Hadoop的序列化机制以及序列化案例求解每个部门工资总额
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118966924(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Hadoop的序列化
1.1 序列化定义
序列化(Serialization):是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
1.2 Java序列化编程
通过上面的定义可能很难进行理解,通过Java代码的实际操作来加深理解一下序列化的含义。首选新建一个package命名为ser.java,然后随便创建一个学生的类

然后就是创建一个测试的类,进行运行,看一下能不能把实例化的学生信息存储在本地

然后运行这个测试的Java程序,输出的结果显示(抛出了NotSerializableException,也就是无法被序列化的错误)
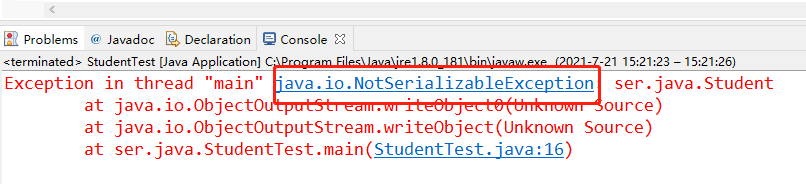
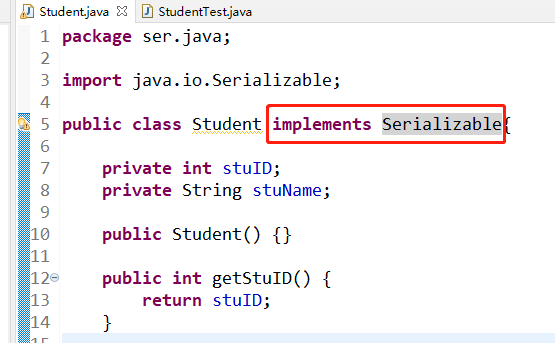
要想实现对象永久化的存储就必须实现序列化的过程,对于Java来讲提供的有一个Serializable接口,在创建类的时候执行一下这个接口再运行即可
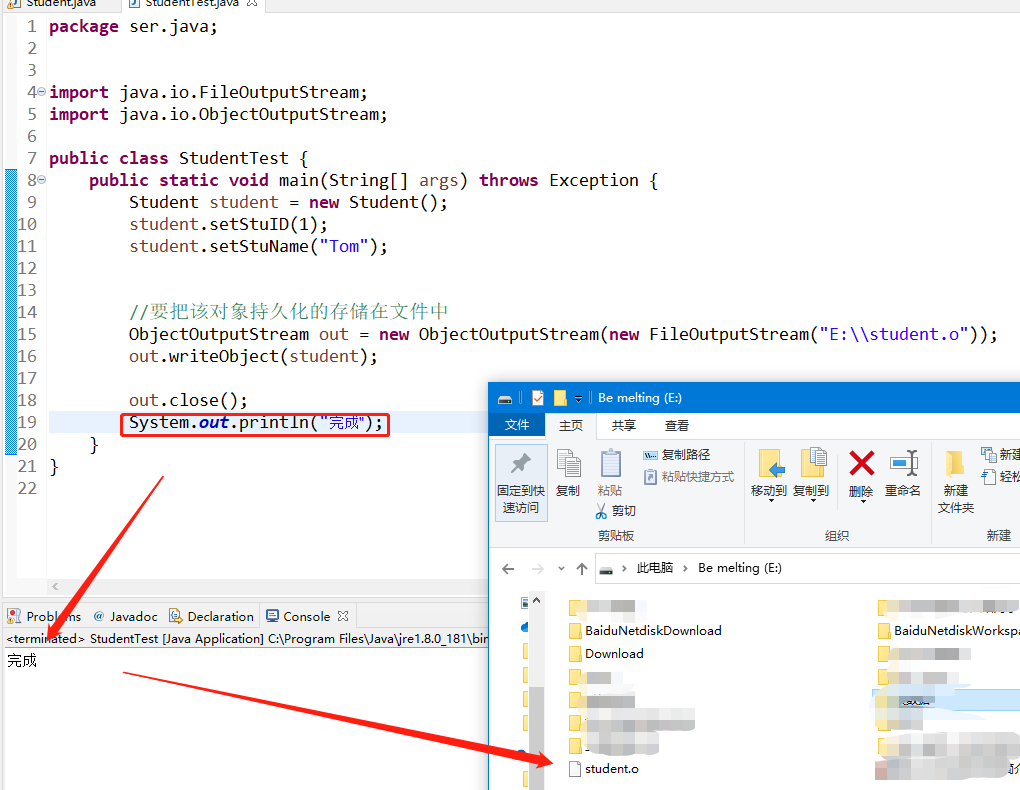
最后为了显示运行成功状态,在测试的Java程序中添加一条输出提醒,最后的输出如下,实现了对象的持久化存储的要求
1.3 hadoop序列化编程
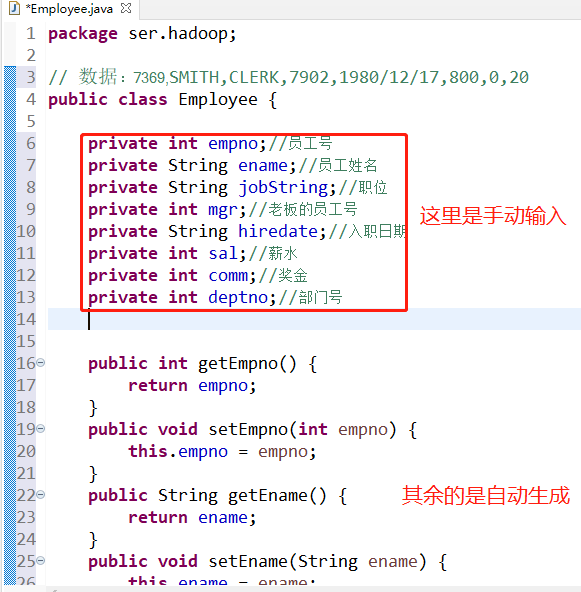
和Java实现序列化一样,要想在hadoop中把一种数据类型作为Map和Reduce的输入和输出的Key以及Value,也就必须实现序列化的接口(Writable,与Java的Serializable类似)。比如创建一个Employee类,封装员工数据,作为Map阶段的value(也就是k2),然后k2使用的是员工号
使用的数据还是之前的员工表中的数据,共八个字段,然后创建一个类包含所有的字段
由于数据最终要被输出到HDFS上,为了方便进行查看最终的结果,可以重写tostring方法,将员工号、姓名、薪水和部门号四个字段进行转化(当然也可以全部进行转化)

以上就是完成了最简单的Java Class的设置,但是这个程序并不能作为Map的key和value,因为没有实现序列化的接口。只需要添加implements Writable代码,然后自动填充对应的方法(在Employee类后面执行Writable的接口,然后鼠标放在Employee上面,点击第一个选项,会自动补充需要完善的方法)
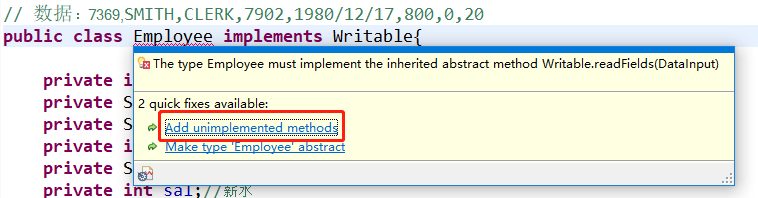
自动生成要完善的方法有两个,一个就是读取(反序列化过程),一个是输出(序列化的过程)

在进行完善的过程中,需要注意一点:序列化的过程要和反序列化的过程顺序保持一致

然后就可以创建一个Map程序和执行的主程序进行验证一下,Map程序里面注意要对每个字段进行一一设置
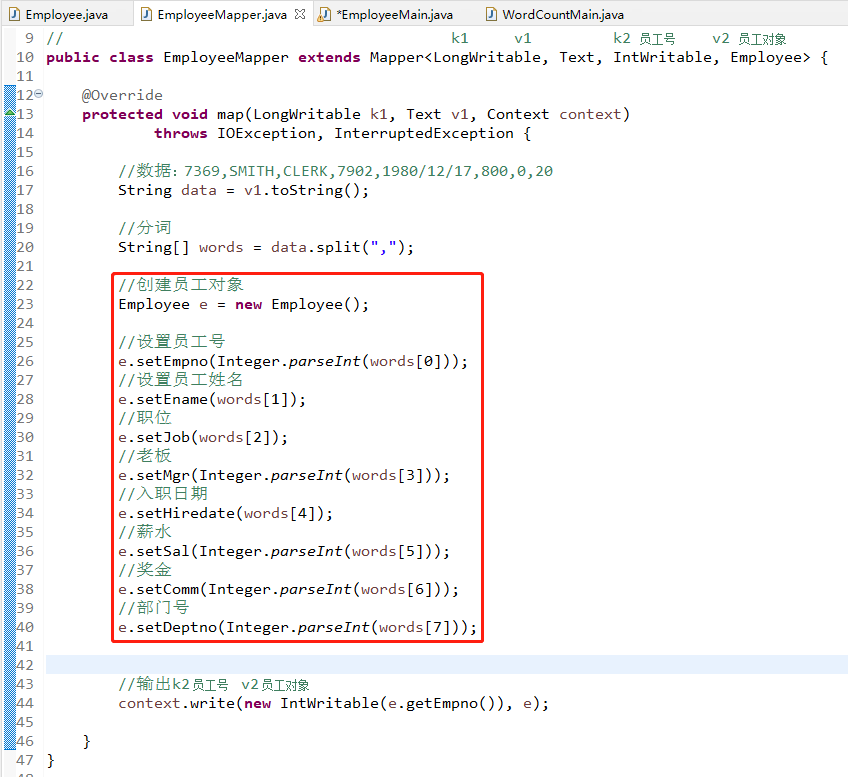
然后就是主程序界面,由于没有了Reduce,所以少了一行代码,最后要修改的也是三个框中的内容,其余的保持不变

至此就完成了测试代码的开发,然后将代码打包成为jar文件,上传至hadoop进行测试
然后hadoop上测试显示成功运行
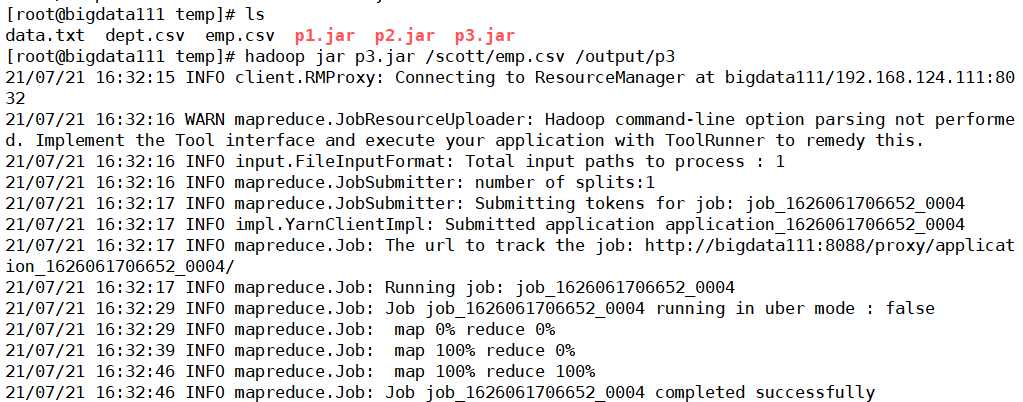
最后一步就是看看生成的目录文件中的信息是否一致(输出很完美,就是和最开始我们希望要看到的一样,再对tostring进行重写输出的格式保持一致)
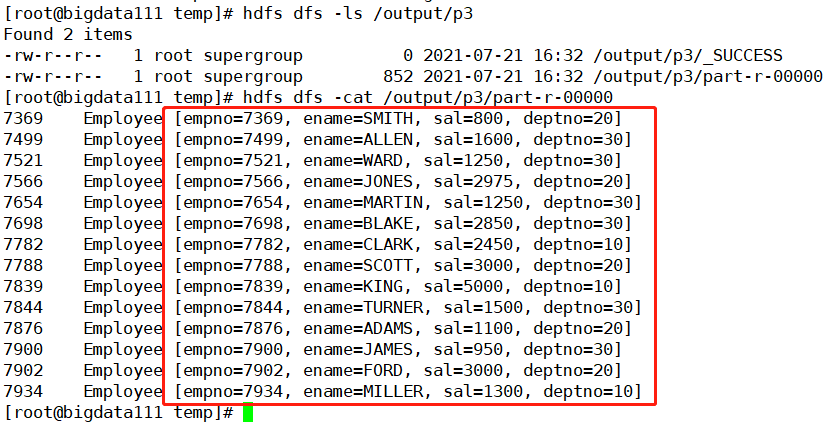
2 序列化求解每个部门工资总额
上一篇博客进行求解每个部门工资总额的求解,刚刚又进行了hadoop序列化的设置,那么接下来就是直接使用序列化的方式进行求解每个部门工资总额的求解
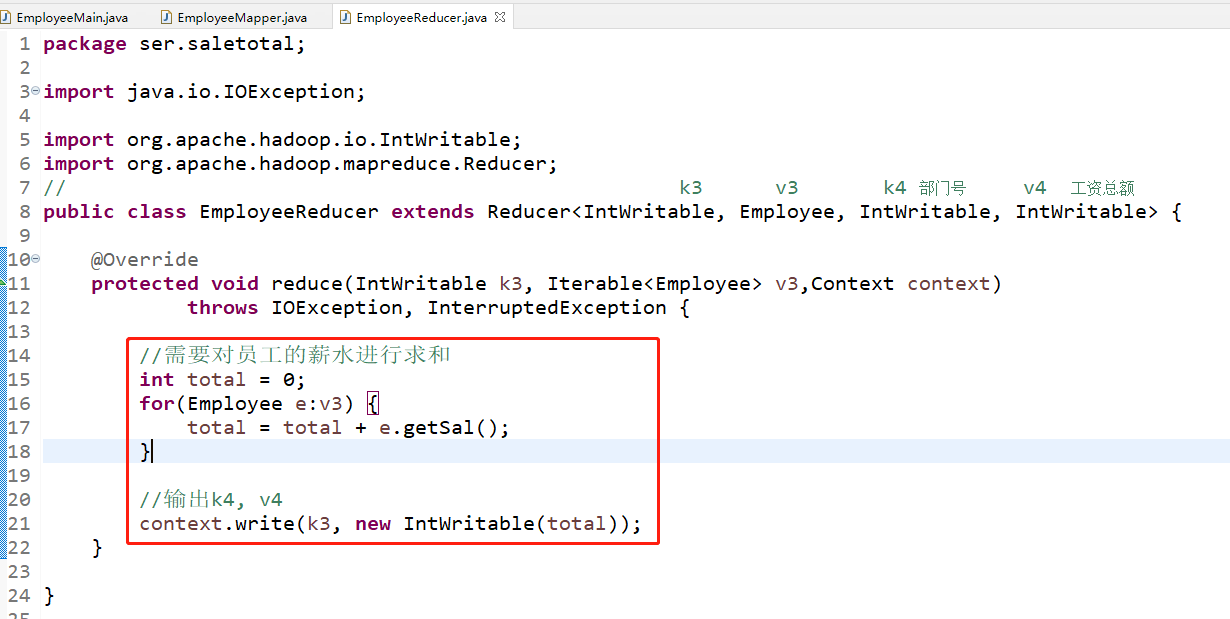
过程详解可以基于之前的过程进行改造,主要是V2和v3之间的区别,这里都变成了对象,然后v3就是对象中取出薪水构成的集合,最后的v4就是薪水的总和

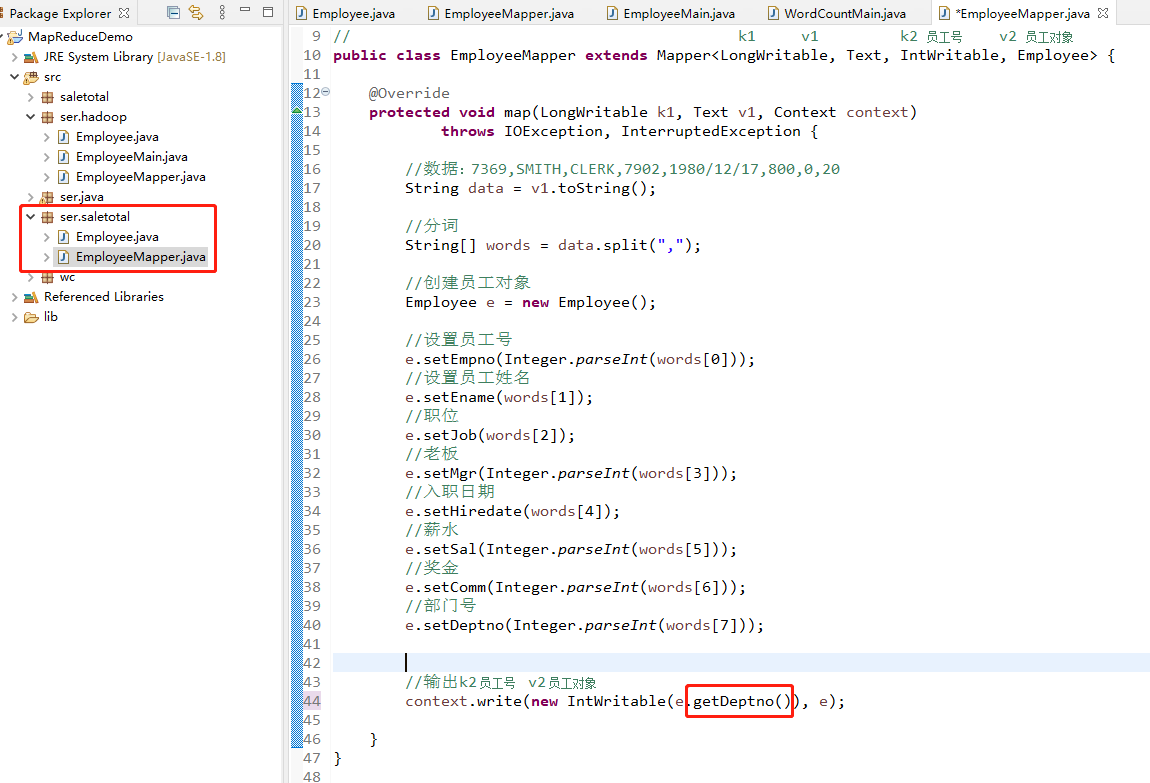
直接就利用刚刚序列化的代码进行编写,创建一个ser.saletotal的package,接着就是三个框架,首先将定义的Employee.java这个文件直接复制过来,然后就是Map程序中修改最后一行的代码,将原来的员工号修改为部门号,如下
Reduce的程序代码之前没有进行创建,因此主要的工作量就是在这个地方,新建一个Java Class命名为EmpolyeeReducer,具体的运算也是进行求和,但是和之前的变量上面还是有点区别
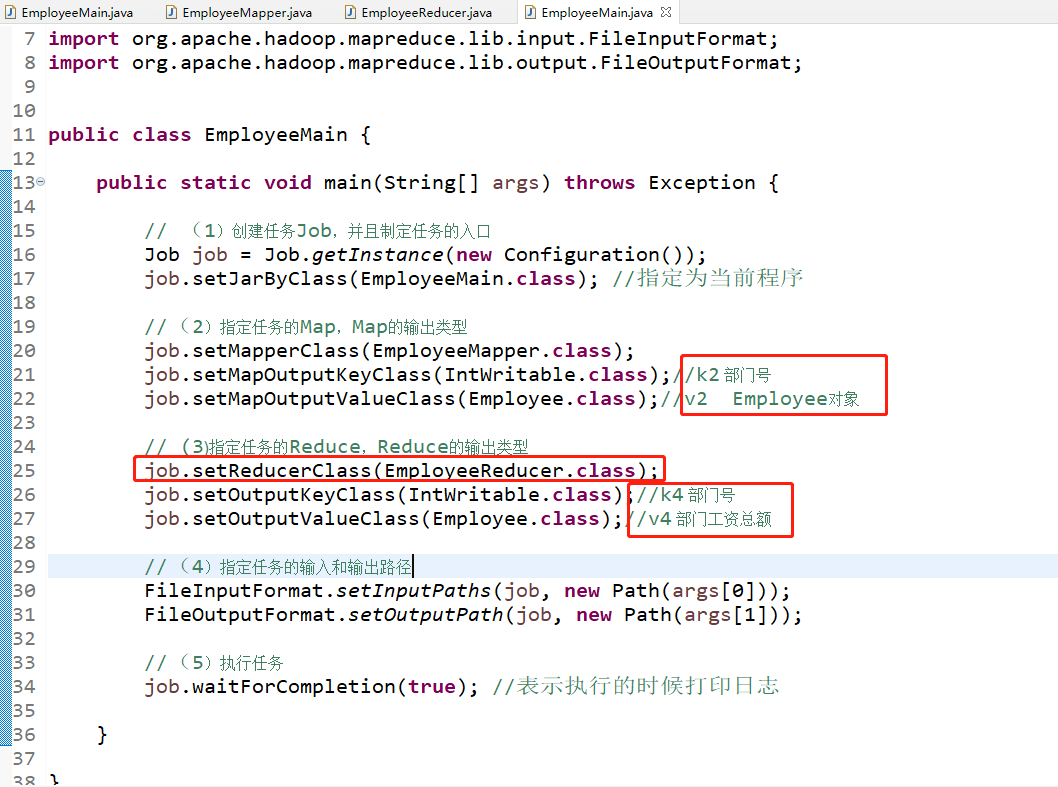
最后就是创建执行的主程序,还是加载模板进行内容的修改,代码部分只需要修改一行,部分注释修改两处就可以了
最后将代码程序打包生成为p4.jar文件,上传到hadoop中进行测试
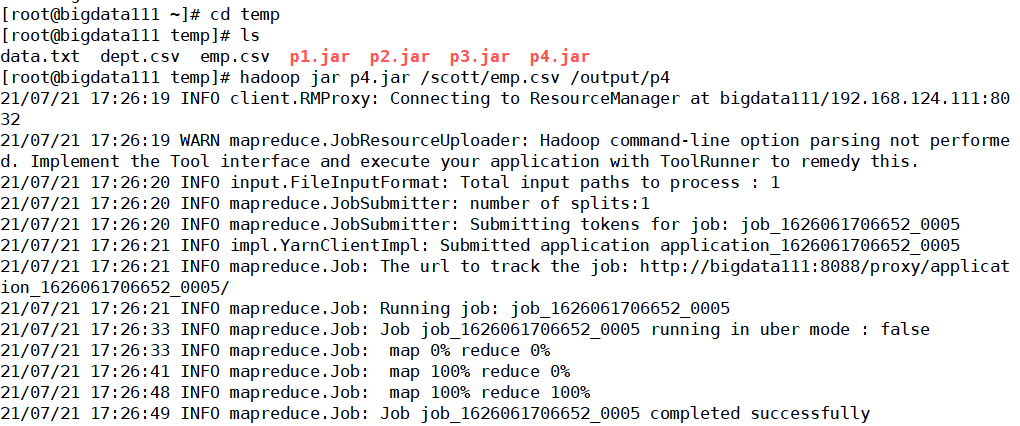
核实一下生成的文件中的信息是否一致(很完美,结果是一样的,啦啦啦)
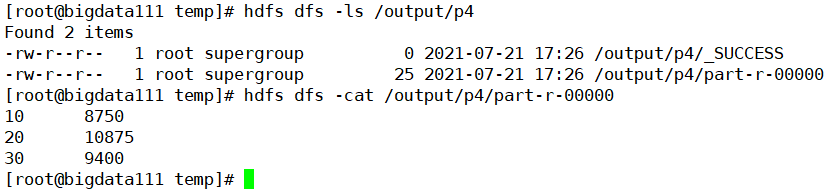
至此关于Hadoop的序列化机制以及序列化案例求解每个部门工资总额的知识点就全部梳理完毕了,完结撒花✿✿ヽ(°▽°)ノ✿