多任务
- Linux是多用户多任务的操作系统
- 多任务的意思就是同时进行。比如,不能先站着唱完歌,再跳舞。
- 怎么同时进行呢?
答:cpu的多个核同时工作。
- 但是这就有一个问题了,现在电脑普遍四核,高端点八核。最多只能同时处理八个任务?还有我手上现在用来编程的单片机,只有一核,只能处理一个任务?
- 显然不是的。当任务数小于核心数,就是真的多任务,叫并行
- 当任务数大于核心数,就是假的多任务,叫并发
- 并发 就是某个核执行任务时,快速的切换,让我们感觉好像在一起运行一样。可能每个程序执行0.0000…1秒就切换到下一个程序了。换言之,就是切换任务的速度非常快,使我们产生了错觉。
- CPU一秒钟执行好几百万次。
- 具体每一个程序分配多久,取决于算法调度(比如优先级调度中,因为听歌之类的不希望有断断续续的感觉,所以听歌的优先级很高)。
一、多线程
- 程序是按照结构一行一行执行的,这被称为一个线程。一个程序运行起来之后,一定有一个执行代码的东西,这个东西就被称之为线程。
- 想像一个箭头,它指到哪就执行到哪。这个箭头就是一个线程,多线程就是有多个箭头。

1)对比单线程与多线程
1.单线程
- 代码如下:

- 效果如下(耗时6秒):

2.多线程
- threading模块中有一个类叫做Thread,给它的Target参数传入方法/函数/和一切可执行的操作创建出来一个实例。只要这个实例调用了start方法,就生成一个独立的线程。
import threading.Thread
......
变量名 = Thread(target=函数名)
变量名 = Thread(target=函数名)
变量名 = Thread(target=函数名)
- 代码如下:


- 效果如下(耗时1.5秒):

2)enumerate()方法
- 一个程序启动时,一定有一个线程叫做主线程。当调用模块,开启另一个线程,这个线程就叫子线程。
- 主线程没有可执行的代码时,子线程若还在,主线程会等子线程结束。
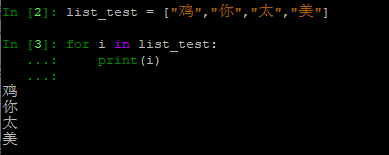
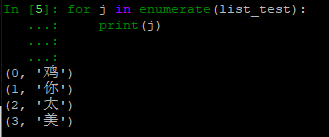
- enumerate()可以查看程序当前的线程。
len(threading.enumerate())
- enumerate函数,可以将可迭代数据的每一个元素,变为元组。当然,threading中的这个函数不是这个意思哈,只是示例。
- 看看把延时模块删除之后发生了什么,代码如下(导入模块代码变化,新增线程数量代码):

- 执行效果如下(重复执行三次,看看有何不同):
- 会发现所有线程执行没有先后顺序。说明线程的执行是看操作系统调度的(看它心情)。



- 想指定线程的先后顺序,可以使用延时
- 如果想所有子线程结束后程序就结束,可以用if加enumerate长度判断退出。
- 主线程如果先结束了,子线程必结束。
- 子线程是从调用start()开始的,可以用enumerate长度判断
3)多线程执行类
- 要通过多线程执行类,需要继承threading.Thread,调用start()时,start()会自动调用类里面的run方法。注意一个start()值生成一个线程
Class NewClass(threading.Thread):
def 函数名(self):
......
if __name__ == "__main__":
变量名 = 类名()
变量名.start()
- 代码如下:

- 结果如下:

这里没有使用延时,说明只有一个子线程。(主线程在等子线程执行完毕)
4)子线程之间使用的全局变量可以共享
- 使用一个函数修改全局变量,看看另一个函数调用的结果如何
- 代码如下:

- 结果如下:

- 说明全局变量可共享
5)通过args为函数传递参数
- 直接一个函数名是使用变量
- 函数名加括号是调用函数
可是没有括号如何为函数传递参数呢?
threading.Thread中有一个参数可为函数传递参数,就是args,它接收的参数是一个元组。
- 代码:

- 效果:

- 多任务往往配合使用,所以要共享
6)资源竞争
- 多线程有可能会出现资源竞争,导致报错
- 代码如下,把times改为一百万看看

- times等于100时:

- times等于100万时:

- 怎么不等于200万?python是一门高度简洁的语言,gl_num += 1,其实可以分为许多步
- 找到变量
- 更改变量引用
- 存储变量引用
- 然后CPU在分配任务时,可能变量改变还没存储,就切到另一个线程去了。
- 那为什么100不会出错呢?答:会出错。出错是个概率,样本数太小了,恰好没错而已。
7)解决资源竞争
- 之所以出问题,就是因为一个线程还没走完,就去执行另一个线程了。可以通过线程同步来解决。
- 为了不发生资源竞争,就要让一个线程走完,这就是原子性,在这里也可以叫事务。
- 同步就是协同步调,按预定的先后次序进行运行
1.互斥锁
- 当多个线程几乎同时修改一个共享数据时,就需要进行同步控制
- 某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
# 创建互斥锁,默认是没有上锁的
mutex = threading.Lock()
# 上锁(取得)
mutex.acquire()
# 解锁(释放)
mutex.release()
- 同一把锁,只能上一次,谁先上谁用。
2.上锁使一个线程执行完
- 代码:

- 结果:

3.上锁使一个线程必要的部分执行完
- 执行完一个线程,再执行另一个线程,和单线程有啥区别?
- 所以,上的锁越小越好。
- 代码:

- 结果:

8)死锁
- 死锁是一种状态
- 在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
避免死锁
- 程序设计时要尽量避免(银行家算法)
- 添加超时时间
银行里有10亿时,凭什么敢放贷20亿?得益于银行家算法。
→银行家算法←
- 在设计时,心里要有一杆秤,到上面时候哪一把锁会解开,解开后会导致连环解锁。
9)udp多线程聊天器
- 有一个问题:是该创建一个套接字呢,还是两个?答案是一个,为什么?因为udp是双工,既可以接又可以发。
- 把接收和发送的功能封装。然后添加线程即可,代码如下:

- 效果图就不贴了。
二、多进程
- 进程就是进行中的程序。进程拥有资源(比如网卡信息,摄像头使用能力等),进程就是一个资源分配的代码块。
- 进程 = 代码 + 用到的资源

- 进程有三个状态:就绪态、执行态、等待态
1)实现多进程
- 和多线程一模一样(就换个对象。我把多线程改成多进程,都是直接使用末行模式的替换):

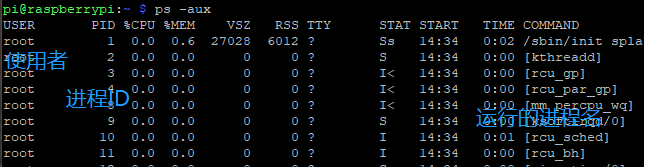
- shell中,输入 ps可以看到正在运行的进程(只有部分,想看到全部加-aux):
这里的三个就是一个主进程,两个子进程
杀死进程,shell中用kill 进程ID

2)进程补充
- 多进程是什么?
- 进程就是代码加资源。多进程就是,把资源复制一份,然后指定了代码的开始位置。(代码不复制是因为,代码不会变,是共享的)
- 进程耗费的资源大
- 进程浪费了内存,但是提高了效率(一定范围内的,如果进程数过多,会卡)
- 原则上,能共享就共享。实在当,通过特殊手段修改代码时,代码才会复制。这叫写时拷贝
进程与线程的区别
- 先有进程,才有线程。
- 进程仅仅是一个资源分配的单位,资源单位的总和,上面的线程拿的资源最多。
- 线程是进程调度和分配的基本单位。
- 多线程就是同一个资源里有多个执行代码的东西。
- 多进程就是有多个资源。
- 区别:
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
- 一个程序至少有一个进程,一个进程至少有一个线程.
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
3)进程间通信
- 线程间资源是共享的,美滋滋。但是进程间不是,需要用对方的资源,必须通过通信。
- 进程间通信,有很多种机制:
- 进程间通信,可以用socket。
- 进程间通信,可以用文件(文件在硬盘上,所以速度较慢)。
- 可以设想,如果在内存中开辟一块地方,进程把数据存到这个内存中,另一个进程访问这块内存就完成了通信。
- Queue队列
- 先进先出,就叫队列
- 用Queue的一个主要目的是:解耦
耦合性高,有可能,改了一小块代码,其它一大片地方要跟着改,不然程序就完蛋了。
- 队列使用的代码:

- 需要在创建进程前就创建好一个队列。
- 实际操作时代码如下:

- 效果如下

4)进程池Pool
- 进程池,就是先创建一个池,里面有许多进程,先执行一部分进程,然后某些进程结束了,新的进程通过重复利用,来提高效率,节省资源。(进程池会自己管理)
- 进程的创建是需要消耗大量资源的,进程池很好地解决了这一点。
- 进程如果不多,不要创建进程池。
- 进程池会重复利用进程去做事情。

上图进程池有三个进程,当某个程序执行完后,下面等待的程序就会被空闲出来的进程取用,从而达到重复利用的效果。
- 进程池使用代码:

5)复制文件夹
1>明确目标
1.准备工作

2.准备一些供下载的文件
- 我们直接获取python的标准库文件
__file__方法,可以获得库的路径

2>逐步实现
1.大体流程
- 获取用户想下载的文件名
- 创建一个同名文件夹
- 获取待复制文件夹的目录(打印出来看看对不对)

2.尝试拷贝
- 如果文件夹已经存在?会报错,所以使用try
- 为了多进程,且不知道有多少文件,使用进程池
- 添加拷贝的任务入进程池

3.简单拷贝
- 怎么知道拷贝谁,拷贝到哪去?==>添加参数
- 注意:不加join可能会完不成(看不到执行结果)

- 效果:

4.真正拷贝
- 完善打开文件代码
(别想不开尝试打印取到的内容,多个进程同时执行,打印在终端是串在一起的)

5.显示拷贝进度
- 添加显示进度功能
- 思路:
- 主进程闲着,所以让主进程来干
- 可以创建一个队列,子进程完成后向队列添加,让主进程读取
- 用了进程池。主进程要和子进程通信,不能用multiprocessing.Queue(),而要用multiprocessing.Manager()创建出来的对象下的一个Queue()方法
- 就是multiprocessing.Queue() 变为 multiprocessing.Manager().Queue()
- 流程
- 创建一个队列,子进程结束时,向队列传入一个消息(任意消息,比如1啊。我这里用了文件名,一个字符串。)
- 为了让主进程,不等待子进程执行完再执行下方代码,删除join()
- 主进程使用q.get()来取数据,只要队列空了,就会阻塞。
- 阻塞需要强制停止(复制完成时)。可以添加两个变量,一个变量记录文件列表总数,另一个记录完成的进程数(利用计数器),添加一个if条件判断退出。
- 进度 = (完成数/总数)* 100%
- 我这里执行代码出现了编码报错,因为中文。所以在第一行添加:

- 完整代码:


- 结果:(记得先把之前执行代码产生的复件删了)

6.进度缓冲在一行
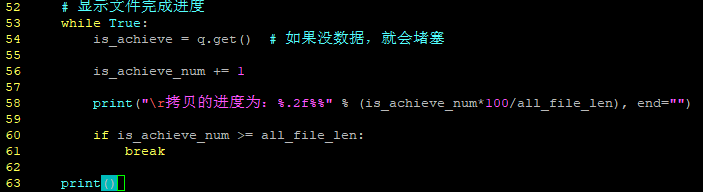
- 能不能打印在一行?结束时不换行就行了(end=""),看结果:

- 诶,怎么回事?哦!虽然是不换行,但打印是连着打印的,如果打印在行首,就能覆盖掉之前的打印了。可以使用
\r回车,不换行完成。 - 还有一个问题,shell输入的行紧接着打印内容的末尾,所以最后加个换行
- 最终代码如下(部分)
- 结果:

三、多协程
1)迭代器
1>实现迭代器
- 迭代: 在一个文件的基础上新增一个大功能,或一个小功能,就叫做迭代。
- 可以迭代的对象,必有
__iter__类。 - 可以迭代的对象,必是Iterable的子类
- 判断一个类是否是另一个类的子类,可以用
collections下的isinstance方法

- 执行结果:
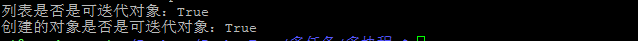
2>可被for循环的迭代
- 使用for循环时,好像有一个东西来记录迭代到了哪个元素
- 使用for 遍历时,其实有两个步骤。
- 判断in后面的对象是否可以迭代
- 在第一步的基础上,调用iter()函数得到一个对象的
__iter__方法的返回值__iter__方法的返回值,是一个迭代器- 每for一次,就会调用一次
__next__方法,返回它的返回值。返回什么,就看见什么。
- iter()是一个魔法方法,当调用时,它就把希望有迭代功能的那个类创建的对象,放在里面传递。类似于: iter(user)。然后,自动地调用里面的
__iter__方法,得到一个返回值。这个返回的对象,叫做迭代器。 - 如果是迭代器,必是Iterator的子类。
- 代码如下:

- 结果如下:
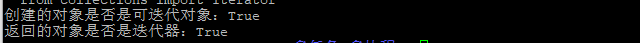
3>被遍历成功时返回的迭代
- next(迭代器对象) 是一个魔法方法,它会调用迭代器对象的
__next__方法,并返回其返回的结果。 - 每一次for都是调用了一次next()方法。其实list()、tuple()转换类型,也是先取出,再写入的过程。
- 可以将希望遍历的类,作为参数,传入迭代器中,以获得参数
- 使用raise来抛出StopIteration异常以停止遍历
- 代码:


- 结果:

4>整合代码
- 既然,迭代器也含有
__iter__,说明它是可以被迭代的 - 那么,我们可以将两个类,整合变成一个类。
- 注意,
__iter__返回self即可,因为自身本来就是迭代器对象 - 代码:

- 一个对象是迭代器,一定可迭代
- 一个可迭代的对象,不一定是迭代器
5>迭代器的应用场景
- 在一个程序里,如果需要用到很多值,可以:
- 找个列表之类的存起来
- 什么时候需要,什么时候取出
- 这其实是两种思想,一种是直接存储结果,一种是存储得到结果的方法。迭代器存储的是方法,随取随用,省空间。
- 在python2中,range以列表形式存储结果,xrange存储的则是方法。如下:
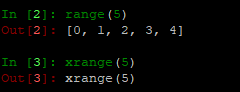
- 在python3中,range实际上为xrange。
6>迭代器案例:兔子数列
- 定义两个数0, 1,后面的数分别是其前两个数的和,这样一个数列,称为斐波那契数列,也称兔子数列。
- 列表法(代码):

- 列表法(结果):

- 迭代器法(代码):

- 迭代器法(结果):

2)生成器
- 生成器是一种特殊的迭代器
- 只要有yield,就是生成器
- 生成器可以保证函数只执行一部分
1>列表生成式变为生成器
- 只要把列表生成式的
[]改为()即可

2>改造兔子数列
- 只要函数中,出现yield,它就不会被识别为函数,而是一个生成器对象
- 执行时,每次碰到yield就会暂停,并且返回yield后面的值(这个值可用next方法接收,也可用for等接收)。每调用一次next(),代码就会继续执行。
- 代码:

- 结果:

- 说明yield确实起到了暂停的作用
- 注意: 生成的生成器对象,是相互独立的
3>return
- 可以在代码最后添加return关键字,需要得到return关键字返回的结果。需要通过抛出的异常StopIteration下的value属性来返回。
- 代码:

- 结果:

4>send
- 除了next可以启动生成器外,send也可以
- send可以传参数入生成器,可以起到控制的作用
生成器.send("传入的值")
- 代码:

- 代码执行完第5行时,发现第6行是个赋值语句,于是先执行等号右边的,因为是个yield语句,所以暂停,返回的值,通过next或send或for等取出。同时因为send或next启动了生成器,生成器继续运作。
- send发送了数据,赋值给了等号左边的变量s。
- 结果:

3)使用yield实现多任务
- 通过生成器让任务交替执行,形成多线程
- 代码:

- 协程调用一个任务就像调用一个函数一样,它调用的资源最少。线程和进程依次增多。
1>使用greenlet升级多协程
-
greenlet是封装了yield,使其更简单好用
-
安装greenlet
sudo pip3 install greenlet
- 代码:

2>使用gevent升级多协程
- 实际在写代码时,常用的是gevent
- greenlet已经实现了协程,但是还得人工切换
- greenlet有一个问题,如果函数中有一个延时,内部根本不会切换,这根本不是多任务。gevent就解决了这点,在延时时,也会进行。
- 安装gevent
sudo pip3 install gevent
- 代码:

- 效果:

- 等待一个对象执行完,再执行下一个,这是多任务吗?有没有可能是执行地太快了?
- 可以加个sleep延时来验证是否是多任务,代码:

- 效果: (说明真的不是多任务)

3>使用gevent完成真正的多协程
- gevent实现多任务需要的延时,不是time.sleep,而是gevent.sleep,代码如下:

- 效果如下:

- 如果要使用多协程,必须把所有 需要延时 的操作都换为gevent, 比如socket.connect 要换为 gevent.connect
- 多进程是创建多个程序,多线程是一个程序里面创建多个读取的工具,多协程就是在一个对象内部堵塞时,利用堵塞的时间,去执行其他代码。
4>使用猴子补丁升级代码
- 如果一个几万行的代码,全部变为gevent下延时操作,那不是太繁琐了。所以,要打个猴子补丁:

- 结果:

- 猴子补丁的作用是:遇到延时操作,将其换成gevent.
5>使用joinall升级代码
- 一个个join太繁琐了,可以使用joinall([…])

4)并发下载器
1>从网上下载文件
- 访问网站,并down下源码

- 尝试down一个图片
我使用的网址是: http://http://222.186.12.239:20012/uploadfile/2019/0916/20190916045739355.jpg
- 代码如下:

- 效果如下:

2>下载多张图片
- 代码:

- 效果:

5)进程、线程、协程
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
