Inf2vec: Latent Representation Model for Social Influence Embedding
2018 IEEE 34th International Conference on Data Engineering
1. 前言
感觉这篇文章和自己之前做的研究方向挺相似的,所以这里想更加细致的看看这个工作,看有什么不同。且有什么值得注意和改进的。
所以,看这篇论文的目标是:
- 完全理解这篇文章在做什么;
- 理清楚和自己之前做的工作有什么本质上或者表面上的区别;
- 代码复现;
- 实验复现;
虽然前几天也在看这个论文,但是因为前几天比较感兴趣做项目,所以也就只看了摘要部分。这几天自己想集中精力把上面的四个任务点给完成。
时间:2021年11月13日 18:39:22
2. 阅读笔记
文献2提出了EM算法在IC模型下来推断用户u到v的传播概率;
文献3使用共现次数来评估传播概率;
文献5提出了主题认知的影响分析;
文献21提出了一个置信分布模型,可以根据以前的传播中直接的学习到Top k影响力用户;
这些所有的工作都在分析学习影响参数,并且以前的工作都没有考虑到用户兴趣相似度。最关键的是由于网络的稀疏性,这些现有的方法并不能有效的学习到网络中的影响参数。
为了描述本论文的工作和传统的工作的差别,在论文中作者使用了一个图来进行说明:
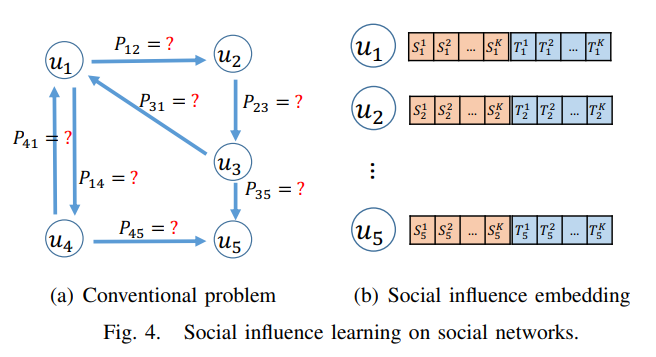
传统的方法来建模社交网络中的影响学习问题,通过学习每个边的传播概率来实现。也就是上图左边的依次评估网络中边的传播概率问题。
作者认为整个网络可以使用上图右边的嵌入矩阵来表示,两个用户之间的传播关系可以建模为两个向量之间的相似度来刻画;
因为注意到传播是有方向的,为了反应这种社交影响的方向性,每个用户都具有两个向量,即图中的S和T:
S, 即Source representation。表示该用户影响他人的能力;T, 即Target representation。表示该用户被其他用户影响的趋势;
可以使用Embedding来替代传播过程,主要是因为作者的主要观点为:
节点在低维空间中被表示为向量,因此这些向量可以反映社交影响信息。
与现有的估计边概率的影响学习工作相比 [2]、[3]、[10],我们对社会影响嵌入问题的解决方案旨在通过有效捕获用户之间的影响关系并处理数据稀疏性问题。
为了得到最终的嵌入表示,论文中工作大致两个步骤出发:
generate the social influence context;即采用和DeepWalk、node2vec等类似的方式来处理;- 通过上下文来学习最终的表示;
因为在之前的影响力模型中没有工作做过用户兴趣,所以在本文中作者尝试将用户兴趣相似性刻画进传播影响模型中。
2.1 局部用户相似性上下文(Global User Similarity Context)
作者认为仅仅是first-order neighbors不足以描述图中的局部影响力,因为比如说u1影响到u2,而u2影响到u3,那么就可以说u1对u3可能具有非直接影响力。
所以,作者认为需要考虑high-order influence propagation。因为在论文中作者首先在数据集中抽取社交网络影响pairs,所以可以根据这种链接关系进一步得到二阶、三阶等关系。
在论文中作者定义了一个影响传播网络(Influence Propagation Network),比如下面的案例:
通过原本的社交网络有向图以及一个时刻的收到消息的前后关系就可以推断出这个网络的影响传播网络,为右边所示。
因为u4是第一个,u1是最后一个,所以很有可能u4是消息发出者,u1是消息接受者。所以根据左边的社交网络结构图,可以推断出:
u3 -> u1,u4 -> u1,u4 -> u5
由于u2接收消息在u3之前,所以可以推断出:
u2 -> u3
也就是最终的上图的右边的结果。
所以作者就可以根据数据集中的各个时期的时序关系,抽离出一个个网络子图。即:G -> G_i
然后在得到的这些网络子图中,就可以开始进行随机游走的过程,从而得到和传播相关的上下文语料库。
在采样到的影响传播序列中,因为是随机的,所以可以说采样到了高阶的影响high-order influence propagation。因为作用在多个网络子图中,所以在一定程度上也就解决了网络中传播数据稀疏性的问题。
2.2 全局用户相似性上下文(Global User Similarity Context)
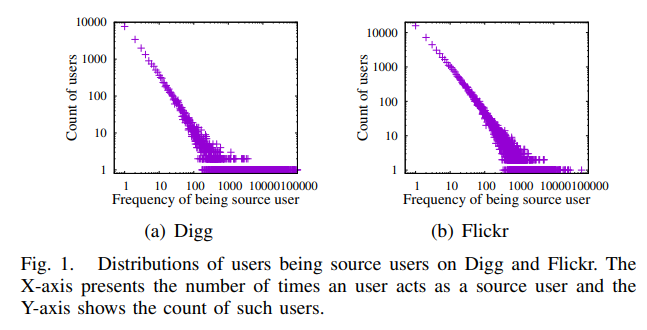
用户行为不总是因为社交影响力。作者在文中使用了累积分布函数(cumulative distribution function)来计算在用户之前执行相同操作的朋友数量的累积分布函数 (CDF),以研究社会影响对用户在线行为的影响。
结果如下图:
首先看下累积分布函数是什么:
又叫分布函数,是概率密度函数的积分
注意到,当用户没有朋友的时候(x=0),CDF的值分别为0.5和0.7。也就是说在数据集Digg和Flickr中50%、70%的人在没有他们朋友影响的时候也会产生活动。
而随着用户朋友数目的增大,CDF的值在逐渐增大,说明朋友数目的多少确实在一定程度上会影响用户的活动。
所以从上图中可以得出作者的结论,即:
用户行为不总是因为社交影响力。
所以在全局用户相似性上下文部分,文中进一步考虑了用户偏好相似性。
用户在线行为反应了用户自己的兴趣,所以具有相似兴趣的用户更有可能具有相似的行为。
对于数据集中的每个用户来说,都会产生自己的行为。且在前面的传播子图中,因为那个影响传播子图就是因为传播行为而生成的,所以可以认为他们对这个主题感兴趣。
但是相比于传统方法而言,在IC模型中融合用户兴趣还是比较困难的。
2.3 得到上下文的最终算法
最后的算法伪代码很简单:

2.4 学习嵌入表示
这里其实也就是套壳,套入到Word2vec模型中。但是确实在这个里面加入了一些自己的新东西,比如前面所填到的S和T的两个矩阵。
且文中还引入了两个偏置项,b_u和b_v’,分别表示用户u自己的影响偏置,用户遵从用户v的影响偏置。
那么用户v被用户u影响的概率可以定义为:
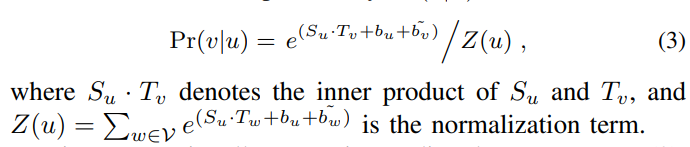
定义为一个softmax函数来得到一个0-1的概率值。
如果说每个用户之间是相对独立的,那么对于每个子图中采样得到的概率就可以表示为:
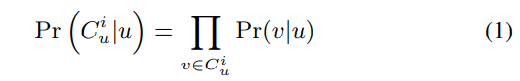
那么最终的优化目标就是整体的概率最大,即:
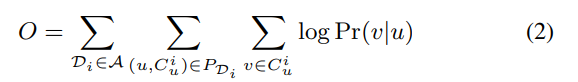
因为上式为累乘,这里对它取对数,这里从第一个式子开始:

然后使用梯度下降进行参数优化,即:
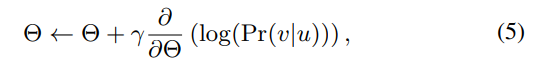
进一步将公式4进行展开,求梯度:
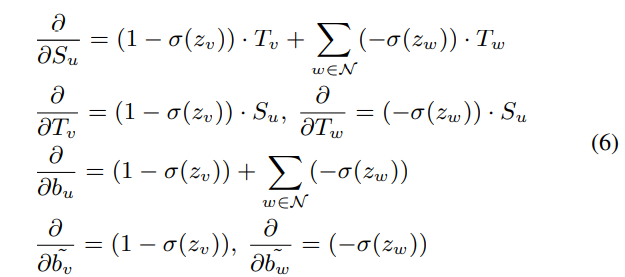
最终的更新算法为:

References
- Inf2vec: Latent Representation Model for Social Influence Embedding