目录
没学过完整数据结构课就搞算法的坏处就是,很多稍微复杂一点的数据结构,自己暴力解出来都觉得特牛啤,结果一看,前人的天才们早就准备了一大堆时间复杂度低的优化算法,给你啪啪打脸QAQ终究是我见识浅薄了
Climb mountains not so the world can see you, but so you can see the world.
查找基本概念:
平均查找⻓度(ASL, Average Search Length)
所有查找过程中进⾏关键字的⽐较次数的平均值
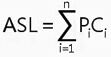
ASL是本章的重点,核心就在于这个公式
判定树
是一种二叉排序树,描述查找过程
成功结点n个,则失败结点n+1个
顺序查找的判定树类似单支树,折半查找的判定树是平衡二叉树
线性结构
顺序查找
从后往前找,0下标作为哨兵

平均查找长度

有序顺序查找
对关键字有序线性表进行顺序査找,查找失败时不一定要遍历整个线性表
Cj为失败结点层数-1即lj-1
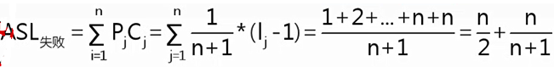
折半查找
仅仅适用有序的顺序表
分别记录首尾中
mid直接除默认向下取整

判定树为满二叉树时


折半查找的时间复杂度为O(log(2) n),因为是平衡二叉树高度
分块查找
“索引表”中保存每个分块的最⼤关键字和第一个元素地址
如何查找:
1.在索引表中确定待査记录所在的块,可以顺序査找或折半査找索引表
2.在块内进行顺序查査找
若块内和块间均采用顺序查找。
b=n/s,代入
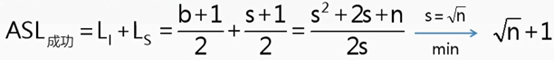
若块内采用顺序查找,块间采用折半查找
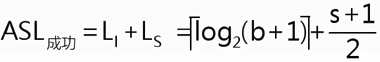
题目
1.(2010真题)已知一个长度为16的顺序表L,有序排列,若采用折半查找法查找一个L中不存在的元素则关键字的比较次数最多是()5
法一:折半查找不成功时比较次数最多为树的高度log(2) (n+1)
n=16,故比较次数最多为log(2) (16+1)=5
法二:也可模拟折半过程
第一次mid=(1+16)/2=8(查找树的根结点)
第二次mid=[(8+1)+16]/2=12
第三次mid=[(12+1)+16]/2=14
第四次mid=[(14+1)+16]/2=15
第五次mid=[(15+1)+16]/2=16,发现失败,查找结束
2. (2017真题)下列二叉树中,可能成为折半查找判定树(不含外部结点)的是A
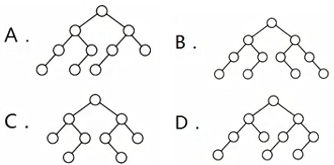
折半查找判定树实际上是一棵二叉排序树,它的中序序列是一个有序序列。可以在树结点上依次填上相应的元素,符合折半查找规则的树即是所求
只有左子结点,则为向上取整;只有右子结点,则为向下取整

3. 类比二分査找算法,设计k分查找算法(k为大于2的整数)如下:首先检查n/k处(n为查找表的长度)的元素是否等于要搜索的值,然后检査2n/k处的元素….这样,或者找到要査找的元素,或者把集合缩小到原来的1/k,如果未找到要査找的元素,则继续在得到的集合上进行k分査找;如此进行,直到找到要査找的元素或查找失败。试求,查找成功和查找失败的时间复杂度。
与二分查找类似,k分查找法可用k叉树来描述
k分查找法在查找成功时进行比较的关键字个数最多不超过树的深度,而具有n个结点的k叉树的深度为⌊log(k)n⌋+1,所以k分查找法在查找成功时和给定值进行比较的关键字个数至多为⌊log(k)n⌋+1,即时间复杂度为O(log(k)n)
同理,查找不成功时,和给定值进行比较的关键字个数也至多为⌊log(k)n⌋+1,故时间复杂度也为O(log(k)n)
4. 已知一个有序顺序表A[0…8N-1]的表长为8N,并且表中没有关键字相同的数据元素。假设按如下方法查找一个关键字值等于给定值X的数据元素:先在A[7],A[15],A[23],…,A[8K-1],…,A[8N-1]中进行顺序查找,若査找成功,则算法报告成功位置并返回;若不成功,当A[8K-1]<Ⅹ<A[8×(k+1)-1]时,则可确定一个缩小的査找范围A[8K]~A[8×(K+1)-2],然后可以在这个范围内执行折半査找。特殊情况:若X>A[8N-1]的关键字,则查找失败。
1)画出描述上述查找过程的判定树。
2)计算相等査找概率下查找成功的平均查找长度。
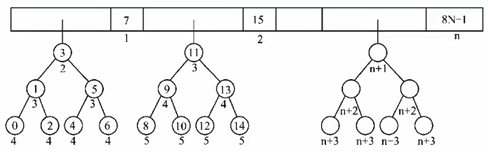

等査找概率下,平均每个关键字的查找成功的概率为1/8n;
0~7之间的关键字,顺序比较1次后,进行折半查找2+3*2+4*4;
8~15之间的关键字,是先顺序比较2次后,再进入折半查找;
依次类推,8(N1)~8N-1之间的关键字,是先顺序比较了n次,再进入折半查找。
5. 写出折半查找的递归算法。初始调用时,low为1,high为 ST.length。

6. 线性表中各结点的检索概率不等,则可用如下策略提高顺序检索的效率:若找到指定的结点,将结点和其前驱结点(若存在)交换,使得经常被检索的结点尽量位于表的前端。试设计在顺序结构和链式结构的线性表上实现上述策略的顺序检索算法。
即找到之后顺便前挪

树形结构
B树
你的心里有B树吗
m阶的B树性质:
1)树中每个结点至多有m棵子树(即至多含有m-1个关键字)
2)若根结点不是叶子结点,则至少有两棵子树(即至少1个关键字)
3)非根非叶结点至少有⌈m/2⌉棵子树(即⌈m/2⌉-1个关键字)
4)非叶节点的数据结构
存放一个数组,先存放n:关键字个数(⌈m/2⌉-1<=n<=m-1)
Pi为指向第i个子树的指针;K为关键字
第i前的子树关键字小于Ki, 第i及之后的子树关键字大于Ki(类似二叉排序树)
![]()
5)叶结点同层,无携带信息(查找失败结点)
注意与m叉树区别:
1.构造m阶B树至多m叉,没有任何一个结点有m叉也可。只需满足非根非叶结点至少有⌈m/2⌉子树
2.判断B树的阶,要考虑最底层的关键字个数,产生虚叶子结点
例子:

1)3阶B树最多3棵子树,2个关键字
2)根结点非叶子,有3子>2
3)除根节点外的分支结点有至少2子树,1个关键字
4)为排序树
5)叶结点同4层,无携带信息
高度范围:
n个关键字,阶数为m,高度为h的B树
高度最小时,每个结点的关键字最多m-1,满m叉树结点个数累加
![]()
高度最大,
根结点-至少1个关键字、2子树
第二层-关键字至少⌈m/2⌉-1、⌈m/2⌉棵子树
第三层- 2*⌈m/2⌉个结点
叶子层-2*⌈m/2⌉^(h-1)个结点
对应n个关键字,n+1个失败叶结点

![]()
操作
查找
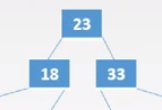
18<32<33所以在中间的子树

在B树中找结点是在磁盘,在结点中查找是在内存
插入
1)定位
查找插入该关键字的位置,即最底层中的某个非叶子结点(规定一定是插入在最底层的某个非叶子结点内)
2)插入
若插入后,不破会m阶二叉树的定义,即插入后结点关键字个数在属于区间[⌈m/2⌉-1,m-1],则直接插入

若插入后,关键字数量大于m-1,则对插入后的结点进行分裂操作;
1.插入后的结点中间位置(⌈m/2⌉)关键字并入父结点中,
2.中间结点左侧结点留在原先的结点中,右侧结点放入新的节点中,
3.若并入父节点后,父结点关键字数量超出范围,继续向上分裂,直到符合要求为止
根结点分裂会导致h++

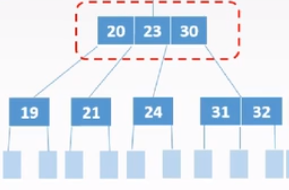

删除叶子结点
1)直接删除
若被删除关键字所在结点关键字个数>⌈m/2⌉-1,表明删除后仍满足B树定义

2)兄弟够借
若被删除关键字所在结点关键字总数=⌈m/2⌉-1,
且与此结点邻近的兄弟结点的关键字个数≥⌈m/2⌉, 则需要从兄弟结点借个关键字(左右兄弟均可)

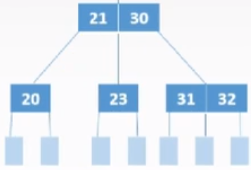
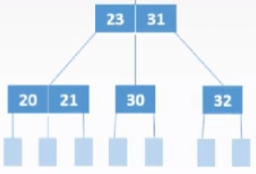
3)兄弟不够借
若被删除关键字所在结点关键字总数=⌈m/2⌉-1,且与此结点邻近的兄弟结点的关键字个数=⌈m/2⌉-1,
则删除关键字,并与一个不够借的兄弟结点和双亲结点中两兄弟子树中间的关键字合并。
合并后若双亲结点因减少一个结点导致不符合定义,则继续执行2、3步骤。


删除分支结点
1)若小于k的子树中关键字个数>⌈m/2⌉-1
则找出k的前驱值k′,并用k′来取代k,再递归地删除k'即可。(排序树的前驱是比其小的相邻关键字)


2)若大于k的子树中关键字个数>⌈m/2⌉-1
则找出k的后继值k′,并用k′来取代k,再递归地删除k′即可。


3)若前后两子树关键字个数均为⌈m/2⌉-1
则直接两个子结点合并,然后删除k即可。

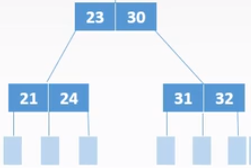
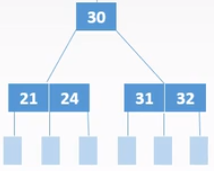
B+树
一棵m阶B+树满足如下特性
1)每个分支结点最多有m棵子树
2)若根结点不是终端结点,则至少有两棵子树
3)除根结点外的所有非叶结点至少有⌈m/2⌉棵子树,子树和关键字个数相等
4)所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻结点按大小顺序连接起来
5)所有分支结点(可视为索引的索引)中仅包含他的各个子结点(下一级索引块)中关键字的最大值及指向其子结点的指针(类似分块查找)
例子

3)除根节点,所有分支结点至少2子树,子树与关键字个数等
4)叶结点包含有序排列的全部关键字与指向记录的指针,相邻结点链接
5)分支结点(索引)包含其各子结点指针及子结点中最大值
与B树区别
1)在B+树中,具有n个关键字的结点值含有n棵子树,即每个关键字对应1棵子树
在B树中,具有n个关键字的结点含有n+1棵子树
2)在B+树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的毎个索引项只含有对应子树的最大关键字和指向该子树关键字的指针,不含有该关键字对应记录的存储地址
3)在B+树中,叶结点包含全部关键字,即在非叶结点中出现的关键字也会出现在叶结点中
在B树中,叶结点包含的关键字和其他结点包含的关键字是不重复的
4)B+查找方式,可以从第一个叶结点顺序查找,叶可以从根结点多路查找
在B+树中查找时,无论查找成功还是失败一定是查找到叶结点当中的值为止
题目
1. (2013真题)在一棵高度为2的5阶B树中,所含关键字的个数最少是()。5
性质:
1)若根结点不是终端结点,则至少有两棵子树
2)除根结点外的所有非叶结点至少有⌈m/2⌉棵子树(即至少含有⌈m/2⌉-1个关键字)
m=5时,非根结点含有关键字个数至少为⌈5/2⌉-1=2
根结点里至少1个关键字
m阶树中每个结点至多含有m-1个关键字。
当仅有一层(一个根结点)时,关键字个数达到5时会分裂成两层
2.(2014真题)在1棵具有15个关键字的4阶B树中,含关键字的结点个数最多是()
A.5B.6C.10D.15
关键字数量不变,要求结点数量最多,那么即每个结点中含关键字的数量最少。
1)若根结点不是终端结点,则至少有两棵子树(至少1个关键字)
2)除根结点外的所有非叶结点至少有⌈m/2⌉棵子树(即至少含有⌈m/2⌉-1个关键字)
代入m=4,根结点最少含1个关键字,非根结点中最少含⌈4/2⌉-1=1个关键字,所以每个结点中,关键字数量最少都为1个。
15个关键字分布在15个结点中,形态上恰好为一棵4层满二叉树。
3.(2017真题)下列应用中,适合使用B+树的是()B
A.编译器中的词法分析
B.关系数据库系统中的索引
C.网络中的路由表快速查找
D.操作系统的磁盘空闲块管理
B+树是由文件系统所需而产生的B树的变形,前者比后者更加适用于实际应用中的操作系统的文件索引和数据索引,因为前者磁盘读写代价更低,查询效率更加稳定
| 应用 |
适合使用 |
| 编译器中的词法分析 |
有穷自动机和语法树 |
| 网络中的路由表快速查找 |
高速缓存、路由表压缩技术和快速查找算法 |
| 磁盘空闲块管理 |
空闲空间链表 |
| 文件索引和数据索引 |
B+树 |
4. 对如图所示的3阶B树,依次执行下列操作,画出各步操作的结果
1)插入90
2)插入25
3)插入45
4)删除60
5)删除80

若插入后结点中的元素个数不超过「3/2|=2,不会引起结点的分裂
1)2)3)4)
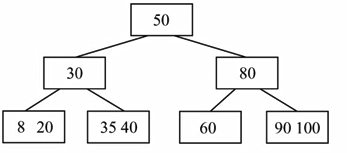

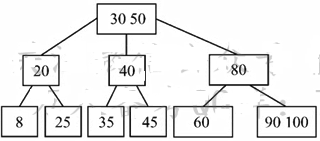

5)删除80:删除80后,导致80所在结点的父结点与其右兄弟结点合并,
这时父结点(孩子)元素个数为0,再次对父结点进行调整。
将50与40合并成一个新的结点,则90、100所在结点为这个结点的子结点.

散列表
构造
散列函数(哈希函数):Addr=H(key)
要求:
1)散列函数的定义域必须包含全部需要存储的关键字,而值域的范围则依赖于散列表的大小或地址范围。
2)散列函数计算出来的地址应该能等概率、均匀分布在整个地址空间中,从而减少冲突的发生。
3)散列函数应尽量简单,能够在较短时间内计算出任一关键字对应的散列地址。
直接定址法
H(key) = key 或 H(key) = a*key + b
这种⽅法不会产⽣冲突。适合关键字的分布基本连续的情况,若关键字分布不连续,则会造成存储空间的浪费。
除留余数法
H(key) = key % p
表⻓为m,取⼀个不⼤于m但最接近或等于m的质数p(减少冲突)
数字分析法
数码分布较为均匀的若⼲位作为散列地址,适合于已知的关键字集合

平⽅取中法
取关键字的平⽅值的中间⼏位作为散列地址。
这种⽅法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布⽐较均匀,适⽤于关键字的每位取值都不够均匀或均⼩于散列地址所需的位数。
如:521^2=271441,取14
折叠法
将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址
如:5211252取521+125+2=648
适合位数过多的
处理冲突
开放定址法
可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放
删除时不能物理删除,只能设置标记逻辑删除(否则查找时会断)
![]()
其中,增量序列di的计算方法:
线性探查法(重点)
di=i
缺点:堆积现象降低查找效率

(好可爱的表情包,给宝贝们也看一下)
平方探测法
一前一后![]()
再散列法
![]() 准备多个哈希函数,冲突了就用下一个
准备多个哈希函数,冲突了就用下一个
伪随机序列法
随机数
拉链法
把所有“同义词”存储在⼀个链表中,散列表中每个单元存放该链表头指针
适合经常插入删除的情况

查找效率
影响因素:散列函数、处理冲突的方法和填装因子
填装因子α=记录数n/表长m
ASL不单独依赖于n
计算ASL注意有两种方法(需要根据真题判断):
1. 对⽐关键字的次数称为查找⻓度
2. 把“空指针”的判定算作⼀次⽐较
题目
1.(2014真题) 用哈希(散列)方法处理冲突(碰撞)时可能出现堆积(聚集)现象,下列选项中,会受积堆积现象直接影响的是(D
A.存储效率
B.散列函数
C.装填(装载因子
D.平均查找长度
存储效率指的是找到地址后放入元素的过程
2.有11个关键字,装填因子α=0.75,H(key)=key%P,求哈希函数
m=⌈11/0.75⌉=15
P为不超过m的最大素数=13
串
逻辑结构(定义)
特殊的线性表
串,即字符串(String)是由零个或多个字符组成的有限序列。一般记为S=’a1…an’
其中,S是串名,单引号括起来的字符序列是串的值
子串:连续
字符在主串中位置与线性表的位序类似,要从1开始数
存储结构(物理结构)
顺序存储
定长静态数组

动态数组(堆分配要手动free)

链式存储

字符1B,指针4B(就离谱)增加存储密度

运算(操作)
串的基本操作通常以子串为操作对象
假设有串T=“”,S="iPhone11 Pro max?”,W=“Pro”
StrAssign(&T, Chars):赋值操作。把串T赋值为chars。
StrCopy(&T,S):复制操作。由串S复制得到串T。
Strempty(S):判空操作。若S为空串,则返回TRUE,否则返回 FALSE。
StrEngth(S):求串长。返回串S的元素个数。
ClearString(&S):清空操作。将S清为空串。
DestroyString(&S):销毁串。将串S销毁(回收存储空间)
Concat(&T,S1,S2):串联接。用T返回由S1和S2联接而成的新串
SubString(&sub,s,pos,len)}:求子串。用Sub返回串S的第pos个字符起长度为len的子串
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置:否则函数值为0。
StrCompare(S,T):比较操作。若S>T,则返回值>0.若S=T,则返回值=0.若S<t,则返回值<0。
Eg:执行基本操作concat(&T,s,w)后,T=" Phone11 Pro max?pro”(可能会有存储空间扩展)
执行基本操作 SubString(&T,S,4,6)后,T=“one11”
执行基本操作Index(S,W)后,返回值为11



朴素模式匹配
模式匹配就是子串的定位
朴素模式匹配-不通过取子串操作,直接访问数组元素,主串元素依次作为起始位置
当主串的工作指针在比较过程中超出边界时停止

或不设锚定的起始指针,而是通过回退计算i

最坏比较次数(n-m+1)*m,时间复杂度O(n*m)
KMP
发明这个阴间算法的3大佬叫KMP
注意next数组是主串自己和自己匹配,对自己记忆,类似人脑在失配时不会回溯到头,而是从前缀与已匹配部分相同的地方开始看

手算next数组:
J=6时失配,向右滑动到j=3



当第j个字符匹配失败,由前1~j-1个字符组成的串记为S,则:
next[j]=S的最长相等前后缀长度+1

时间复杂度:O(n+m)
nextvel
对next数组的优化
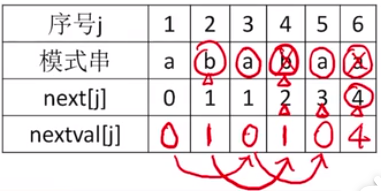
令k=next[j]若T[j]==T[k] (连接两字母比较)将next[k]赋值给nextval[j],
两字母不同则不变

题目
1.串ababaaababaa的next数组值为()。
A.01234567899
B.012121111212
C.011234223456
D.0123012322345
手动求解next数组的方法:求出部分匹配值数组,右移一位(最左补“-1”),整体+1
前缀:除最后一个字符以外,字符串的所有头部子串
后缀:除第一个字符以外,字符串的所有尾部子串
部分匹配值:字符串的前缀和后缀的最长相等前后缀长度。
a的前后缀都为空集,最长相等前后缀长度为0
ab的前缀为{a},后缀为{b},{a}∩{b}=Ø,最长相等前后缀长度为0
aba的前缀为{a,ab},后缀为{a,ba},{a,ab}∩{a,ba}={a},最长相等前后缀长度为1
bab的前缀{a,ab,aba}∩后缀{b,ab,bab}={ab},最长相等前后缀长度为2
ababa的前缀{a,ab,aba,abab}∩后缀{a,ba,aba,baba}={a,aba},公共元素有两个,最长相等前后缀长度为3
以上得到 ababa的部分匹配值数组00123
整体右移一位得到-10012,整体+1得到01123
2.注意有些题的next数组值开头多了一个-1,多考虑了next[0]=-1,其他的一样