Hadoop序列化的例子
前面讲解了有关序列化方面的东西,为了更好的理解,所以举个栗子。
1.需求:统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备
1 13736230513 192.196.100.1 www.w3cschool.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.lsl.com 1527 2106 200
6 12384188413 192.168.100.3 www.w3cschool.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.lsl.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
3.图解流程

4.代码实现
4.1编写Bean对象
package sumflown;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//1 实现writable接口
public class FlowBean implements Writable {
//上行流量
private long upFlow;
//下行流量
private long downFlow;
//总流量
private long sumFlow;
//2 反序列化时,需要反射调用空参构造函数,所以必须有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
sumFlow=upFlow+downFlow;
}
//3 序列化的方法
@Override
public void write(DataOutput out) throws IOException {
//写序列化数据
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//4 反序列化方法
//5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow=in.readLong();
this.downFlow=in.readLong();
this.sumFlow=in.readLong();
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 6 编写toString方法,方便后续打印到文本
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
//根据需求快速赋值方法,也可不要但其他类的写法要发生改变
public void set(long upFlow2, long downFlow2) {
downFlow=downFlow2;
upFlow=upFlow2;
sumFlow=downFlow2+upFlow2;
}
}
4.2 编写Mapper
package sumflown;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
private FlowBean flowBean = new FlowBean();
Text t =new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
// 1.获取一行
String line = value.toString();
// 2.切割
String[] fields = line.split("\t");
// 3.封装对象
String phoneNum = fields[1];// 获取手机号
long upFlow = Long.parseLong(fields[fields.length - 3]);// 上行流量
long downFlow = Long.parseLong(fields[fields.length - 2]);// 下行流量
flowBean.set(upFlow, downFlow);
t.set(phoneNum);
// 4.写出
context.write(t, flowBean);
}
}
4.3 编写Reducer
package sumflown;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
private FlowBean flowBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
long sum_downFlow =0;
long sum_upFlow =0;
//1.累加求和
for (FlowBean flowBean : values) {
sum_downFlow+=flowBean.getDownFlow();
sum_upFlow+=flowBean.getUpFlow();
}
flowBean.set(sum_upFlow, sum_downFlow);
//2.写出
context.write(key, flowBean);
}
}
4.4 编写Driver
package sumflown;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowsumDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
FileSystem fs = FileSystem.get(conf);
Path input = new Path("D:/input/one.txt");
Path output = new Path("D:/output");
if (fs.exists(output)) {
fs.delete(output, true);
}
//2.设置jar路径
job.setJarByClass(FlowsumDriver.class);
//3.设置mapper和reducer类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//4.设置mapper的key和value输出的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5.设置最终输出的key和value输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6.设置输入输出路径
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
//7.提交job
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
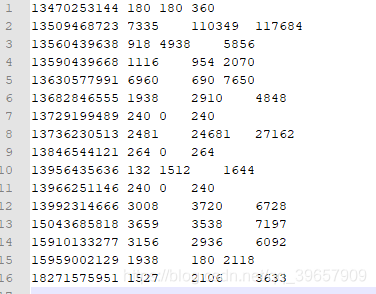
5.结果
版权声明:本博客为记录本人自学感悟,转载需注明出处!
https://me.csdn.net/qq_39657909