Python多线程
参考
https://www.bilibili.com/video/BV1bK411A7tV?p=1
CPU密集型计算
CPU密集型(CPU—bound)
CPU密集型也叫做计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率高
例如:压缩解压缩、加密解密、正则表达式搜索
IO密集型计算
IO密集型指的是系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率低
例如:文件处理程序、网络爬虫程序、读写数据库程序
多进程、多线程、多协程的对比
一个进程中可以启动N个线程
一个线程中可以启动N个协程
多进程 Process (multiprocessing)
-
优点:可以利用多核CPU并行运算
-
缺点:占用资源最多、可启动数目比线程少
-
适用于:CPU密集型计算
多线程 Thread (threading)
-
优点:相比进程,更轻量级、占用资源少
-
缺点:
-
相比进程:多线程只能并发执行,不能利用多CPU(GIL)
-
相比协程:启动数目有线程,占用内存资源,有线程切换开销
-
-
适用于:IO密集型计算、同时运行的任务数目要求不多
多协程 Coroutine (asyncio)
-
优点:内存开销最少、启动协程数量最多
-
缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂
-
适用于:IO密集型计算、需要超多任务运行、但有线程库支持的场景
GIL
GIL的全称是:Global Interpreter Lock,意思就是全局解释器锁

即使电脑有多核CPU,单个时刻只能使用一个。
多线程threading机制依然是游泳的,用于IO密集型计算
因为在I/O期间,线程会释放GIL,实现CPU核IO的并行
但是多线程用于CPU密集型计算时,只会更加拖慢速度
使用multiprocessing的多线程机制实现并行计算、利用多核CPU优势为了应对GIL的问题,Python提供了multiprocessing
创建多线程的方法
单线程是通过顺序的。
多线程是无序的顺序。
多组件的Pipeline技术架构
复杂的事情一般都不会一下子做好,会分成多个步骤一个个完成

生产者消费者爬虫的架构
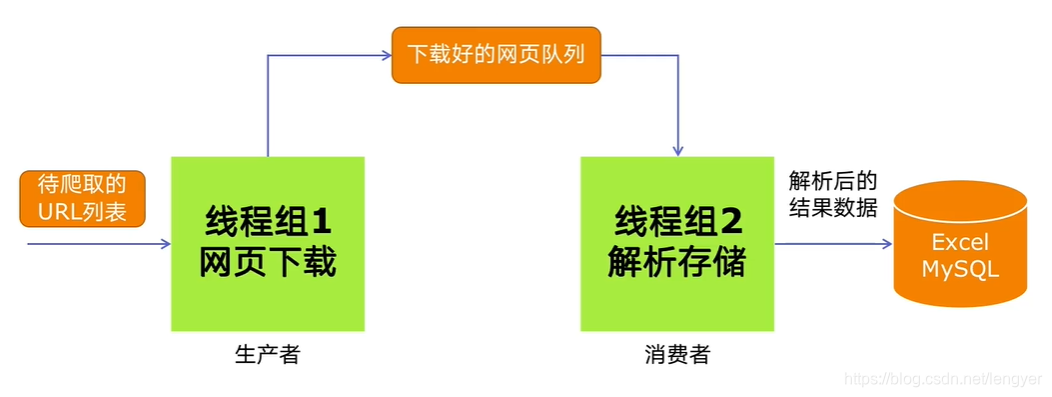
多线程数据通信的queue.Queue
用于多线程之间的,线程安全的数据通信
1、导入类库 import queue 2、创建Queue q = queue.Queue() 3、添加元素 q.put(item) 4、获取元素 item = q.get() 5、查询状态 # 查看元素的多少 q.qsize() # 判断是否为空 q.empty() # 判断是否已满 q.full()
线程安全概念
线程安全指某个函数、函数库再多线程环境中被调用时,能够正确的处理多个线程之间的共享变量,使程序功能正确完成。
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全
用lock解决线程安全问题
用try-finally模式
import threading lock = threading.Lock() lock.acquire() try: ... finally: lock.release()
用with模式
import threading lock = threading.Lock() with lock: ...
线程池的原理

新建线程系统需要分配资源、终止线程系统需要回收资源
如果可以重用线程,则可以减去新建/终止的开销

优点:
1、提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;
2、适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题
4、代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
ThreadPoolExecutor的使用语法
from concurrent.futures import ThreadPoolExecutor,as_completed
with ThreadPoolExecutor() as pool: results = pool.map(craw, urls) for result in results: print(result) # 用法:map函数,很简单,注意map的结果和入参是顺序对应的
with Thread PoolExecutro() as pool:
futures = [ pool.submit(craw, url)
for url in urls ]
for future in futures:
print(future.result())
for future as_completed(futures):
print(future.result())
# 用法: future模式,更强大,注意使用as_completed顺序是不定的
使用线程池ThreadPoolExecutor加速
优点:
1、方便的将磁盘文件、数据库、远程API的IO调用并发执行
2、线程池的线程数目不会无线创建(导致系统挂掉),具有防御功能
多进程multiprocessing
有了多线程threading,为什么还要用多进程multiprocessing
虽然有GIL但多线程依然可以加速运行
CPU密集型计算
线程的自动切换反而变成了负担
多线程甚至减慢了运行速度
multiprocessing模块就是python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU并行执行
多进程和多线程的使用方式几乎完全一样


Python异步IO库介绍:asyncio
import asyncio # 获取时间循环 loop = asyncio.get_event_loop() # 定义协程 async def myfunc(url): await get_url(url) # 创建task列表 tasts = [loop.create_task(myfunc(url))for url in urls] # 执行爬虫事件列表 loop.run_until_complete(asyncio.wait(tasks))
注意:
要用在异步IO编程中
依赖的库必须支持异步IO特性
爬虫引用中:
requests不支持异步
需要用aiohttp
信号量(英语:Semaphore)
信号量(英语:Semaphore)又称为信号量、旗语
是一个同步对象,用于保持在0至指定最大值之间的一个计数值。
-
当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;·当线程完成一次对semaphore对象的释放(release)时,计数值减一。
-
当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;·当线程完成一次对semaphore对象的释放(release)时,计数值加一。
-
当计数值为O,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态. semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态。