1. 简介
- hadoop
hadoop实现了一个分布式文件系统HDFS,框架核心设计:HDFS和MapReduce。 - spark
spark 是专为大规模数据处理而设计的快速通用的计算引擎,支持 Hadoop YARN。spark框架易用性高,与pyspark,Spark SQL,机器学习等的交互友好。
使用总结:hadoop提供分布式集群和分布式文件系统,spark使用hadoop的HDFS代替MapReduce进行大数据的计算处理。
2. ambari集群安装
- 服务器环境:CentOS 7.6
- 节点: master,node01,node02
- 方法:采用ambari平台安装hadoop
2.1. 配置集群master节点与其它节点免密访问
# master节点上
ssh-keygen
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
# 其它节点
mkdir ~/.ssh/
# master节点
scp /root/.ssh/authorized_keys root@<node ip>:/root/.ssh/authorized_keys
2.2. 创建ambari用户【master】
adduser ambari
passwd ambari
2.3. 【所有节点】开启NTP服务、关闭防火墙、Selinux
yum install ntp -y
systemctl is-enabled ntpd
systemctl enable ntpd
systemctl start ntpd
systemctl disable firewalld
systemctl stop firewalld
sestatus
# 临时关闭,不用重启机器:
setenforce 0
# 修改配置文件需要重启机器:
vi /etc/sysconfig/selinux
SELINUX=disabled
2.4. 【所有节点】配置ip映射
<ip> master.ambari.com master
2.5. 【master】制作本地源(从内网指定服务器中下载资源)
yum install httpd -y
firewall-cmd --add-service=http
firewall-cmd --permanent --add-service=http
systemctl start httpd.service
systemctl enable httpd.service
yum install yum-utils createrepo -y
2.6 【master】下载安装包
由于网络问题,无法下载,手动下载安装包后,离线迁移到待安装的服务器上
mkdir /opt/install;cd /opt/install
# Ambari 2.6.0
wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0/ambari-2.6.0.0-centos7.tar.gz
# HDP 2.6.3
wget http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/HDP-2.6.3.0-centos7-rpm.tar.gz
# HDP-UTILS 1.1.0.21
wget http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz
!!!!!!!todo(事好多,后面再补)
3. yarn 管理
3.1. yarn 资源监控页面
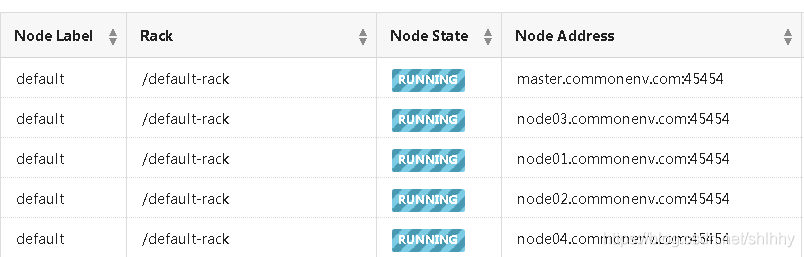
yarn集群有时任务阻塞,提交到集群的任务处于ACCEPT状态,可以监控当前集群上的资源,并采用下列语句杀掉阻塞进程。
yarn application -kill application_Id
批量杀掉阻塞的任务
for i in `yarn application -list | grep -w ACCEPTED | awk '{print $1}' | grep application_`; do yarn application -kill $i; done

4. Spark运维
4.1 问题积累
- 采用spark访问hive执行sql语句时,报错,推测是spark连接hive元数据未成功,排查后, 成功访问
- 复制hive配置文件,/etc/hive/3.1.4.0-315/0/hive-site.xml
- 替换到spark配置目录下,/etc/spark2/3.1.4.0-315/0/

5. Hadoop运维
- 安装hadoop 3.1版本后,作为HDFS存储的三个节点在运营3个月后出现磁盘爆了(481g/499g)问题
- 经排查,发现存储目录:/hadoop/hdfs/data 占用极高,该目录下生成了大量的blk文件、元数据文件
- 打开blk文件查看发现内容包括小的数据文件、spark监听日志文件、其它不知含义的文件等

- 查看hdfs上的目录
hdfs dfs -ls /
- 查看某一目录下的数据量,发现spark2历史文件占用高达300g,/ranger目录占用58g,/warehouse目录占用38g
hdfs dfs -count /spark2-history/
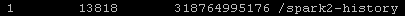
- 进入spark的配置文件目录:/etc/spark2/3.1.4.0-315/0/,打开spark-defaults.conf文件查看
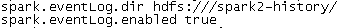
- 调整spark日志的配置【集群所有节点】
spark.eventLog.compress true # 日志是否压缩
spark.history.fs.cleaner.enabled true # 日志是否清理
spark.history.fs.cleaner.interval 1d # 日志检查间隔
spark.history.fs.cleaner.maxAge 7d # 日志最长保留时间
- 清空历史spark日志,日志文件被移入Trash中,接着清空Trash目录,磁盘空间恢复正常
hdfs dfs -rm /spark2-history/*
hdfs dfs -rm -r /user/root/.Trash/Current/*
