基本概念
对当前学习任务有用的特征称为“相关特征”(relevant feature);没有用的特征称为“无关特征”(irrelevant feature)。从给定的特征集合中选择出相关特征子集的过程,称为“特征选择”(feature selection)…常用的特征选择方法大致可以分为:过滤式(filter)、包裹式(wrapper)和嵌入式(embedding)。
过滤式选择
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。这相当于先用特征选择对初始特征进行“过滤”,再用过滤后的特征来训练模型。Relief(Relevant Features)[Kira and Rendell, 1992]是一种著名的过滤式特征选择方法,该方法设计了一个“相关统计量”来度量特征的重要性。
包裹式选择
与过滤式特征选择不考虑后续学习器不同,包裹式特征选择直接把最终要使用的学习器的性能作为特征子集的评价准则。一般而言,由于包裹式特征选择方法直接针对给定学习器进行优化,因此从最终学习器性能来看,包裹式特征选择比过滤式更好,但另一方面,由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择大得多。
嵌入式选择
在过滤式与包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别;与此不同,嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,二者在同一优化过程中完成,即在学习器训练过程中自动进行特征选择。我们考虑最简单的线性回归模型,以平方误差为损失函数。损失函数引入L1范数正则化。如下图所示
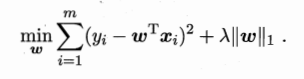
采用L1范数比L2范数更易于得到稀疏解,w取得稀疏解意味着初始的d个特征中仅有对应着w的非零分类的特征才会出现在最终模型中。
示例演示
下面例子是基于L1地嵌入式特征选择。
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
print(X.shape)
#(150, 4)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
print(X_new.shape)
#(150, 3)