informer cache中的数据是只读的, 任何修改都先deepcopy
informer cache中的数据是只读的, 任何修改都应该先deepcopy出来,然后提交apiserver, 利用apiserver informer event重新同步回cache中。 如果直接修改cache中的数据,就会出现数据不一致, 程序表现异常, 更严重的是, cache中底层实现是一个非线程安全的map, 如果多个groutine 并发读写map的现象, 程序直接fatal, 且不可recover。
更新资源需要RetryOnConflict
kubernetes 中的资源并发更新模型是乐观锁的机制, 每个资源都有一个单调递增的resourceVersion。 当客户端发送一个修改操作时,会携带resoruceVersion, apiserver收到请求进行修改之前会判断该version 是否小于最新的resourceVersion,如果小于就意味着这个资源已经被其他人修改,返回409 错误码,并提示需要冲突重试。 客户端收到该错误后需要进行重试, 目前kubernetes已经封装好对应的库, retry.RetryOnConflict。具体使用案例可以参见; Golang retry.RetryOnConflict函数代码示例
client-go 中访问apiserver 默认QPS 为5
kubernetes client-go 会默认进行客户端限流, 访问apiserver的默认并发为5。 对于一些并发比较大的服务来说,显然是不可接受的, 经常会出现一个服务上线时表现正常, 但是突然某一天出现超时,反应变慢。这时候就需要考虑是不是因为访问apiserver被限流了。
创建client时传递的 rest.Config可以进行配置客户端并发度。客户端限流底层实现是一个令牌桶, 通过两个参数来调节:
1)QPS: 表示每秒加入桶的token数量,用于控制并发
2)Burst:表示桶的大小,控制允许的激增请求量。
其中Burst需要设置的比QPS 大,Client-go不会校验该参数。 具体的数值根据服务负载和apiserver的负载进行权衡。
当发生客户端限流时,其实klog是会打印throttling字样,注意观察日志定位改问题。
Informer中cache 可以自定义索引
informer 底层是默认是根据namespace/name为key存储在map里的, 虽然Infomer中内嵌的Lister提供了List(selector labels.Selector) 方法, 但是该方法只是list所有元素之后再进行过滤, 如果元素较多会导致处理时间较长。
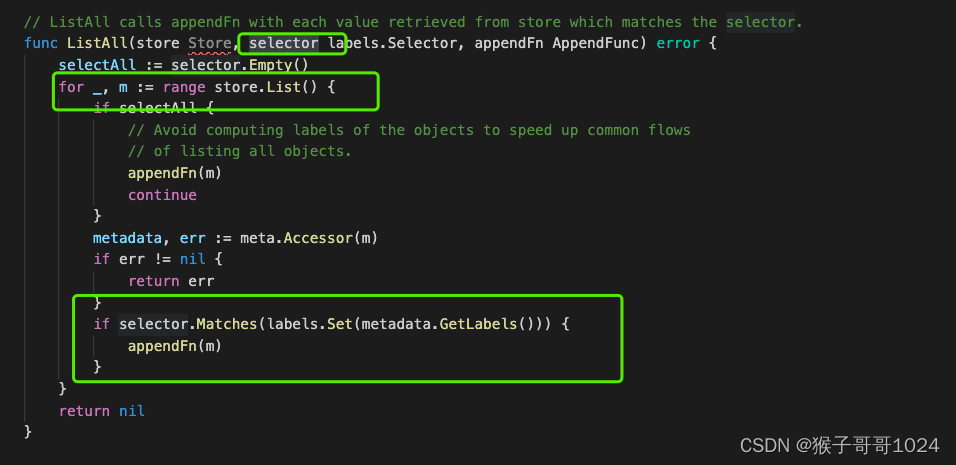
可以通过构建索引来优化访问速度:
- 添加索引: 需要传入一个生成索引key的函数
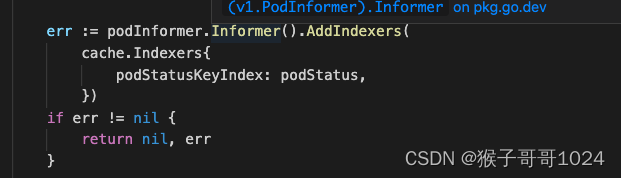
2)使用索引:
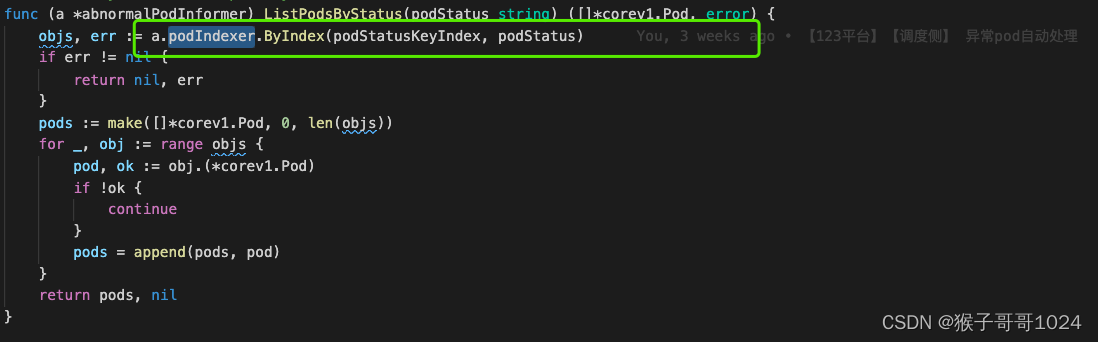
这样我们就可以根据某个label value构建索引,快速地从Informer cache中获取结果。
List 资源时指定resourceVersion=0将从apiserver cache中获取
当前我们集群里有大量的资源,如果有list请求, 可以显式指定metav1.ListOptions{ResourceVersion: 0} , 这样可以请求直接从apiserver的cache中返回, 不会穿透到etcd中。 不仅可以保护etcd,而且能够更快返回。k8s informer在启动的时候resourceVersion即为0。
Informer ResyncPeriod
我们在编写controller的时候,会注册informer event handler, 在产生event的时候进行一些reconcile操作,这是基于事件触发。 除了事件触发外,健壮的程序也需要基于时间的定期触发,定期全量reconcile, 防止丢失某些event, 或者其他错误,相当于一种定期补偿。
在创建informer的时候可以指定resyncPeriod, 该参数就是用于控制informer多久全量resync一次,resync时会将informer cache中的所有资源调用OnUpdateEventHandler, 不会请求apiserver。此时传递进来的参数 oldObjectResourceVersion==newObj.ResourceVersion, 使用者可以根据resourceVersion来判断是真正的update event还是由于resync触发的update event。
kubernetes 中controlle-manager中的cnotroller默认是: 12h~24h的一个随机数。
controller workqueue
在编写controller时, 一种约定俗称的规范是在Informer的event handler中将需要处理的resource 加入一个workqueue中, 而不是直接在event handler中处理,这样做的好处很多:
1)队列最重要的作用是防止同一个资源被多个groutine同时处理,防止冲突
2)队列提供了很多高级的功能, 例如 rate limit, delay retry等功能
3)队列具体削峰填谷的作用, 在变更较为频繁时, event较多, 利用队列可以将同一个资源的多次event 缓冲合并成一次reconcile。 而且可以创建多个消费者处理。
尽量使用shardInformer
每种资源类型都有独立的informer, 但是建议还是使用shardInformer, shardInformer的多个使用方底层复用一个informer, 可以节省很多资源,例如可以降低apiserver压力: 对apiserver的连接数, apiserver 资源序列化开销, 客户端的cache内存占用开销。
ContentType 设置为 PB
可以设置如下:
conf := &rest.Config{
Host: "https://9.134.163.198:6443",
QPS: 10000,
Burst: 100000,
ContentConfig: rest.ContentConfig{
ContentType: "application/vnd.kubernetes.protobuf",
},
}
这样可以极大的加快请求的耗时, 尤其是用Informer list 很多资源的时候, PB相对于json 更快的压缩速度, 和更大的压缩比。当前默认设置为json, 需要手动设置 contentType为 protobuf。 注意CRD 不能设置CotentType=PB , 因为CRD 没有实现对应protobuf marshal interface。创建的时候会报错如下: “object xxxx does not implement the protobuf marshaling interrace and cannot be encoded to a protobuf message"
ClientConfig设置Timeout
显式设置ClientConfig timeout,目前创建的k8s client 底层用的是http2协议, 会复用connection, 如果网络抖动, 会导致connection hang死, 需要等很久底层操作系统将链接重置之后应用层才能恢复,如果是http1协议的话, 因为每个请求都是发送一个新的出去, 如果网络问题会直接返回失败。 为了避免底层过长的超时时间,我们可以手动设置一个短一点的超时时间。
SharedInformer WaitForCacheSync 返回并不代表 eventHandler 执行完毕
我们使用informer的典型的一个顺序是 1).注册各种 eventHandler 2). 启动sharedInformer 3). 等待Informer 同步完成
往往我们认为 informer 同步完成对应的eventHander 也被调用成功, 但实际上并不是如此。ShardInformer 中的WaitForCacheSync 返回只是代表对应的事件已经分发下去了, eventHandler 是异步执行的, 并不保证执行时间。 sharedInfomer 往往会注册多个eventHandler , 如果是同步执行的话, 某个Handler 处理的特别慢的话会影响其他handler 的及时被调用, 所以每个handler 都是异步执行的。对于一些严重依赖handler 执行的逻辑需要特别小心, 例如我们维护了一个cache, 在每次有event 的时候更新这个cache, 当WaitForCacheSync 返回的时候我们不能直接开始执行业务逻辑,去读取这个cache, 很可能这个cache 还没有完全执行完毕。但是对于单个informer, WaitForCacheSync 执行完毕后,eventHandler 也执行完毕了。
并发更新 CRD 造成全量更新relist
高并发更新/增加很容易导致apiserver的watchCache的缓存被穿透,从而导致所有连接其上的informer 在rewatch时出现“too old resource version”,从而引发relist动作,加剧Apiserver的内存剧增。
Informer EventHandler 中Ondelete的时候 需要判断DeletedFinalStateUnknown
在Informer EventHandler 中OnDelete 被调用的时候, 需要判断 DeletedFinalStateUnknown 状态, 典型的使用场景如下:
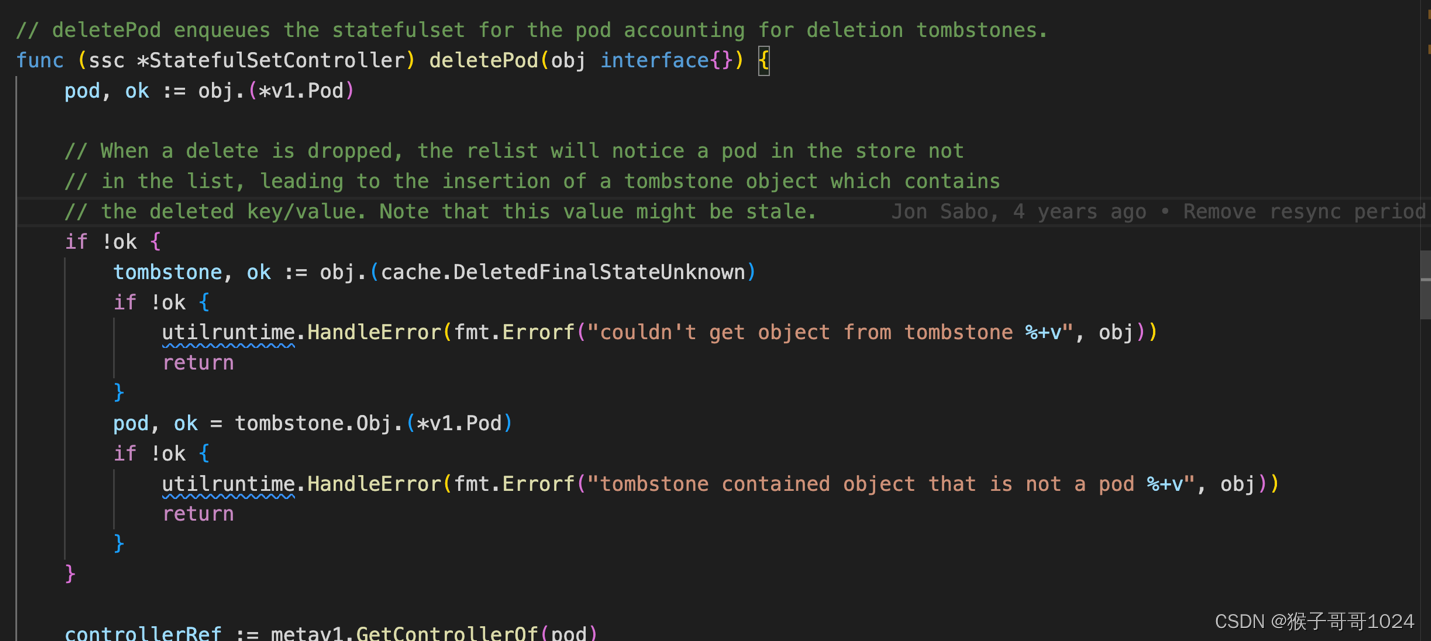
DeletedFinalStateUnknown 一般出现在由于网络中断等原因导致informer 本地cache 和apiserver 不一致, 等informer relist的时候发现informer cache中存在这个Object, 但是apiserver 没有, 就会触发一个DeletedFinalStateUnknown。 使用者需要显式的转换会原来的对象。