目录
探索性数据分析EDA(Exploratory Data Analysis)
如果变量本身不是极端值,而它与其它变量或多个变量组合后出现不正常值,如何检测?
2.将数据集划分为训练集和测试集 train_test_split()
探索性数据分析EDA(Exploratory Data Analysis)
EDA的主要工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
基本步骤:
1.检查数据:查看是否有缺失值,异常值,重复值等问题
数据类型分为数值型,类别型,文本型,时间序列等。
主要考虑数值型(定量数据)和类别型(定性数据);
数值型又可以分为连续型和离散型。
2.数据描述:.describe()函数:
生成描述性统计数据
总结数据分布的集中趋势、分散和形状,
不包括 NaN值。

3.特征相关性:crosstab()共生矩阵/交叉表,用于统计分组频率的特殊透视表



4.特征分布

EDA总结
必要时对列名重命名
行列数data.shape,数据类型data.dtypes
data.info()同时查看这两项
data.describe()查看连续变量的描述统计量
各列分别有多少缺失值data.apply(lambda x: sum(x.isnull()),axis=0)
各行分别有多少缺失值data.apply(lambda x: sum(x.isnull()),axis=1)
总共有多少行有缺失值
len(data.apply(lambda x: sum(x.isnull()),axis=1).nonzero()[0])
删除重复值data.drop_duplicates()
-检验数据分布
创建新的特征
当特征和目标变量并不是很相关时,可以修改输入的数据集,应用线性、非线性变换(或者其他相似方法)来提高系统的精度。数据是“死”的,人的思维是“活”的。数据科学家负责改变数据集和输入数据,使数据更好地符合分类模型。
基本方法:
-B. 特征的非线性修正
1.特征的线性修正
1)回归问题
从Sklearn工具包中加载数据——Python命令直接加载

2-1)计算均方误差
from sklearn.metrics import mean_squared_error
mean_squared_error(测试标签集,预测标签集)
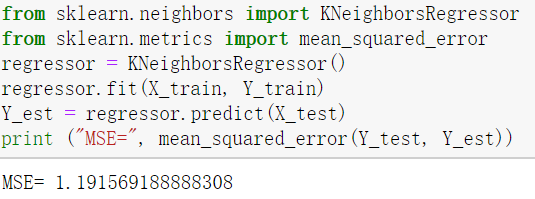
注意:不要混淆MSE和MAE
RMSE(Root Mean Square Error):均方根误差,衡量观测值与真实值之间的偏差,常用来作为机器学习模型预测结果衡量的标准。
MSE(Mean square Error):均方误差,真实值与预测值(估计值)差平方的期望。值越大,表明预测结果越差。
MAE(Mean Absolute Error):平均绝对误差,是所有单个观测值与算数平均值的偏差的绝对值的平均,可以更好的反应预测值误差的实际情况
2-2)计算均方误差:Z-scores标准化
(Z-scores标准化是将特征映射为均值为0、标准差为1的新特征)

注意:Z-scores标准化属于线性变换
Z-Score通过(x-)/
将两组或多组数据转化为无单位的Z-Score分值(目的就是将不同量级的数据统一转化为同一个量级),使得数据标准统一化,提高了数据可比性,消弱了数据解释性。
1)总体数据的均值()
2)总体数据的标准差()
3)个体的观测值(x)
Z-Score本身没有实际意义,它的现实意义需要在比较中得以实现。
估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代。其次,Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的。最后,Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值。
2-3)计算均方误差:鲁棒性缩放
(鲁棒缩放采用中位数和IQR对每个特征进行单独缩放)

注意:鲁棒性缩放属于线性变换
鲁棒性:鲁棒是Robust(adj.强健的,健康的)的音译,它是在异常和危险情况下系统生存的关键,例如:计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机,不崩溃,就是该软件的鲁棒性。即控制系统在一定的参数变动下,维护其他某些性能的特性
鲁棒性缩放(RobustScaler):采用中位数和IQR(四分位距)对每个特征进行单独缩放。
由于数据读入缺失、传输错误或传感器损坏等原因,如果有一个或一些点原理中心,这些异常数据对均值和方差影响较大,但对中位数和四分位数影响不大,因此鲁棒缩放对于异常值更鲁棒
2.特征的非线性修正
创建新特征
例如:假定输出结果与房屋居住人数大致相关:
但我们可以将房屋占用率的平方根作为新特征
注意:numpy.sqrt()属于非线性变换
维数约简
当数据集中包含大量特征时:
只保留有意义的特征不仅可以使数据集易于管理,而且可以使预测结果不受数据中噪声的影响,预测精度更好。
维数约减
消除输入数据集的某些特征,创建一个有限特征的数据集(包含所有需要的信息),以更有效的方式预测目标变量。
注:多数维数约简算法的一个主要假设:
数据包含加性高斯白噪声。
维数约简可以减少噪声的集合跨度,以此减少噪声的能量。
噪声数据:是指数据中存在着错误或异常(偏离异常值)的数据,这些数据对数据分析造成了干扰。即无意义数据,现阶段的意义已经扩展到包含所有难以被机器正确理解和翻译的数据,如非结构化文本。任何不可被源程序读取和运用的数据,不管是已经接受、存贮的还是改变的,都成为噪声。
加性高斯白噪声(AWGN:Additive White Gaussian Noise)是最基本的噪声和干扰模型
加性噪声:叠加在信号上的一种噪声,,通常记为n(t),而且无论有无信号,噪声n(t)都是始终存在的。因此通常称它为加性噪声或者加性干扰。
白噪声:噪声的功率谱密度在所有得频率上均为一个常数,则称这样的噪声为白噪声,如果白噪声取值的概率分布服从高斯分布,则称这样的噪声为高斯白噪声。
当波的功率频谱密度乘以一个适当的系数后将得到每单位频率波携带的功率,这被称为信号的功率谱密度。
1.协方差矩阵
协方差是对两个随机变量联合分布线性相关程度的一种度量。
随机变量X、Y的协方差:
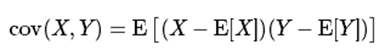
cov(X, Y) = cov(Y, X)
随机变量X与自身的协方差就是X的方差:
![]()
![]()
1-1)两个随机变量越线性相关,协方差越大
1-2)线性无关,协方差为0
2.相关系数:
相关系数(Correlation coefficient) 是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度。
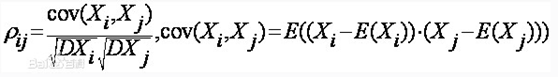
2-1)相关系数取值在-1~1之间
2-2)相关系数为0时,称两个变量不相关
2-3)相关系数为1,两个变量完全相关,即具有线性关系
2-4)越接近0,变量相似度越小
2-5)越接近1,变量相似度越大
2-6)相关系数>0.8,高度相关;相关系数<0.3,低度相关,其他中度相关
例子:
X=[1.1, 1.9, 3]
Y=[5.0, 10.4, 14.6]
X,Y的协方差计算:
E(X) = (1.1+1.9+3)/3 =2
E(Y) = (5.0+10.4+14.6)/3 =10
E(XY)=(1.1×5.0+1.9×10.4+3×14.6)/3 = 23.02
Cov(X,Y)=E(XY)-E(X)E(Y) = 23.02-2×10 =3.02
X,Y的相关系数:
D(X)=E(X^2)-E^2(X)=(1.1^2+1.9^2+3^2)/3 – 4 = 0.6
σx=sqrt(D(X)) =0.77
D(Y)=E(Y^2)-E^2(Y)=(5^2+10.4^2+14.6^2)/3-100 = 15.44
σy=sqrt(D(Y)) =3.93
r(X,Y)=Cov(X,Y)/(σxσy)=3.02/(0.77×3.93) = 0.9979
注意:不要混淆协防差矩阵cov()和相关系数矩阵corrcoef()

相关矩阵也叫相关系数矩阵,其是由矩阵各列间的相关系数构成的。也就是说,相关矩阵第i行第j列的元素是原矩阵第i列和第j列的相关系数。
两个矩阵都是对称矩阵。
3.矩阵图形化:热力图heatmap()
import seaborn as sns
Import matplotlib.pyplot as plt
sns.heatmap(协方差矩阵,annot=True)
注意:参数annot默认False,True指的是热力图对应方格写入数据
相关特征可能包含相似属性,因而可以约减高度相关特征。
维数约减算法有很多,如PCA、LFA、LDA、LSA、ICA、T-SNE等。
4.主成分分析PCA
主成分分析 (Principal(主要的) Component(组成部分) Analysis, PCA),又称主元分析、主分量分析,旨在利用降维的思想简化数据。
PCA的主要思想是通过对原始变量相关矩阵内部结构的关系研究,找出影响效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。
将m维特征映射到p维上,这p维是新的正交特征,被称为主成分。
p维特征是在原有m维特征的基础上重新构造出来的,不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质。
4-1)算法步骤:
·对所有的样本进行中心化,标准化,归一化,白化等
·计算样本的协方差矩阵
·对矩阵X特征值分解
·取出最大n个特征值对应的特征向量,标准化后组成特征向量矩阵W
·对样本转化
·得到输出样本
4-2)PCA常用参数(PCA(n_components=None, copy=True, whiten=False))
·n_components=None 保留主成分个数,赋值为字符串自动选取。
类型:int 或者 string,缺省时默认为None,所有成分被保留。
赋值为int,如n_components=1,将把原始数据降到一个维度;
赋值为string,如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
·copy=True 是否复制原始训练数据
若为True,则在原始数据的副本上进行运算后,原始训练数据的值不会有任何改变,缺省时默认为True;
若为False,则运行PCA算法后,原始训练数据的值改变。
·whiten=False 白化,每个特征具有相同方差
·svd_solver=’full’ 指定奇异值分解SVD的方法,有4个可选值:{‘auto’, ‘full’, ‘arpack’, ‘randomized’}
SVD(奇异值分解):通过SVD对数据的处理,我们可以使用小得多的数据集来表示原始数据集,这实际上是去除了噪声和冗余信息,以此到达了优化数据,提高结果的目的。
| 优点:简化数据,去除噪声,提高算法的结果 |
| 缺点:数据的转换可能难以理解 |
| 适用于数据类型:数值型 |
Randomized PCA
Scikit-Learn提供了一种基于随机SVD(Randomized SVD)的更快的算法,它是一种更轻的、近似迭代分解的方法。
做矩阵分解时,随机SVD比经典SVD算法速度更快,只需要几个步骤就能与经典算法结果极其近似。因此,当训练数据集很大时,它是一个很好的选择。
当数据集的规模非常小时, Randomized PCA输出结果与经典PCA相当接近,但当这两种算法应用于大数据集时,其对比结果会显著不同。
4-3)举例
from sklearn.decomposition import PCA
pca=PCA(n_components=2)
pca.fit_transform(训练数据集)
5.潜在因素分析LFA
一科成绩好的学生,往往其他各科成绩也比较好
→学生的各科成绩之间存在着一定的相关
→是否存在某些潜在的共性因子影响着学生的学习成绩?
用潜在变量解释观察变量的数学模型称为潜变量模型。
PCA中每个主成分不具有特定的含义,为此提出了因子分析,通过寻找潜在因子获得观测变量的潜在结构,即潜变量分析 (Latent Factor(潜在因素) Analysis, LFA)。LFA主要目的是用来描述隐藏在测量变量中的一些更基本,但又无法直接测量到的隐性变量。
LFA不需要对输入信号进行正交分解,其算法假设是:数据中的观测变量是潜变量经过线性变换后的值,并且具有可分离的噪声(AWG任意波形发生器生成的噪声)。


6.线性判别分析LDA
线性判别分析(Linear(线性的) Discriminant(判别式) Analysis,LDA)是一种经典的线性学习方法,试图找到两类物体/事件特征的一个线性组合,以能够特征化或区分它们。LDA是线性分类器,也可以为分类做降维处理。
1.算法思想:
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。





2.LDA与PCA区别

- PCA(主成分分析)寻找数据集中方差最大的方向作为主成分分量的轴,为了方差最大化→ 投影到左边
- LDA(线性判别分析)投影后类内方差最小,类间方差最大→ 投影到下面
相同点:(1)均可以对数据进行降维;
(2)均使用了矩阵特征分解的思想;
(3)均假设数据符合高斯分布。
不同点: (1) LDA是有监督降维,PCA是无监督降维;
(2) LDA降维最多降到类别数k-1的维度,PCA没有该限制;
(3) LDA可用于降维,还可用于分类;
(4)LDA选择分类性能最好的投影方向,
PCA选择样本点投影具有最大方差的方向。
3.LDA优点与缺点


优点:
(1)LDA可以使用类别先验知识,无监督学习无法使用类别先验知识。
(2)样本分类信息依赖均值而不是方差时,LDA比PCA算法较优。
缺点:
(1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题;
(2)若降维维度大于k-1,不能使用LDA(有一些LDA的进化版可以绕过这个问题);
(3)LDA在样本分类信息依赖方差而不是均值时,降维效果不好;
(4)LDA可能过度拟合数据。
7.潜在语义分析LSA
潜在语义分析(Latent Semantical Analysis,LSA)是一种信息检索模型,使用统计方法对大量文本集进行分析,提取词与词之间潜在的语义结构,并用提取的潜在语义结构表示词和文本,消除词之间的相关性和简化文本向量,实现降维的目的,通常应用于经过TfidfVectorizer或CountVectorizer处理的文本分析中。
1.基本思想:
把高维向量空间模型表示中的文档映射到低维的潜在语义空间中,这个映射是通过对项/文档矩阵(输入数据集通常是一个稀疏矩阵)的奇异值分解来实现,产生具有相同概念词语的语义集合。
2.CountVectorize
只考虑词汇在文本中出现的频率
3.TfidfVectorizer
考虑词汇在文本出现的频率,并关注包含该词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征


Truncated SVD 是截断SVD的变形,对样本矩阵进行分解,只计算用户指定的最大的K个奇异值。
8.独立成分分析ICA
1.基本概念
独立成分分析(Independent Component Analysis,ICA)是从多维统计数据中寻找潜在因子或成分的一种方法。
ICA与其它方法的重要区别在于,寻找满足统计独立和非高斯的成分。
2.ICA与PCA区别
- PCA 假设源信号间彼此非相关,ICA 假设源信号间彼此独立;
- PCA认为主元之间彼此正交,样本呈高斯分布; ICA则不要求样本呈高斯分布。






9.核主成分分析Kernel PCA
核主成分分析(Kernel PCA)是PCA的扩展,通过非线性映射将数据转换到一个高维空间中,在高维空间中使用PCA进行降维。
- 引入非线性映射函数,将原空间中的数据映射到高维空间,∅∅是隐函数
- 引入一个定理:空间中的任一向量都可以由该空间中的所有样本线性表示
核函数:通过两个向量点积来度量向量间相似度的函数。
通过使用核技巧,可以在原始特征空间中计算两个高维特征空间中向量的相似度。最常用的内核有linear、poly、RBF、sigmoid和cosine。


 变为
变为
10.T-分布邻域嵌入算法 T-SNE
T-分布领域嵌入 (T-distributed Stochastic Neighbor Embedding,T-SNE )算法是目前一个非常流行的对高维度数据进行非线性降维的算法。
基本思路:
为高维特征空间在二维平面/三维超平面上寻找一个投影,使得在原本的n维空间中相距很远的数据点在平面上同样相距较远,而原本相近的点在平面上仍然相近。
本质上,领域嵌入寻找 保留样本的邻居关系的 新的低维度数据表示。
为高维特征空间在二维三维平面上寻找投影,使近的还是近,远的还是远,保留邻居关系,用新的低维度数据表示
算法规则:
- 递归的相似观测必须对输出有更大的贡献
——用概率分布函数实现;
- 高维空间的分布必须与低维空间的分布相似
—— 用最小化KL距离实现;
11.受限玻尔兹曼机 RBM
玻尔兹曼机(Boltzman machine,BM) 是一种基于能量函数的建模方法,能够描述变量之间的高阶相互作用,所建模型和学习算法有比较完备的物理解释和严格的数理统计理论作基础。
BM是一种二值型(0或1)随机神经网络:
- 由可见层和隐层组成
- 网络节点分为可见单元(visible unit)和隐单元(hidden unit)
- 通过权值表达单元之间的相关性
- 使用了玻尔兹曼分布作为激活函数
- 原理是模拟退火算法
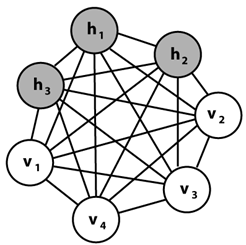
V表示所有可见单元,h表示所有隐单元

层间、层内全连接
受限玻尔兹曼机(Restricted BM,RBM)是BM的一种特殊拓扑结构:
RBM是一个概率模型
RBM是结合线性函数(隐层神经元)对输入数据进行非线性变换的方法

层间全连接、层内无连接
- 当给定可见层神经元状态时,
各隐层神经元之间是否激活条件独立;
- 当给定隐层神经元状态时,
各可见层神经元之间是否激活条件独立。


异常数据的检测与处理
样本中显著偏离其他数值的数据称为异常值(Outlier),其他预期的观测值标记为正常值或内点(Inlier)。
单变量异常检测
什么是极端值?
- 使用Z-scores时,得分绝对值高于3的观测值为可疑异常值
- 如果观测量是数据描述,以下两种数据当作可疑异常值,
- 第一种是比25分位值减去IQR*1.5小的观测量
- 第二种是比75分位值加上IQR*1.5大的观测量
注:IQR(Inter quartile range)是四分位距,即75分位值与25分位值的差。
如何使用Z-scores检测异常值?
- 使用sklearn中StandardScaler函数对所有连续变量进行标准化,找到那些绝对值大于3倍标准差的值。
单变量方法可以检测出相当多潜在异常值,但是,它不能检测那些不是极端值的异常值。
如果变量本身不是极端值,而它与其它变量或多个变量组合后出现不正常值,如何检测?
——可以先使用维数约简算法,再检查绝对值超过三倍标准偏差的成分。
Scikit-learn库提供了可直接使用并自动标出所有可疑实例的类:
covariance.EllipticEnvelope类:适合鲁棒的数据分布估计,由于异常值是数据总体分布中的极值点,它能够指出数据中的异常值。
svm.OneClassSVM类:可以模拟数据的形状,找出任何新的实例是否属于原来的类(默认情况下假定数据中没有异常值)。修改其参数后能作用于有异常值的数据集,比EllipticEnvelope系统更强大、更可靠。
EllipticEnvelope
假设全部数据可以表示成基本的多元高斯分布,EllipticEnvelope函数试图找出数据总体分布关键参数。尽可能简化算法背后的复杂估计,可认为该算法主要是检查每个观测量与总均值的距离。
由于总均值要考虑数据集中所有变量,该算法能够同时发现单变量和多变量的异常值。
Covariance.EllipticEnvelope函数使用时需要考虑污染参数(contamination parameter) ,该参数是异常值在数据集中的比例,默认取值为0.1,最高取值为0.5。
注:鉴于标准正态分布中观测值落在距离均值大于3(Z-score距离)区域的百分比是0.01-0.02,作为初始值,建议污染参数取值为0.01-0.02。
EllipticEnvelope算法的局限性
EllipticEnvelope函数适用于有控制参数的高斯分布假设,使用时要注意:非标化的数据、二值或分类数据与连续数据混合使用可能引发错误和估计不准确。
EllipticEnvelope函数假设全部数据可以表示成基本的多元高斯分布,当数据中有多个分布时,算法试图将数据适应一个总体分布,倾向于寻找最偏远聚类中的潜在异常值,而忽略了数据中其他可能受异常值影响的区域。
OneClassSVM
OneClassSVM是一种机器学习方法:
- 通过学习知道数据应该服从什么分布
- 适用于具有更多变量的数据集
- 检查新的样本是否符合以前的数据分布
参数有kernel、degree、gamma和nu:
- Kernel和Degree:这两个参数是相关的,
通常建议取默认值kernel为rbf,degree为3。
- Gamma:与rbf核相关的参数,建议设置越低越好。
- Nu: 决定模型是否必须符合一个精确的分布,
如果有异常值存在,Nu是必选参数。如果异常值比例很小,则Nu也会很小,反之很大。
验证指标
使用scikit-learn构建模型
1.加载datasets模块中数据集
2.将数据集划分为训练集和测试集 train_test_split()
在数据分析过程中,为了保证模型在实际系统中能够起到预期作用,一般需要将样本分成独立的三部分:
- 训练集(train set):用于估计模型。
- 验证集(validation set):用于确定网络结构或者控制模型复杂程度的参数。
- 测试集(test set):用于检验最优的模型的性能。
sklearn.model_selection.train_test_split(*arrays, **options)
| 参数名称 |
说明 |
| *arrays |
接收一个或多个数据集。代表需要划分的数据集,若为分类回归则分别传入数据和标签,若为聚类则传入数据。无默认。 |
| test_size |
接收float,int,None类型的数据。代表测试集的大小。如果传入的为float类型的数据则需要限定在0-1之间,代表测试集在总数中的占比;如果传入为int类型的数据,则表示测试集记录的绝对数目。该参数与train_size可以只传入一个。在0.21版本前,若test_size和train_size均为默认则testsize为25%。 |
| train_size |
接收float,int,None类型的数据。代表训练集的大小。该参数与test_size可以只传入一个。 |
| random_state |
接收int。代表随机种子编号,相同随机种子编号产生相同的随机结果,不同的随机种子编号产生不同的随机结果。默认为None。 |
| shuffle |
接收boolean。代表是否进行有放回抽样。若该参数取值为True则stratify参数必须不能为空。 |
| stratify |
接收array或者None。如果不为None,则使用传入的标签进行分层抽样。 |
- Øtrain_test_split函数根据传入的数据,分别将传入的数据划分为训练集和测试集。
- Ø如果传入的是1组数据,那么生成的就是这一组数据随机划分后训练集和测试集,总共2组。如果传入的是2组数据,则生成的训练集和测试集分别2组,总共4组。
- Øtrain_test_split是最常用的数据划分方法,在model_selection模块中还提供了其他数据集划分的函数,如PredefinedSplit,ShuffleSplit等。
3.K折交叉验证法
- 当数据总量较少的时候,使用上面的方法将数据划分为三部分就不合适了。
- 常用的方法是留少部分做测试集,然后对其余N个样本采用K折交叉验证法,基本步骤如下:
- 将样本打乱,均匀分成K份。
- 轮流选择其中K-1份做训练,剩余的一份做验证。
- 计算预测误差平方和,把K次的预测误差平方和的均值作为选择最优模型结构的依据。
4.使用sklearn转换器进行数据预处理与降维
sklearn转换器三个方法
sklearn把相关的功能封装为转换器(transformer)。使用sklearn转换器能够实现对传入的NumPy数组进行标准化处理,归一化处理,二值化处理,PCA降维等操作。转换器主要包括三个方法:
| 方法名称 |
说明 |
| fit |
fit方法主要通过分析特征和目标值,提取有价值的信息,这些信息可以是统计量,也可以是权值系数等。 |
| transform |
transform方法主要用来对特征进行转换。从可利用信息的角度可分为无信息转换和有信息转换。无信息转换是指不利用任何其他信息进行转换,比如指数和对数函数转换等。有信息转换根据是否利用目标值向量又可分为无监督转换和有监督转换。无监督转换指只利用特征的统计信息的转换,比如标准化和PCA降维等。有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征和LDA降维等。 |
| fit_transform |
fit_transform方法就是先调用fit方法,然后调用transform方法。 |
sklearn部分预处理函数与其作用
| 函数名称 |
说明 |
| MinMaxScaler |
对特征进行离差标准化。 |
| StandardScaler |
对特征进行标准差标准化。 |
| Normalizer |
对特征进行归一化。 |
| Binarizer |
对定量特征进行二值化处理。 |
| OneHotEncoder |
对定性特征进行独热编码处理。 |
| FunctionTransformer |
对特征进行自定义函数变换。 |
构建并评价聚类模型
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组内样本最小化而组间(外部)距离最大化,如图所示。

1、聚类方法类别
| 算法类别 |
包括的主要算法 |
| 划分(分裂)方法 |
K-Means算法(K-平均),K-MEDOIDS算法(K-中心点)和CLARANS算法(基于选择的算法)。 |
| 层次分析方法 |
BIRCH算法(平衡迭代规约和聚类),CURE算法(代表点聚类)和CHAMELEON算法(动态模型)。 |
| 基于密度的方法 |
DBSCAN算法(基于高密度连接区域),DENCLUE算法(密度分布函数)和OPTICS算法(对象排序识别)。 |
| 基于网格的方法 |
STING算法(统计信息网络),CLIOUE算法(聚类高维空间)和WAVE-CLUSTER算法(小波变换)。 |
2、聚类算法模块cluster提供的聚类算法
| 函数名称 |
参数 |
适用范围 |
距离度量 |
| KMeans |
簇数 |
可用于样本数目很大,聚类数目中等的场景。 |
点之间的距离 |
| Spectral clustering |
簇数 |
可用于样本数目中等,聚类数目较小的场景。 |
图距离 |
| Ward hierarchical clustering |
簇数 |
可用于样本数目较大,聚类数目较大的场景。 |
点之间的距离 |
| Agglomerative clustering |
簇数,链接类型,距离 |
可用于样本数目较大,聚类数目较大的场景。 |
任意成对点线图间的距离 |
| DBSCAN |
半径大小,最低成员数目 |
可用于样本数目很大,聚类数目中等的场景。 |
最近的点之间的距离 |
| Birch |
分支因子,阈值,可选全局集群 |
可用于样本数目很大,聚类数目较大的场景。 |
点之间的欧式距离3、 |
3、sklearn估计器estimator的方法
聚类算法实现需要sklearn估计器(estimator)。sklearn估计器和转换器类似,拥有fit和predict两个方法。两个方法的作用如下。
| 方法名称 |
说明 |
| fit |
fit方法主要用于训练算法。该方法可接收用于有监督学习的训练集及其标签两个参数,也可以接收用于无监督学习的数据。 |
| predict |
predict用于预测有监督学习的测试集标签,亦可以用于划分传入数据的类别。 |
4、聚类模型评价指标
聚类评价的标准是组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。即组内的相似性越大,组间差别越大,聚类效果就越好。sklearn的metrics模块提供的聚类模型评价指标。
| 方法名称 |
真实值 |
最佳值 |
sklearn函数 |
| ARI评价法(兰德系数) |
需要 |
1.0 |
adjusted_rand_score |
| AMI评价法(互信息) |
需要 |
1.0 |
adjusted_mutual_info_score |
| V-measure评分 |
需要 |
1.0 |
completeness_score |
| FMI评价法 |
需要 |
1.0 |
fowlkes_mallows_score |
| 轮廓系数评价法 |
不需要 |
畸变程度最大 |
silhouette_score |
| Calinski-Harabasz指数评价法 |
不需要 |
相较最大 |
calinski_harabaz_score |
构建并评价分类模型
sklearn库常用分类算法函数
| 模块名称 |
函数名称 |
算法名称 |
| linear_model |
LogisticRegression |
逻辑斯蒂回归 |
| svm |
SVC |
支持向量机 |
| neighbors |
KNeighborsClassifier |
K最近邻分类 |
| naive_bayes |
GaussianNB |
高斯朴素贝叶斯 |
| tree |
DecisionTreeClassifier |
分类决策树 |
| ensemble |
RandomForestClassifier |
随机森林分类 |
| ensemble |
GradientBoostingClassifier |
梯度提升分类树 |
分类模型的评价指标
| 方法名称 |
最佳值 |
sklearn函数 |
| Precision(精确率) |
1.0 |
metrics.precision_score |
| Recall(召回率) |
1.0 |
metrics.recall_score |
| F1值 |
1.0 |
metrics.f1_score |
| Cohen’s Kappa系数 |
1.0 |
metrics.cohen_kappa_score |
| ROC曲线 |
最靠近y轴 |
metrics. roc_curve |
- 除了使用数值,表格形式评估分类模型的性能,还可通过绘制ROC曲线的方式来评估分类模型。
- ROC曲线横纵坐标范围为[0,1],通常情况下ROC曲线与X轴形成的面积越大,表示模型性能越好。但是当ROC曲线处于下图中蓝色虚线的位置,就表明了模型的计算结果基本都是随机得来的,在此种情况下模型起到的作用几乎为零。故在实际中ROC曲线离图中蓝色虚线越远表示模型效果越好。

构建并评价回归模型

常用回归模型
| 回归模型名称 |
适用条件 |
算法描述 |
| 线性回归 |
因变量与自变量是线性关系 |
对一个或多个自变量和因变量之间的线性关系进行建模,可用最小二乘法求解模型系数。 |
| 非线性回归 |
因变量与自变量之间不都是线性关系 |
对一个或多个自变量和因变量之间的非线性关系进行建模。如果非线性关系可以通过简单的函数变换转化成线性关系,用线性回归的思想求解;如果不能转化,用非线性最小二乘方法求解。 |
| Logistic回归 |
因变量一般有1和0(是与否)两种取值 |
是广义线性回归模型的特例,利用Logistic函数将因变量的取值范围控制在0和1之间,表示取值为1的概率。 |
| 岭回归 |
参与建模的自变量之间具有多重共线性 |
是一种改进最小二乘估计的方法。 |
| 主成分回归 |
参与建模的自变量之间具有多重共线性 |
主成分回归是根据主成分分析的思想提出来的,是对最小二乘法的一种改进,它是参数估计的一种有偏估计。可以消除自变量之间的多重共线性。 |
sklearn库常用回归算法函数
| 模块名称 |
函数名称 |
算法名称 |
| linear_model |
LinearRegression |
线性回归 |
| svm |
SVR |
支持向量回归 |
| neighbors |
KNeighborsRegressor |
最近邻回归 |
| tree |
DecisionTreeRegressor |
回归决策树 |
| ensemble |
RandomForestRegressor |
随机森林回归 |
| ensemble |
GradientBoostingRegressor |
梯度提升回归树 |
回归模型评价指标
- 回归模型的性能评估不同于分类模型,虽然都是对照真实值进行评估,但由于回归模型的预测结果和真实值都是连续的,所以不能够求取Precision、Recall和F1值等评价指标。回归模型拥有一套独立的评价指标。
- 平均绝对误差、均方误差和中值绝对误差的值越靠近0,模型性能越好。可解释方差值和R方值则越靠近1,模型性能越好。
| 方法名称 |
最优值 |
sklearn函数 |
| 平均绝对误差 |
0.0 |
metrics. mean_absolute_error |
| 均方误差 |
0.0 |
metrics. mean_squared_error |
| 中值绝对误差 |
0.0 |
metrics. median_absolute_error |
| 可解释方差值 |
1.0 |
metrics. explained_variance_score |
| R方值 |
1.0 |
metrics. r2_score |
使用scikit-learn构建模型小结
- sklearn数据分析技术的基本任务主要体现在聚类、分类和回归三类。
- 每一类又有对应的多种评估方法,能够评价所构建模型的性能优劣。
模型评估与选择
1.评估方法
1-1)留出法
- 训练集+测试集:互斥互补
- 训练集训练模型,测试集测试模型
- 合理划分、保持比例
- 单次留出与多次留出
- 多次留出法:如对专家样本随机进行100次训练集/测试集划分,评估结果取平均
1-2)交叉验证法
- K折交叉验证:将专家样本等份划分为K个数据集,轮流用K-1个用于训练,1个用于测试
- P次K折交叉验证

1-3)自助法
2.性能度量
2-1)均方误差
2-2)错误率和精度:
错误率:分类错误样本数占总样本数比例
精度:1-错误率,分类正确样本数占总样本数比例
2-3)查准率和查全率
2-4)F1系数
3.偏差与方差
泛化错误率的构成:偏差+方差+噪声
- 偏差:模型输出与真实值的偏离程度,刻画了算法的拟合能力
- 方差:同样大小的训练集的变动导致的学习性能的变化,即数据扰动造成的影响
- 噪声:当前学习器所能达到的泛化误差的下限
偏差大:拟合不足/欠拟合;方差大:过拟合