一个实时的用户统计系统,服务器的数据流过来我们这边按照规则运算然后输出到服务器专门负责数据可视化或者数据接受的API接口然后完成相应的操作。未来的小想法就是想要简单地基于Flink做一个系统状态统计系统,找一个优秀的前端数据可视化模板,然后结合Flink,做一个数据面板,最简单的应用就是网站实时数据监测,状态分析,和预测。
split分流
这个先声明一下这个方法已经过期了,新版本是没有的,当然现在我用的版本还是能用的,毕竟做项目这块还是用稳不用新,到时候资料都查不到,而且现在好多教程也说到了这个,那这里也继续写一下,后面介绍代替的方法。
何为分流,看图
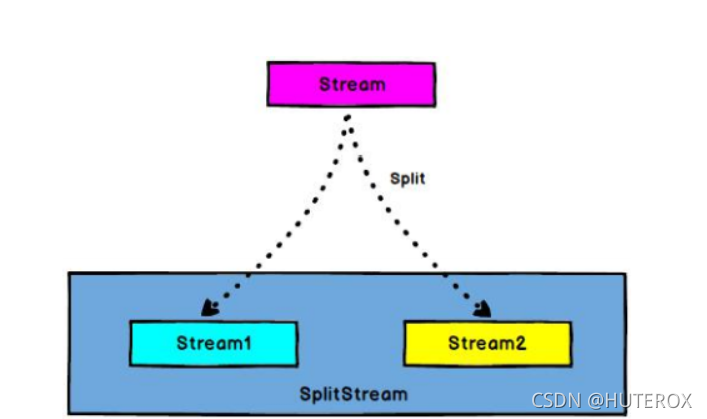
说白了就是把一个流分成了两个流,但是这里并不是直接分成了两个流,其实真正的操作是,下图。
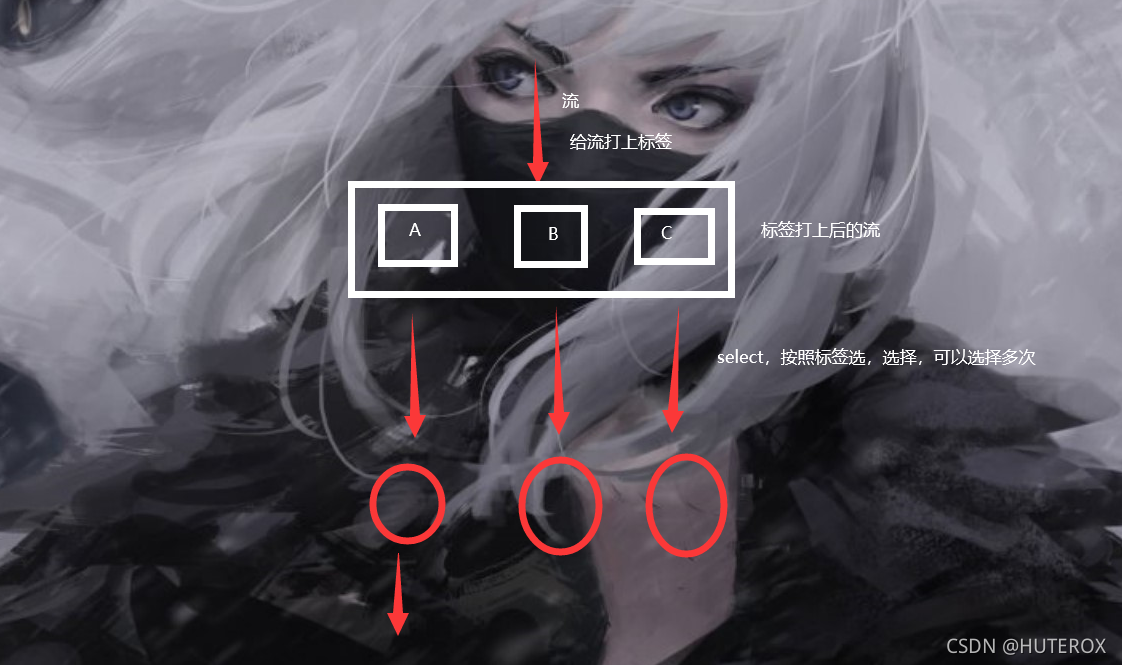
和过滤器有点像,但是区别是数据都还在,过滤器是直接过滤了,也就是说过滤器这个玩意类似于标签和选择一起做了,然后返回数据。
下面是个例子介绍怎么用,这个我们还是直接分流那个高于175cm和低于的学生(ps我高于175,单位:cm)
package com.java;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.Arrays;
public class SplitDome {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentdata = env.fromCollection(Arrays.asList(
new Student("小明", 20, 165),
new Student("小李", 21, 192),
new Student("小王", 22, 175),
new Student("小夏", 20, 195)
));
SplitStream<Student> splitdata = studentdata.split(new OutputSelector<Student>() {
@Override
public Iterable<String> select(Student value) {
//这个是一个数组么,打入标志
ArrayList<String> output = new ArrayList<>();
if (value.getHeight() > 170) {
output.add("height");
} else {
output.add("low");
}
return output;
}
});
//选择分类
DataStream<Student> height = splitdata.select("height");
height.print("height");
env.execute();
}
}

这个简单嘛,没什么好说的,做个演示。
getSideOutput进行分流
这个原因也很简单么,确实是split被弃用了,虽然还是能用,但是它自己注释都告诉你要用output了,那么这个就涉及到process了。
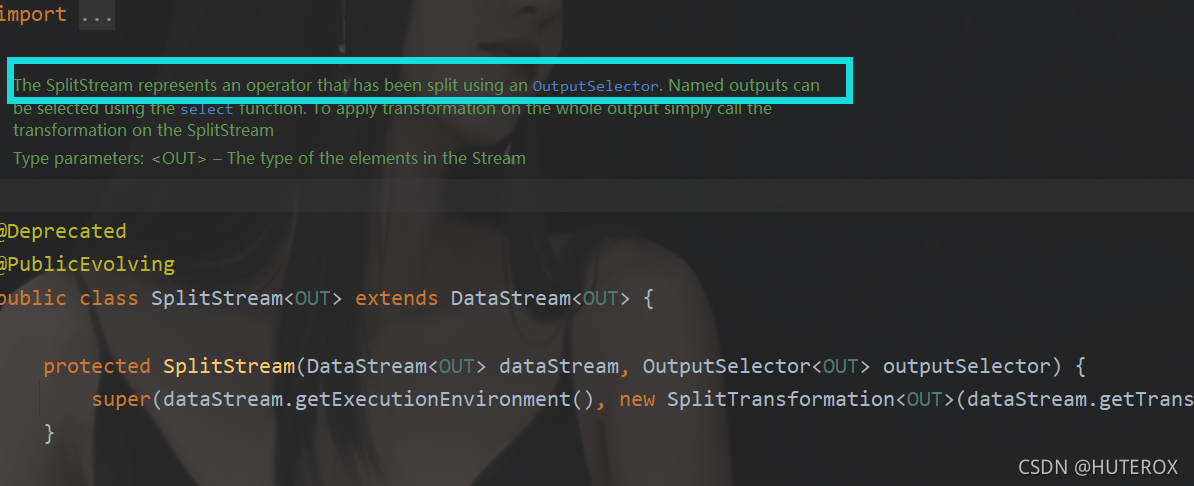
用起来也是简单的。那么这个叫做测流输出,那么和原来弃用的split的区别就是,那个split只能分流一次,如果你想要再分,那还不如直接使用filter算了。但是测流输出就不会有这样的问题可以随便继续分流。
我们先调用底层的process方法,这个API可以帮助我们把数据打一个标签,如下图示例:
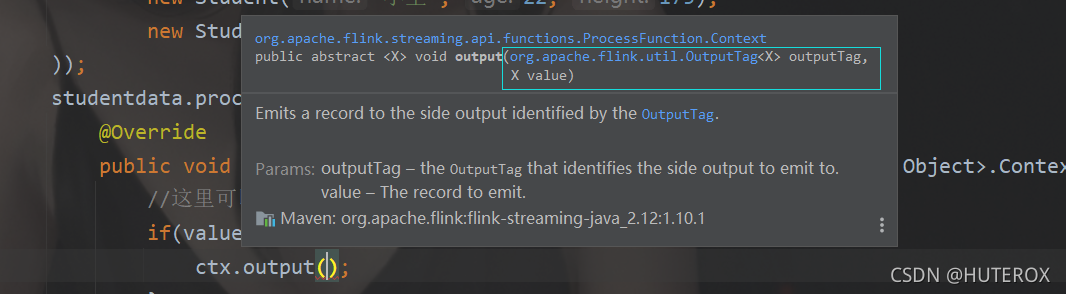
package com.java;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Arrays;
public class SplitDome {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentdata = env.fromCollection(Arrays.asList(
new Student("小明", 20, 165),
new Student("小李", 21, 192),
new Student("小王", 22, 175),
new Student("小夏", 20, 195)
));
OutputTag<Student> height = new OutputTag<Student>("height"){
};
OutputTag<Student> low = new OutputTag<Student>("low"){
};//定义标签分类的玩意,记住一定要这样写,百度都是骗人的!
//这样写绝对不会出错
SingleOutputStreamOperator<Object> tagdata = studentdata.process(new ProcessFunction<Student, Object>() {
@Override
public void processElement(Student value, ProcessFunction<Student, Object>.Context ctx, Collector<Object> out) throws Exception {
//这里可以直接看到这里有一个ctx就是这玩意干活
if (value.getHeight() > 170) {
ctx.output(height, value);
} else {
ctx.output(low, value);
}
}
});
DataStream<Student> sideOutput = tagdata.getSideOutput(height);
sideOutput.print();
env.execute();
}
}
结果:
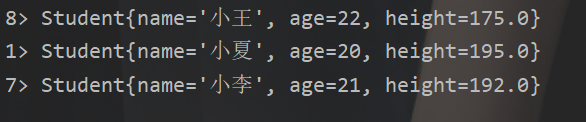
所以用哪个的话,一句话小总结
1.如果后面数据不需要再进行分流的话,那么我们直接使用split就可以了,毕竟操作更加简单,少些几个变量不香?
2.如果后面要进行再分流还是直接那啥吧,直接用测流分流,也就是实现process的接口,便于后面的操作。
合流
天下大势,合久必分分久必合。
所以我们后面还有个合流操作,这个是怎么个玩法呢,其实这个所谓的合流其实也只是做个统一输出。
之后通过规则进行输出,举个例子,假设两个班,一个班代表一个流,现在所谓合流其实就是把两个班的同学叫到一个大教室,然后按照学号点名然后叫出去。
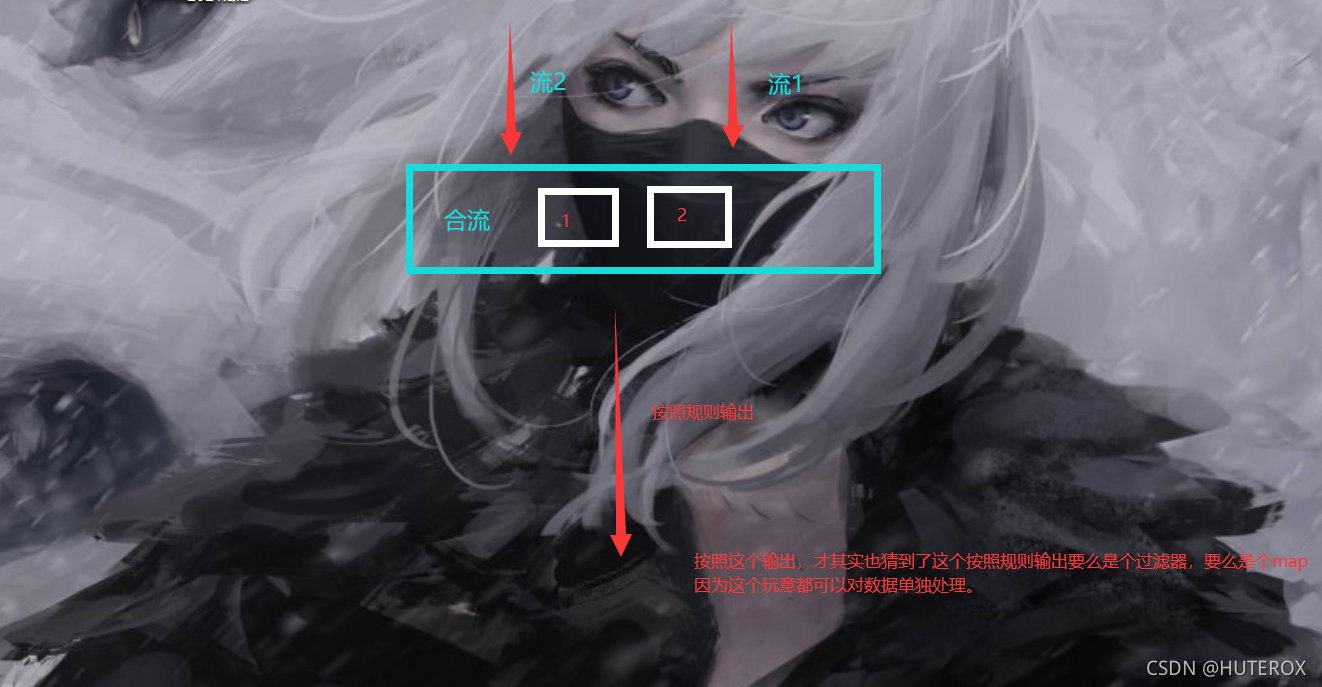
connect合流
1.优点
支持不同的数据类型进行联合
2.缺点
只能合两个
ok直接演示
package com.java;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Arrays;
public class SplitDome {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentdata = env.fromCollection(Arrays.asList(
new Student("小明", 20, 165),
new Student("小李", 21, 192),
new Student("小王", 22, 175),
new Student("小夏", 20, 195)
));
OutputTag<Student> height = new OutputTag<Student>("height"){
};
OutputTag<Student> low = new OutputTag<Student>("low"){
};//定义标签分类的玩意,记住一定要这样写,百度都是骗人的!
//这样写绝对不会出错
SingleOutputStreamOperator<Object> tagdata = studentdata.process(new ProcessFunction<Student, Object>() {
@Override
public void processElement(Student value, ProcessFunction<Student, Object>.Context ctx, Collector<Object> out) throws Exception {
//这里可以直接看到这里有一个ctx就是这玩意干活
if (value.getHeight() > 170) {
ctx.output(height, value);
} else {
ctx.output(low, value);
}
}
});
DataStream<Student> heightsideOutput = tagdata.getSideOutput(height);
DataStream<Student> lowsideOutput = tagdata.getSideOutput(low);
//为了演示我们那个对这个height的数据进行处理一下,输出一个元组
SingleOutputStreamOperator<Object> tupleheight = heightsideOutput.map(new MapFunction<Student, Object>() {
@Override
public Object map(Student student) throws Exception {
return new Tuple2<Student, Integer>(student, 1);
}
});
ConnectedStreams<Object, Student> connectdata = tupleheight.connect(lowsideOutput);
SingleOutputStreamOperator<Object> map = connectdata.map(new CoMapFunction<Object, Student, Object>() {
//这里写CoMapFunction接口就好了
@Override
public Object map1(Object value) throws Exception {
//这里的map1里面的value是当前的height的那个流
//这个是什么意思呢,那就是如果当前数据是原来height流里面的,那就执行这个方法,那么我这样输出 height 下面那个我输出low
return "height";
}
@Override
public Object map2(Student value) throws Exception {
//这个是low的那个
return "low";
}
});
map.print("connect");
env.execute();
}
}
结果:

那么这里有map那么对应的就有FlatMap()
这个也是可以的。
SingleOutputStreamOperator<Object> flat = connectdata.flatMap(new CoFlatMapFunction<Object, Student, Object>() {
@Override
public void flatMap1(Object value, Collector<Object> out) throws Exception {
out.collect("height");
}
@Override
public void flatMap2(Student value, Collector<Object> out) throws Exception {
out.collect("low");
}
});
flat.print();
效果是一样的。
union联合
1.优点
可以集合任意多个流
2.缺点
只能是同类型的
很简单直接上例子
package com.java;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Arrays;
public class SplitDome {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentdata = env.fromCollection(Arrays.asList(
new Student("小明", 20, 165),
new Student("小李", 21, 192),
new Student("小王", 22, 175),
new Student("小夏", 20, 195)
));
OutputTag<Student> height = new OutputTag<Student>("height"){
};
OutputTag<Student> low = new OutputTag<Student>("low"){
};//定义标签分类的玩意,记住一定要这样写,百度都是骗人的!
//这样写绝对不会出错
SingleOutputStreamOperator<Object> tagdata = studentdata.process(new ProcessFunction<Student, Object>() {
@Override
public void processElement(Student value, ProcessFunction<Student, Object>.Context ctx, Collector<Object> out) throws Exception {
//这里可以直接看到这里有一个ctx就是这玩意干活
if (value.getHeight() > 170) {
ctx.output(height, value);
} else {
ctx.output(low, value);
}
}
});
DataStream<Student> heightsideOutput = tagdata.getSideOutput(height);
DataStream<Student> lowsideOutput = tagdata.getSideOutput(low);
//为了演示我们那个对这个height的数据进行处理一下,输出一个元组
SingleOutputStreamOperator<Object> tupleheight = heightsideOutput.map(new MapFunction<Student, Object>() {
@Override
public Object map(Student student) throws Exception {
return new Tuple2<Student, Integer>(student, 1);
}
});
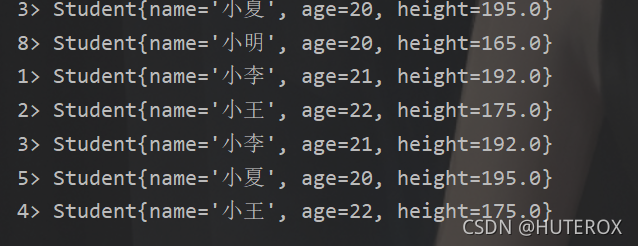
DataStream<Student> union = studentdata.union(heightsideOutput);
union.print();
//这里是把原来的和高的搞在一起了一个七个,如果把刚刚分开的两个流(高的,矮的合在一起是会和奇怪的)
//也就是说不要把刚刚搞在一个流分开来不做处理又合在一起。这个时候是正常的,我这里是做了测试的。至于具体原因我暂时还不清楚
env.execute();
}
}
return new Tuple2<Student, Integer>(student, 1);
}
});
DataStream<Student> union = studentdata.union(heightsideOutput);
union.print();
//这里是把原来的和高的搞在一起了一个七个,如果把刚刚分开的两个流(高的,矮的合在一起是会和奇怪的)
//也就是说不要把刚刚搞在一个流分开来不做处理又合在一起。这个时候是正常的,我这里是做了测试的。至于具体原因我暂时还不清楚
env.execute();
}
}