架构设计看着高大上,其实到最后都会投射到细小的技术细节上去。甚至对技术细节的把握程度决定了架构设计的思路,最终影响工作量,甚至产品走向。这里我来分享一个案例。
在进行我们的k8s云平台的日志系统建设的时候,我们使用的是通用的EFK架构,在进行了一些业务梳理之后,我们的架构图是这样子的:
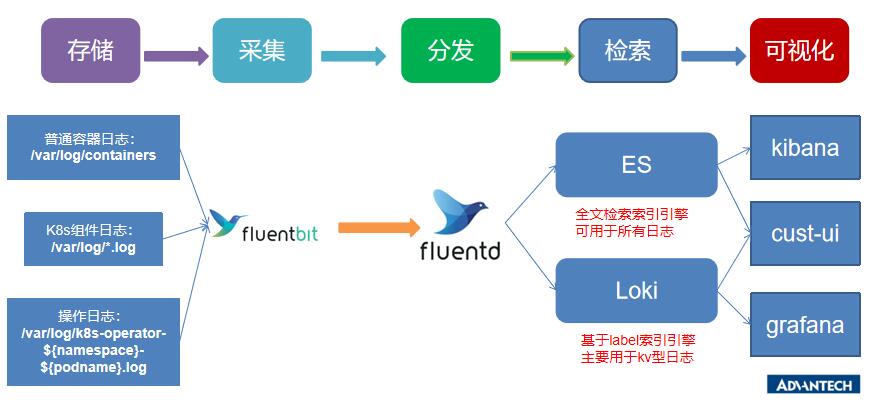
日志架构图
部署方式是这样子的:
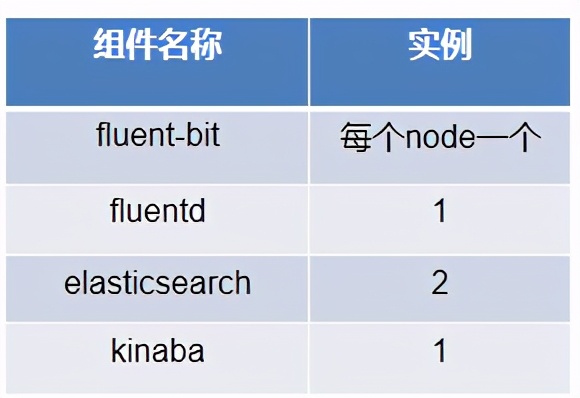
数据流走通之后,我们写了一些工具测试,测试思路是测试程序通过tcp向fluentd打数据包。主要是为了测试和优化fluentd和elasticsearh的性能。测试结果不太乐观,才1000 msg/s, 后来参考官方的文档对fluentd进行了优化之后,单实例性能达到3000 msg/s。对于这个性能我是比较满意了。
于是,我增加fluentd 的实例数为2,期待最终的性能能达到6000 msg/s。然而测试出来才达到5000 msg/s左右。
我继续增加fluentd的实例数为3,然而测试出来的数据依然保持在5000 msg/s左右。
奇怪了,fluentd所做的事情不过是接收tcp请求然后再通过http请求发送到elasticsearch,按理说,性能应该是按比例增长才对啊,为何性能在5000 msg/s 徘徊上不去呢?
一开始的猜想是fluentd遇到性能瓶颈了。我甚至为此改了架构:
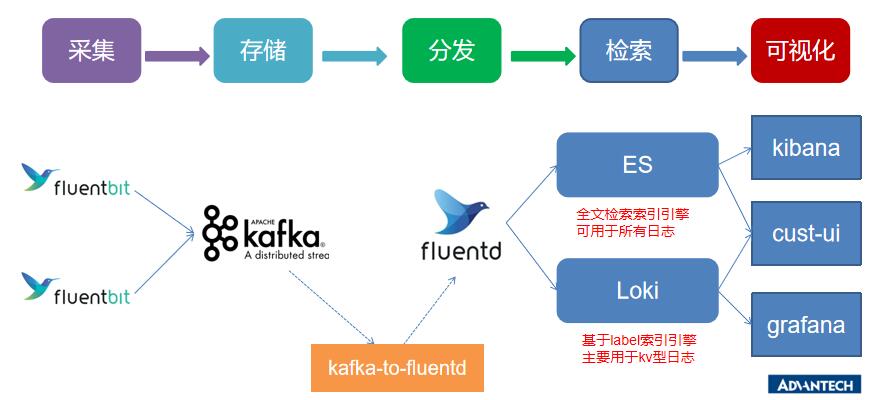
既然fluentd有性能瓶颈,那就先收到kafka,然后再发给fluentd,这样就可以做到削峰填谷的作用,保证fluentd平滑的处理数据。
然而,看到kafka,我突然萌生了这样的想法:真的是fluentd性能不佳吗?还是fluentd后面的elasticsearch有性能瓶颈、导致fluentd下的流量控制起作用了呢?
为了验证这个问题,我进行以下的测试:
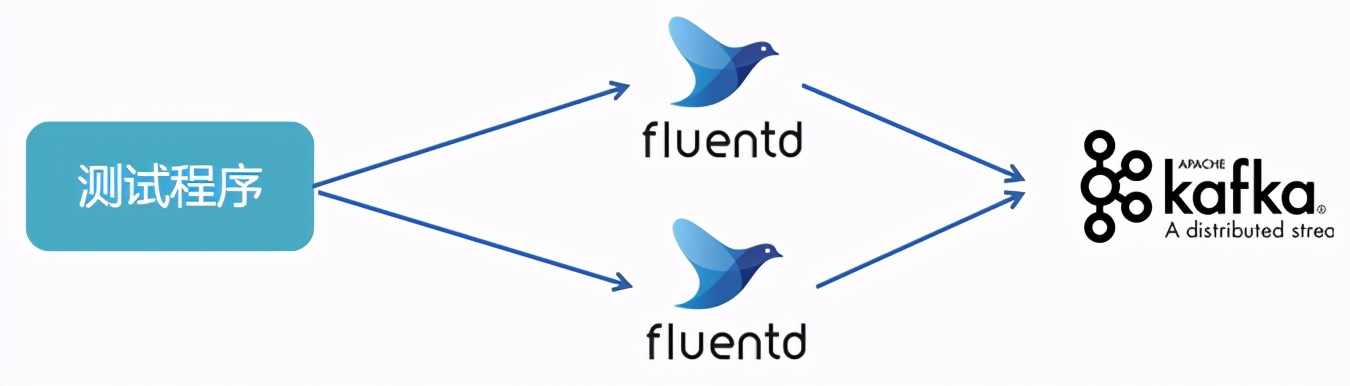
kafka的单实例性能在30000 msg/s左右,不会有性能瓶颈。测试发现,2个实例的fluentd可以测试到6000 msg/s。我大喜,增加到3个实例,结果到9000 msg/s。 增加到4个实例,结果到12000 msg/s。
这已经说明问题了:并非fluentd有性能瓶颈,而是fluentd下的某种流量控制机制起作用了!
但是fluentd是如何调控数据流量的呢?
这个时候我想到了tcp流量控制!
fluentd作为tcp的接收端,它会在接收到数据包之后通过http 发给elasticsearch。但是如果elasticsearch性能不佳导致这个http请求失败,那么fluentd的tcp recv就减速甚至停止了。这个时候tcp的流量控制就会起作用,测试程序作为tcp的发送端,会感知到这种变化,于是调整发送的速度(甚至停止),于是最终表现出来的结果就是测试程序测出来的性能变低了。
所以,我们的解决办法是优化fluentd后面的elasticsearch的性能,解决了这个性能瓶颈,就提高了fluentd的接收tcp数据包的处理速度,也就提高了测试程序发送tcp包的速度!
关于tcp的流量控制和窗口协议实现的细节,大家可以参考相关的文档。
针对tcp流量控制,我这里做一个通俗的解释:
我在给我1岁9个月的女儿喂饭的时候,我会观察她吃饭的速度:

如果她很快吃完,我就喂的快一点;
如果她半天不吃完,我就喂的慢一点;
一切全看她的消化能力!