这里写目录标题
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/119027211(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 常见的NoSQL数据库
1.1 什么是NoSQL数据库?not only sql
- (1)基于Key—Value格式
关系型数据库:基于关系模式,二维表,面向行,适合执行insert update delete - (2)一般来说,NoSQL数据库中不支持事务Transaction
1.2 常见的NoSQL
-
(1)HBase:基于HDFS之上的NoSQL(本地模式除外)、面向列,适合执行select
主从架构
HBase HDFS
表 ----> 目录
列族 —> 目录
数据 —> 文件(HFile,默认大小128M) -
(2)Redis:基于内存的NoSQL数据库,支持持久化(RDB、AOF)
从3.0版本开始,Redis Cluster去中心化,没有中心节点,不存在单点故障的问题
前身:Memcached缓存,不支持持久化(比如:OpenStack) -
(3)MongoDB:基于文档(BSON文档,就是json的二进制)的NoSQL数据库
-
(4)Cassandra:面向列的NoSQL,类似HBase
去中心化,没有中心节点,不存在单点故障的问题
2 Hbase体系架构和表结构
2.1 Hadoop的生态圈组件
之前的梳理过程中有提及,这次直接以图片的方式展示Hadoop的生态圈组件,目前学习到的也就是中间的两个,HDFS和Yarn(MapReduce),剩下的还有点多哇
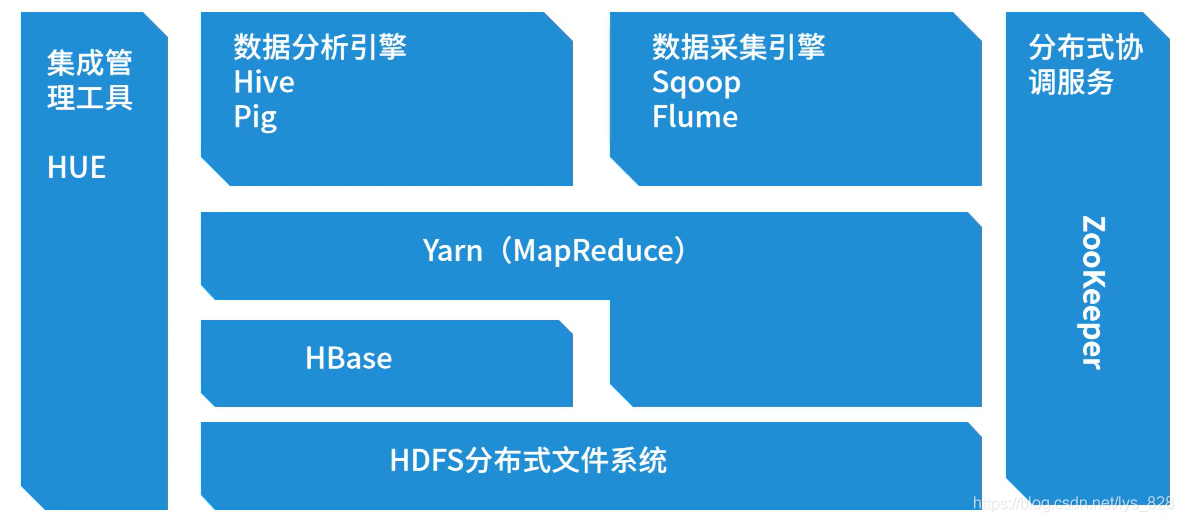
- HDFS分布式系统:最底层的组件,用于解决海量数据的存储问题
- Hbase:基于HDFS之上,所有的数据都是存放在HDFS中,在Hbase中创建一张表时,对应HDFS中就是一个目录,表中的数据就是HDFS中的一个文件
- Yarn(MapReduce):一个不规则的形状,且是在Hbase和HDFS之上的,说明可以处理HDFS中的数据(之前写的程序都是直接处理HDFS中的数据),也可以处理Hbase中的数据(MapReduce中也可以有Hbase接口,从而实现Hbase数据处理)。需要注意Yarn是一个容器,提供一个架子,而真正起作用的是里面MapReduce,相当于发动机的功能,除此之外还可以有其他的发动机,比如spark,flink等
- Hive/Pig:都是数据分析引擎,区别在于Hive支持SQL,Pig支持PigLatin,但是底层都是MapReduce任务运行在Yarn之上
- Sqoop/Flumme:数据采集引擎,实现的是ETL功能,区别在于Sqoop是一个数据交换工具(交换的主要是关系型数据库,可以把Orcle,MySQL或者SQLServer中的数据采集到大数据平台HDFS或者Hbase上,反过来也是可行的,因为它实现的是交换的功能,双向操作),Sqoop的底层也是MapReduce。Flumme也是一个数据采集工具,它的主要特点是采集日志,但是其对应的底层并不是MapReduce
- HUE:基于Web的集成管理工具,可以管理前面的所有内容
- ZooKeeper:分布式的协调服务,用于调节(之前介绍hadoop体系架构的时候,将其比作搭桥的人)
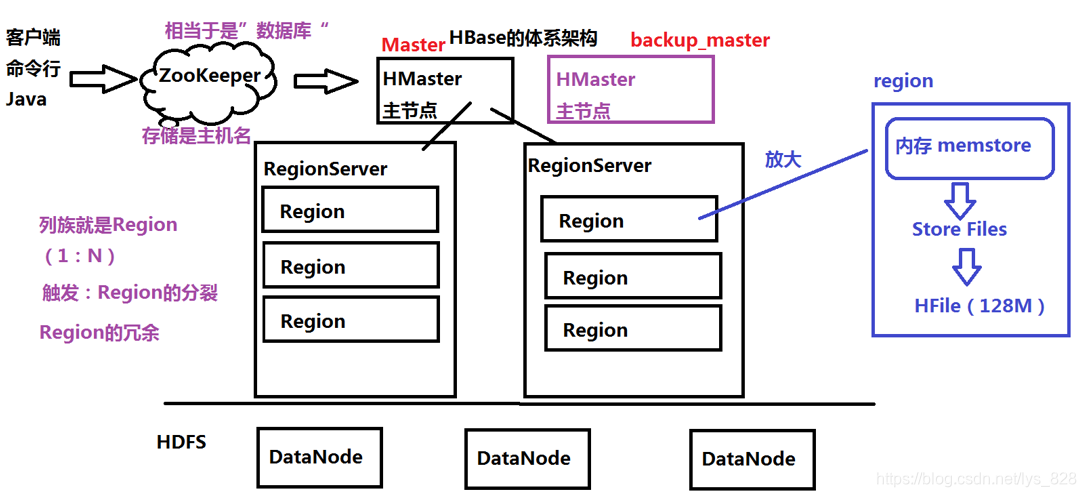
2.2 Hbase体系架构
- Hbase底层是基于HDFS,那么最下就是HDFS,处理数据的职责又是DataNode负责,所以图示的最下面就是这部分内容
- Hbase本身就是一个主从架构,可以分为两部分,主节点HMaster(和HDFS中的NameNode的类似,也不是负责处理数据,只是进行接收请求客户端的请求,管理和维护Hbase整个集群的状态),从节点就是RegionServer(数据存放和处理的地方)
- 列族就是Region,需要注意的一个列族应该对应多个Region,这个表数据的插入有关系,因为所有的数据都在一个大表上面,随着数据的加入一个列族的数据越来愈多,只用一个Region就没有办法进行存放和处理了,因此就需要多个。为了保证数据的安全,可以设置Region的冗余,也就是把数据进行备份
- Region也是一个逻辑单位,把其放大也是占用了一块内存,当存储的文件内容变大了就会形成文件(Store Files),为了提供性能的目的,这个文件并不是直接传递到DataNode进行处理,而是在达到128M时候形成HFile后再转送到DataNode
- 既然是主从架构,就会出现单点故障的问题,因此就需要ZooKeeper,进行备份主节点,当然只有一个是启动运行,当主节点损坏后,备份的才启动
- 集群状态的节点信息都存放在ZooKeeper上,需要注意的是存储的是主机名称(并不是ip地址),需要通过主机名来解析ip地址
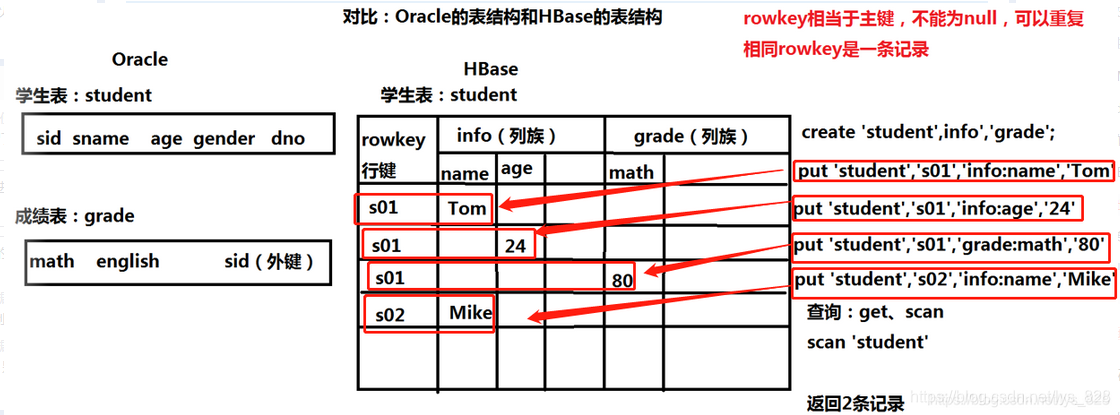
2.3 Hbase表结构
之前已经进行介绍了,谷歌的三篇论文中的BigTable大表,这里直接给出分析的图,但是有一点需要注意,之前的数据库都是有数据类型,这里的Hbase并没有数据类型,都是二进制
至此,关于常见的NoSQL数据库和Hbase体系架构和表结构的知识点就梳理完毕了,撒花✿✿ヽ(°▽°)ノ✿