之前都是通过看视屏,博客,公众号的形式来学习,还是很零散的,这次看了《Redis深度历险:核心原理与应用实践》,之前粗略读了一遍,现在用笔记的形式把重点再记录下。 2020-7.26
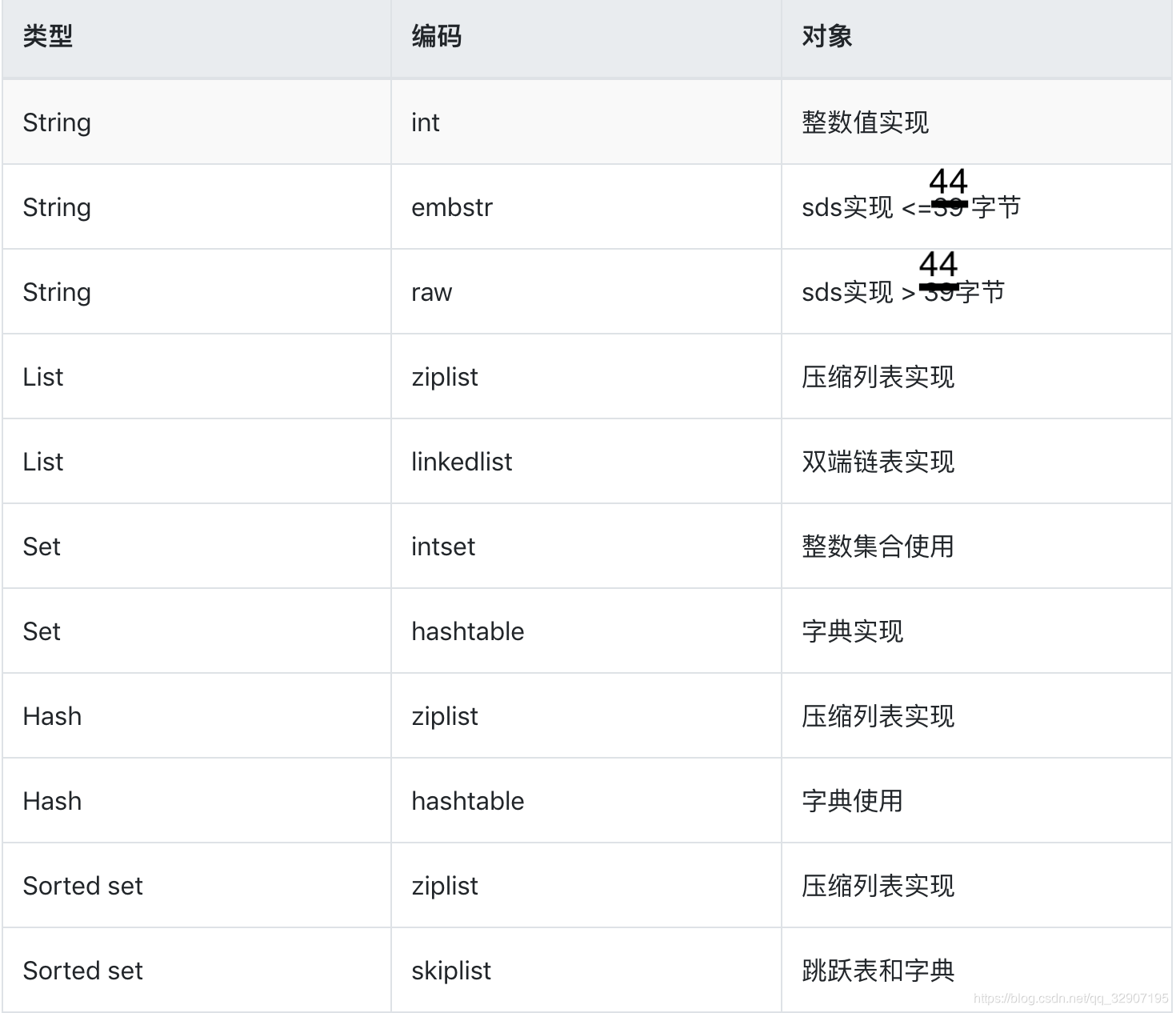
注:List的结构中:当数据量大的时候 Redis将链表和ziplist结合起来组成了quicklist
1.2.2 5种基础数据结构
string
Redis的字符串是动态字符串,是可以修改的字符串,采用预分配冗余空间的方式来减少内存的频繁分配。当字符串长度小于1MB是,扩容都是加倍现有的空间,如果字符串长度超过1MB,扩容是一次只会多扩1MB的空间
键值对
set name codehole
get name
exists name
del name
get name
批量键值对
set name1 codehole
set name2 holycoder
mget name1 name2 name3
mset name1 boy name2 girl name3 unknown
mget name1 name2 name3
过期和set命令拓展
set name codehole
get name
expire name 5 #5s后过期
setex name 5 codehole
setnx name code hole
计数
set age 30
incr age
incrby age 5
incrby age -5
set codehole 9223372036854775807 #Long.Max
incr codehole #报错
字符串由多个字节组成,每个字节由8个bit构成,可以讲一个字符串看成很多bit的组合,这便是bitmap数据结构
list
当链表弹出了最后一个元素后,该数据结构被自动删除,内存被回收
队列
rpush books python java golang
llen books
lpop books
栈
rpush books python java golang
rpop books
慢操作
rpush books pthon java golang
lindex books 1
lrange books 0 -1 #获取所有元素
ltrim books 1 -1 #ltrim叫lretain更合适,两个参数start_index,end_index.index可以为负数,index=-1表示倒数第一个元素
ltrim books 1 0 #清空列表
快速列表
列表元素少的时候,会用一块连续的内存存储,这个结构是ziplist,元素多的时候编程quicklist,是链表和ziplist 的组合。quicklist既满足了快速的插入删除性能,又不会有太多的空间冗余
hash
采取了渐进式rehash策略
hset books java "think in java"
hset books golang "concurrency in go"
hgetall books
hlen books
hget books java
hmset books java "effective java" golang "modern golang programming"
hset user_laoqian age 29
hincrby user_laoqian age 1
set
sadd books python
sadd books java golang
smembers books
sismember books java
scard books # 获取长度
spop books #随机弹
zset
zadd books 9.0 "think in java"
zadd books 8.9 "java concurrency"
zrange books 0 -1 #按score排序列出
zrevrange books 0 -1 #按score逆序列出
zcard books
zscore books "java concurrency"
zrangebyscore books 0 8.91
zrangebyscore books -inf 8.91 withscores
zrem books "java concurrency"
元素少用ziplist,多的时候用跳表
1.2.3 容器型数据结构的通用规则
list,set,hash,zset 是容器型数据结构
create if not exists
drop if no ellements
1.2.4 过期时间
过期是以对象为单位的,比如一个hash结构的过期是整个hash对象的过期,而不是其中某个子key的过期
注意:如果一个字符串已经设置了过期时间,然后用set方法修改了它,他的过期时间就会消失
set codehole yoyo
expire codehole 600
tll codehole
set codehole yoyo
ttl codehole
1.3 千帆竞发----分布式锁
1.3.1分布式锁的奥义
在redis2.8版本中,作者加入了set指令的拓展参数,是的setnx和expire指令可以一起执行
set lock:codehole true ex 5 nx
del lock:codehole
1.3.2 超时问题
1.3.3 可重入性
可以用ThreadLocal,hashmap和jedis结合来实现可重入性
参见23页
1.4 缓兵之计----延时队列
1.4.1 异步消息队列
1.4.2 队列空了怎么半
1.4.3 阻塞读
1.4.4 空闲连接自动断开
如果线程一直阻塞在那里,Redis的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少资源占用。这个时候blpop/brpop会抛出异常。
所以编写客户端消费者的时候,如果捕获到异常,还要重试
1.4.5 锁冲突处理
1.直接排出异常,通知用户稍后重试
2.sleep一会儿,然后重试
3.将请求转移至延时队列,过一会儿再试
1.4.6 延时队列的实现
zset来实现,score是时间 P30
1.4.7 进一步优化
同一任务可能被多个进程取到之后再使用zrem进行争抢,那些没抢到的进程都白取了一次任务,这是浪费,可以考虑使用lua scripting来优化,将zrangebyscore和zrem一同挪到服务器端进行原子操作,这样多个进程之间争抢任务时就不会出现这种浪费了。
1.5 节衣缩食----位图
1.5.1 基本用法
setbit 是从0开始
零存整取
setbit s 1 1
setbit s 2 1
get s
零存零取
setbit w 1 1
setbit w 2 1
getbit w 1
getbit w 2
整存领取
set w h
getbit w 1
getbit w 2
如果对应位的字节是不可打印字符,redis-cli会显示该字符的十六进制形式
1.5.2 统计和查找
set w hello
bitcount w
bitcount w 0 0 #第一个字符中1的位数
bitcount w 0 1 #前两个字符中1的位数
bitpos w 0 #第一个0位
bitpos w 1 #第一个1位
bitpos w 1 1 1 #从第二个字符算起,第一个1位
bitpos w 1 2 2 #从第三个字符算起,第一个1位
1.5.3 魔术指令bitfield
setbit和getbit指定位的值都是单个位的,如果用多个位,就必须使用管道来处理
在redis3.2之后,不用管道也可以一次进行多个位的操作
bitfield有三个子指令,分别是get,set,incrby,他们都可以对指定位片段进行读写,但是最多只能处理64个连续的位,如果超过64位,就得使用多个子指令,bitfield可以一次执行多个子指令。
set w hello
bitfield w get u4 0 #从第一个位开始取4个位,结果是无符号数
bitfield w get u3 2 #从第三个位开始取3个位,结果是无符号数
bitfield w get i4 0 #从第一个位开始取4个位,结果是有符号数
bitfield w get i3 2 #从第三个位开始取3个位,结果是有符号数
bitfield w get u4 0 get u3 2 get i4 0 get i3 2
bitfield w set u8 8 97 #将第二个字符e改成a
默认策略折返wrap
set w hello
bitfield w incry u4 2 1 #从第三个位开始,对接下来的4位无符号数+1(超过边界时又从0开始)
bitfield指令提供了溢出策略子指令overflow,用户可以选择溢出行为,默认是折返(wrap),还可以选择时报(fail)-报错不执行,以及饱和截断(sat)-超过了范围就停留在最大值或者最小值。overflow指令只影响接下来的第一条指令,这条指令执行完后一出策略就会变成默认值折返(wrap)
饱和截断sat
set w hello
bitfield w overflow sat incrby u4 2 1 #超过边界时一直保持最大值
失败不执行fail
set w hello
bitfield overflow fail incrby u4 2 1 #超过边界时返回nil
1.6 四两拨千斤----HyperLogLog
统计pv(page view)时可以用incr
统计uv(unique view)时sadd 和scard会非常浪费空间
HyperLogLog是Redis的高级数据结构,非常有用
1.6.1 使用方法
pfadd和pfcount
pfadd codehole user1
pfcount codehole
10万个数据误差大约在0.277%
1.6.2 pfadd中的pf是什么意思
HyperLogLog数据结构的发明人Philippe Flajolet
pf是缩写
1.6.3 pfmerger适合的场合
用于将多个pf计数值累加在一起形成一个新的pf值
比如在网站中我们有两个内容差不多的页面,要对页面的UV访问量进行合并,pfmerge就可以派上用场了
每个数进行二进制转换,查看末尾最多有多少连续的0,UV = 2的n次方。
1.6.4 注意事项
HyperLogLog占用特别小
计数比较小时,存储空间采用稀疏矩阵存储,空间占用很小
当空间超过了阀值时,才会一次性转为稠密矩阵,才会占用12KB空间
1.6.5 实现原理
用1024个桶进行测试,计算平均是用了调和平均(倒数的平均)。普通的平均法肯能因为个别离群值对平均结果产生了较大的影响,调和平均可以有效平滑离群值的影响。
读了下实现的算法,真的厉害
1.6.6 pf的内存占用为什么是12KB
Redis的HyperLogLog实现中用的是16384个桶,也就是2的14次方,每个桶的maxbits需要6个bit来存储,最大可以表示maxbits63,于是总共占用内存2的14次方*6/8 ,得出来的结果就是12KB
理论上最大UV是2的63次方
1.7 层峦叠嶂----布隆过滤器
主要是去重
1.7.1 布隆过滤器是什么
一个不怎么精确的set结构
当它说某个值存在的时候,可能不存在
当它说某个值不存在的时候,一定不存在
1.7.2 Redis中的布隆过滤器
Redis官方提供的布隆过滤器在Redis4.0以后提供了插件的功能后才闪亮登场。
1.7.3 布隆过滤器的基本用法
bf.add
bf.exists
bf.madd
bf.mexists
bf.add codehole user1
bf.add codehole user2
bf.exists codehole user1
bf.madd codehole user4 user5 user6
bf.exists codehole user2 user4 user5
Jedis2.X没有提供指令拓展机制,无法用Jedis来访问Redis Module提供的bf.xxx指令。RedisLabs提供了一个单独的包JReBloom,但是它是基于Jedis3.0,但是Jedis-3.0这个包目前(2018.9)还没有进入release阶段,没有进入maven中央仓库,需要在Github下载,不方便。可以直接用Lettuce,支持指令拓展。
Redis还提供了带自定义参数的布隆过滤器,需要我们在add之前使用bf.reserve指令显示创建。如果对应的key已经存在,bf.reserve回报错。bf.reverser有三个参数,分别是key,error_rate(错误率)和initial_size
error_rate越低,需要的空间越大。
initial_size表示预计要放入的元素数量,当实际数量超出这个数值时,误判率会上升,所以需要提前设置一个较大的数值避免超出导致误判率升高。
如果不实用bf.reserve,默认的error_rate是0.01,默认的initial_size是100.
1.7.4 注意事项
布隆过滤器的initial_size设置过大会浪费空间,设置的过下,就会影响准确率,在使用前要尽可能精确的估计元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多。
1.7.5 布隆过滤器的原理
每个布隆过滤器对应到Redis的数据结构里面就是一个大型的位数组和几个不一样的无偏hash函数
1.7.6空间占用估计
https://krisives.github.io/bloom-calculator
1.7.8 用不上Redis4.0怎么办
以下两个库可以在Github上找到,它们是Redis4.0版本的布隆过滤器的可选方案
1.python版本,pyreBloom
2.java版本,orestes-bloomfilter
1.7.9 布隆过滤器的其他应用
1.爬虫系统对URL去重,避免重爬
2.在NoSQL数据库领域中使用非常广泛,HBase,Cassandra,还有LevelDB,RocksDB内部都有布隆过滤结构,当用户来查某个row时,可以先过滤掉不存在的请求,再去磁盘查询
3.邮件系统的垃圾邮件用到了布隆过滤器
1.8 断尾求生----简单限流
通过zset,滑动时间窗口来实现限流
1.9 一毛不拔----漏斗限流
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 漏斗限流算法
*
* @author wangye
* @date 2020/07/27
*/
public class FunnelRateLimiter {
private Map<String, Funnel> funnelMap = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
FunnelRateLimiter limiter = new FunnelRateLimiter();
int testAccessCount = 30;
int capacity = 5;
int allowQuota = 5;
int perSecond = 30;
int allowCount = 0;
int denyCount = 0;
for (int i = 0; i < testAccessCount; i++) {
boolean isAllow = limiter.isActionAllowed("dadiyang", "doSomething", 5, 5, 30);
if (isAllow) {
allowCount++;
} else {
denyCount++;
}
System.out.println("访问权限:" + isAllow);
Thread.sleep(1000);
}
System.out.println("报告:");
System.out.println("漏斗容量:" + capacity);
System.out.println("漏斗流动速率:" + allowQuota + "次/" + perSecond + "秒");
System.out.println("测试次数=" + testAccessCount);
System.out.println("允许次数=" + allowCount);
System.out.println("拒绝次数=" + denyCount);
}
/**
* 根据给定的漏斗参数检查是否允许访问
*
* @param username 用户名
* @param action 操作
* @param capacity 漏斗容量
* @param allowQuota 每单个单位时间允许的流量
* @param perSecond 单位时间(秒)
* @return 是否允许访问
*/
public boolean isActionAllowed(String username, String action, int capacity, int allowQuota, int perSecond) {
String key = "funnel:" + action + ":" + username;
if (!funnelMap.containsKey(key)) {
funnelMap.put(key, new Funnel(capacity, allowQuota, perSecond));
}
Funnel funnel = funnelMap.get(key);
return funnel.watering(1);
}
private static class Funnel {
private int capacity;
private float leakingRate;
private int leftQuota;
private long leakingTs;
public Funnel(int capacity, int count, int perSecond) {
this.capacity = capacity;
// 因为计算使用毫秒为单位的
perSecond *= 1000;
this.leakingRate = (float) count / perSecond;
}
/**
* 根据上次水流动的时间,腾出已流出的空间
*/
private void makeSpace() {
long now = System.currentTimeMillis();
long time = now - leakingTs;
int leaked = (int) (time * leakingRate);
if (leaked < 1) {
return;
}
leftQuota += leaked;
// 如果剩余大于容量,则剩余等于容量
if (leftQuota > capacity) {
leftQuota = capacity;
}
leakingTs = now;
}
/**
* 漏斗漏水
*
* @param quota 流量
* @return 是否有足够的水可以流出(是否允许访问)
*/
public boolean watering(int quota) {
makeSpace();
int left = leftQuota - quota;
if (left >= 0) {
leftQuota = left;
return true;
}
return false;
}
}
}
1.9.1 Redis-Cell
Redis4.0提供了限流Redis模块,Redis-Cell。该模块也使用了漏斗算法,并提供了原子的限流指令。
cl.throttle
"用户老钱回复行为“的频率为每60s最多30次(漏水速率)。漏斗的初始容量为15,也就是说一开始可以连续回复15个帖子,然后才开始受漏水的影响。
cl.throttle laoqian:reply 15 30 60 1
1)(integer)0 #0表示允许,1表示拒绝
2)(integer)15 #漏斗容量 capacity
3)(integer)14 #漏斗剩余空间left_quota
4)(integer)-1 #如果被拒绝了,需要多长时间后重试(漏斗有空间了,单位秒)
5)(integer)2 #多长时间后,漏斗完全空出来(left_quota == capacity,单位:秒)
应用于UGC,用户原创内容
1.10 近水楼台----GeoHash
1.10.1 用数据库来算附近的人
1.10.2 GeoHash算法

编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数,可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程度就越小。
GeoHash算法会继续对这个整数做一次base32编码(0-9,a-z,去掉a,i,l,o这四个字母)变成这四个字符串。在Redis里,经纬度使用52位的整数进行编码,放进了zset里,zset的value是元素的key,score是GeoHash的52位整数值。zset的score虽然是浮点数,但是对于52位的整数值,他可以无损存储。
在使用Redis进行Geo查询时,我们要时刻想到它的内部结构实际上只是一个zset(skiplist)。通过zset的score排序就可以得到坐标附近的其他元素,通过score还原成坐标值就可以得到元素的原始坐标。
1.10.3 Geo指令的基本用法
增加
geoadd company 116.48105 39.996794 juejin
geoadd company 116.514203 39.905409 ireader 6 6 xiaomi
距离(m,km,ml,ft)
geodist company juejin ireader km
获取元素位置
getpos company juejin
getpos company juejin ireader
获取元素的hash值(可以直接去http://geohash.org/${
hash}上直接定位
geohash company ireader
附近的公司
georadiusbymember company ireader 20 km count 3 asc #查找距离最近的公司,包括自己)
georadiusbymember company ireader 20 km count 3 desc
#三个可选参数withcoord,withdist,withhash用来携带附加参数
georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc
根据坐标来查询附近的元素
georadius company 116 39 20 km withdist count 3 asc
1.10.4 注意事项
在redis的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个key数据过大,会对集群的迁移造成较大的影响,在集群环境中,单个key对应的数据量不宜超过1MB,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
仅以Geo的数据使用单独的redis实例部署,不使用集群环境
如果数据量过亿个,甚至更大,需要对Geo数据进行拆分,按国家,省,市,区分,降低单个zset的大小。
1.11 大海捞针----scan
keys
keys codehole*
keys code*hole
缺点:
可能出来几百万数据
单线程,阻碍其他命令执行
1.11.1 scan基本用法
scan 0 match key99* count 1000
1.11.2 字典的数据结构
scan指令返回的游标是第一维数组的位置索引,我们将这个位置索引称为槽(slot),最后一个参数就表示要便历的槽位数
1.11.3 便利顺序
它不是从第一维数组的第0位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以采用这种特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
1.11.4 字典扩容
1.11.5对比扩容,缩容前后的便利顺序
我们会发现高位进位加法的遍历顺序,rehash后的槽位在遍历顺序上是相邻的。
1.11.6 渐进式rehash
java的HashMap在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果HashMap中元素特别多,线程就会出现卡顿现象。redis为了解决这个问题,采用了渐进式rehash。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对hash的指令操作中渐渐的将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于rehash中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面寻找。
scan也要考虑这个问题,对于rehash中的字典,它需要同时扫描新旧槽位,然后将结果融合返回给客户端
1.11.7 更多的scan指令
scan 遍历zset
hscan 遍历hash
sscan 遍历set
1.11.8 大key扫描
reids-cli -h 127.0.0.1 -p 7001 --bigkeys #可能抬升Redis的ops,导致线上报警
redis-cli -h 127.0.0.1 -p 7001 --bigkeys -i 0.1 #每隔100条指令就会休眠0.1s,ops就不会剧烈抬升,但是扫描的时间会变长
2 原理篇
2.1 鞭辟入里----线程IO模型
单线程,IO多路复用
2.1.1 非阻塞IO
2.1.2 事件轮询(多路复用)
2.1.3 指令队列
2.1.4 相应队列
2.2 交头接耳----通信协议
2.2.1 RESP
redis serialization protocol
2.3 未雨绸缪----持久化
快照是一次全量备份,AOF是连续的增量备份。
2.3.1 快照原理
Redis使用操作系统的COW(copy on write)机制来实现持久化
2.3.2 fork(多进程)
Redis在持久化时会调用glibc的函数fork产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求
随着父进程修改操作的持续进行,越来越多的共享页面被分离出来,内存就会持续增粘隔,但是也不会超过原有内存的2倍。
2.3.3 AOF原理
Redis先执行指令才将日志存盘
2.3.4 AOF重写
Redis提供了bgrewriteof指令用于对AOF日志进行瘦身,其原理就是开辟一个子进程对内存进行遍历,转换成一系列Redis的操作指令,序列化到一个新的AOF日志文件中。序列化完成后再将操作期间发生的增量AOF日志追加到这个新的AOF日志文件中,追加完毕后就立即替代旧的AOF日志文件了,瘦身工作就完成了。
2.3.5 fsync
在生产环境中,Redis通常是每隔1s左右执行一次fsync操作,这个1s周期是可以配置的,这是在数据安全性和性能之间做的一个折中,在保持高性能的同时,尽可能是数据少丢失。
Redis也提供了另外两种策略:
一是用不调用fsync,让操作系统来决定何时同步
另一个是来一个指令就调用sync一次,结果导致非常慢
2.3.6 运维
快照是通过开启子进程的方式执行的,它是一个比较耗资源的操作。
1.遍历整个内存,大块写磁盘回家中系统负载。
2.AOF的fsync是一个耗时的IO操作,它会降低Redis性能,同时增加系统IO负担。
通常Redis的祝节点不会进行持久化操作,持久化操作主要在从节点进行。从节点是备份节点,没有来自客户端请求的压力,它的操作资源往往比较充沛。
2.3.7 Redis4.0混合持久化
rdb文件内容和增量的AOF文件存在一起。这里AOF日志不再是全量的日志,而是自持久化开始到持久化结束的这点时间发生的增量AOF日志,通常这部分AOF日志很小。
于是Redis重启的时候,可以先加载rdb的内容,然后重放增量AOF日志,就可以替代之前的AOF全量文件重放,重启效率得到大幅提升。
2.4 雷厉风行----管道
这个技术本质上是由客户端提供的,跟服务端没有什么直接的关系。
2.4.1 Redis的消息交互
2.4.2 管道压力测试
redis-benchmark -t set -q
QPS达到5万
redis-benchmark -t set -P 2 -q
QPS达到9万
P=3时,QPS达到10w/s
2.4.3 深入理解管道本质
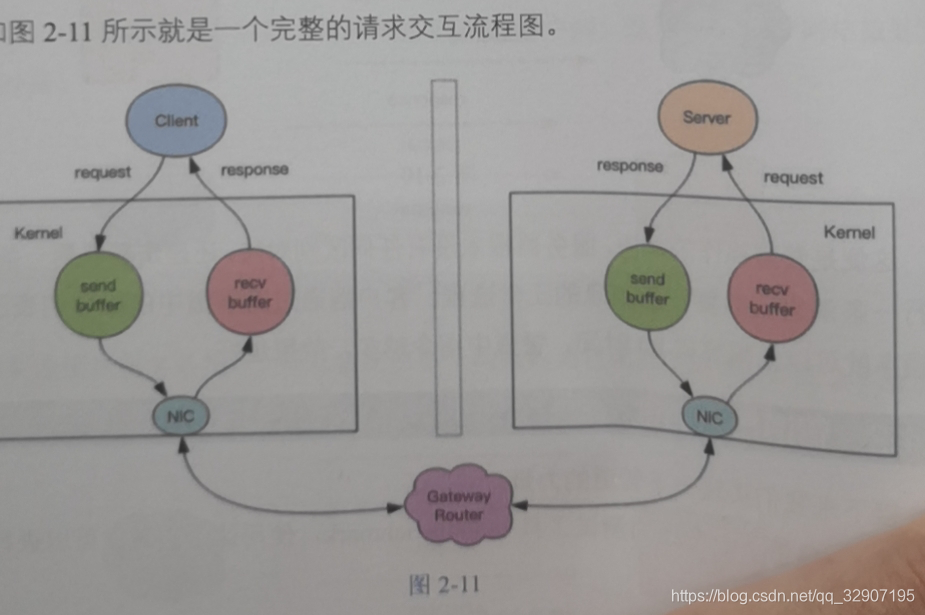
对于管道来说,连续的write操作根本就没有耗时,之后第一个read操作会等待一个网络的来回开销,然后所有的相应消息都已经送回到内核的读缓冲了,后续的read操作直接就可以从缓冲中拿到结果,瞬间就可以返回了。
2.5 同舟共济----事务
2.5.1 Redis事务的基本用法
multi,exec,discard
multi
incr books
incr books
exec
2.5.2 原子性
redis不是原子性的
事务执行到中间时失败了,后面的指令还是会继续执行。Redis根本不具备原子性,仅仅满足了事务中的隔离性中的“串行化”----当前事务有着不被其他事务打断的权利
2.5.3 discard(丢弃)
discard之后,队列中的所有指令都没执行,就好像multi和discard中间的所有指令从未发生过一样。
2.5.4 优化
上面的Redis事务在发送每个指令到事务缓存队列都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络IO时间也会线性增长,所以Redis的客户端在执行事务时都会结合pipeline一起使用,这样可以讲多次IO操作压缩为单次IO操作。
2.5.5 watch
watch books
incr books
multi
incr books
exec
2.5.6 注意事项
Redis禁止在multi和exec之间执行watch指令,而必须在multi之前盯住关键变量
2.6 小道消息----PubSub
2.6.1 消息多播
2.6.2 PubSub
为了支持消息多播,不能再依赖那5种基本数据类型,单独使用了一个模块PubSub
2.6.3 模式订阅
subscribe codehole.image codehole.text #同时订阅
publish codehole.image https://www.google.com/dudo.png
模式订阅功能
psubscribe codehole.*
2.6.4消息结构
2.6.5 PubSub的缺点
生产者传递过来一个消息,Redis会直接找到相应的消费者传递过去。若果一个消费者都没有,那么消息会被直接丢弃。
如果Redis停机重启,PubSub的消息是不会持久化的,毕竟Redis宕机就相当于一个消费者都没有,所有的消息会被直接丢弃
2.7 开源节流----小对象压缩
2.7.1 32bitVS64bit
Redis如果使用32bit编译,内部所有数据结构所使用的指针空间占用会少一半,如果你的Redis使用内存不超过4GB,可以考虑使用32bit进行编译,能够节约大量内存。4GB的容量作为一些小型站点的缓存数据库是绰绰有余的,如果不足还可以通过增加实例的方式来解决。
2.7.2 小对象压缩存储(ziplist)
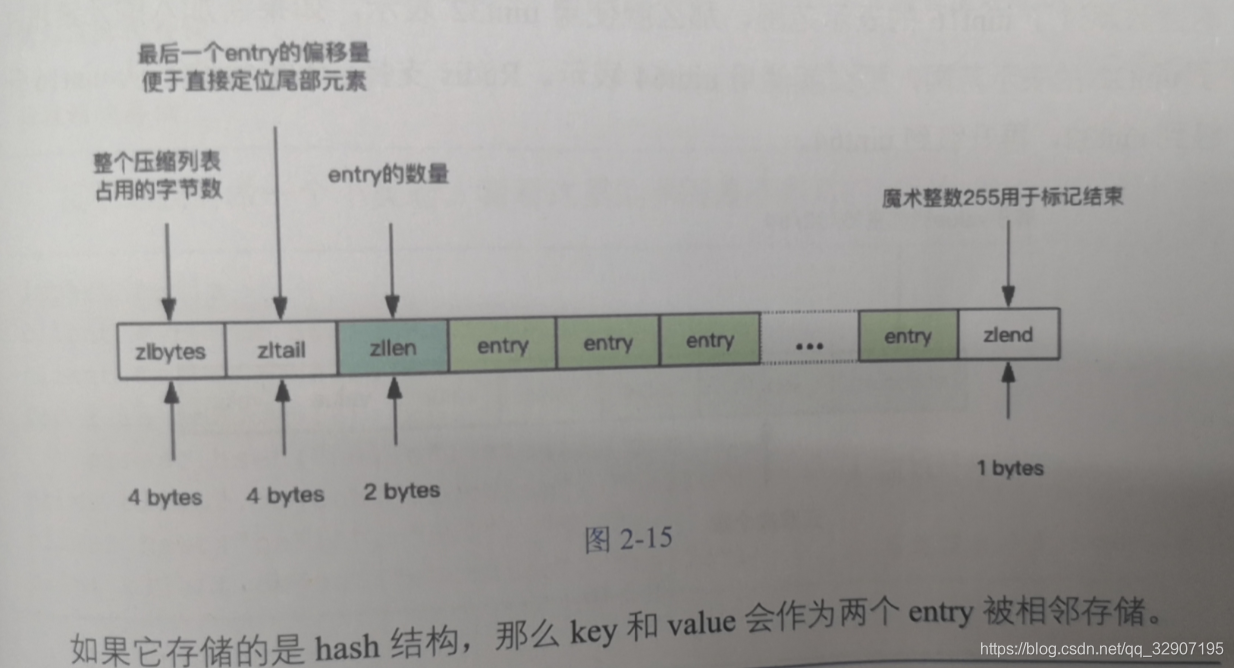
intset
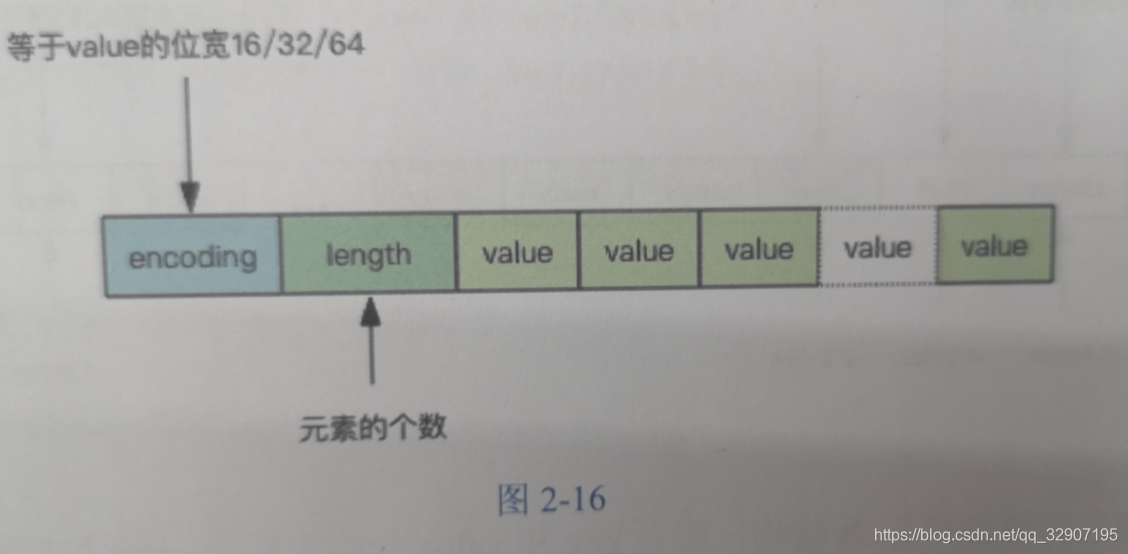

2.7.3 内存回收机制
Redis并不总是将空闲内存立即归还给操作系统。
操作系统是以页为单位来回收内存的,这个页上只要还有一个key在使用,那么它就不能被回收
如果执行了flushdb,内存全被回收,原因是所有的key都被干掉了,大部分之前使用的页面都完全干净了,就会立即被操作系统回收
Redis虽然无法保证立即回收已经删除的key的内存,但是它会重新使用那些尚未回收的空闲内存。
2.7.4 内存分配算法
Redis可以使用jemalloc(facebook)库来管理内存,也可以切换到tcmalloc(google)库。因为jemalloc的性能稍微好点,Redis默认使用了jemalloc。
info memory
3 集群篇
3.1 有备无患–主从同步
3.1.1 CAP原理
C:consistent 一致性
A: Availability 可用性
P:Partition tolerance 分区容忍性
当网络分区发生时,一致性和可用性两难全
3.1.2 最终一致
Redis的主从数据是异步同步的,所以不满足一致性要求
3.1.3 主从同步和从从同步
3.1.4 增量同步
Redis同步是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存buffer中,然后异步的将buffer中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到哪里了(偏移量)
因为内存的buffer是有限的,所以Redis主节点不能将所有的指令都记录在内存buffer中。Redis的复制内存buffer是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
如果因为网络状况不好,从节点在短时间无法和主节点进行同步,那么当网络状况恢复时,Redis的主节点中那些没有同步的指令zaibuffer中有可能已经被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同步,这个时候就需要更加复杂的同步机制-----快照同步
3.1.5 快照同步
是个非常耗费资源的操作
首先在主节点上进行一次bgsave,将当前内存的数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节点。从节点将快照文件接受完毕后,立即执行一次全量加载,加载之前要将当前内存的数据清空,加载完毕后通知主节点继续进行增量同步。
在整个快照同步的过程中,主节点的复制buffer还在不停的往前移动,如果快照同步的时间过长,或者复制buffer太小,都会导致同步期间的增量指令在复制buffer中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次进行快照同步,如此j极有可能陷入快照同步的死循环。
所以无比配置一个合适的复制buffer大小参数,避免快照复制的死循环。
3.1.6 增加从节点
当从节点刚刚加入到集群时,他必须进行一次快照同步,同步完成后再继续进行增量同步。
3.1.7 无盘复制
`当系统正在进行AOF的fsync操作时,如果发生快照同步,fsync将会被推迟执行,这就会严重影响主节点的服务效率。
从redis2.8.18开始,Redis支持无盘复制。就是主服务器通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存一边将序列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
3.1.8 wait指令
Redis的复制是异步进行的,wait指令可以让异步复制变身同步复制,确保系统的强一致性。是Redis3.0以后才出现的
set key value
wait 1 0
第一个参数是从节点的数量,第二个参数是时间,以毫秒为单位。
等待wait指令之前的所有写操作同步到N个从节点(也就是确保N个从节点的同步没有滞后),最多等待时间t。如果时间t=0,表示无限等待知道N个从节点同步完成。
如果出现了网络分区,wait指令第二个参数时间t=0,主从同步无法继续执行,wait指令会永远阻塞,Redis将丧失可用性。
3.2 李代桃僵----Sentinel
3.2.1 消息丢失
主从延迟特别大,那么丢失的数据就可能会特别多,Sentinel无法保证信息完全不丢失,但是也能尽量保证消息少丢失。
min-slaves-to-write 1
min-slaves-max-lag 10
第一个参数表示主节点至少有一个从节点进行正常复制,否则就停止对外写服务,丧失可用性。
何为正常复制:这是由第二个参数控制的,它的单位是s,表示如果在10s内没有收到从节点的反馈,就意味着从节点同步不正常,要么是网络断开了,要么是一直没有反馈。
3.3 分而治之----Codis
Redis集群方案之一
3.3.1 Codis分片原理
Codis默认将所有的key划分为1024个槽位(slot),他首先对客户端传过来的key进行crc32运算计算hash值,再将hash后的整数值对1024取余。
槽位数默认是1024,如果集群节点较多,建议设置为2048,4096等。
3.3.2 不同的Codis实例之间槽位关系如何同步
需要一个分布式配置存储数据库专门用来持久化槽位关系,Codis开始使用zookeeper,后来连etcd也一块只吃了。
3.3.3 扩容
在迁移过程中,Codis还是会接收到新的请求打在当前正在迁移的槽位上,因为当前槽位的数据同时存在新旧两个槽位中,Codis无法判断迁移过程中key存在哪个实例中,当Codis接收到位于正在迁移槽位中的key后,会立即强制对当前的单个key进行迁移,迁移完成后,再将请求转发到新的Redis实例。
3.3.4 自动均衡
Codis提供了自动均衡功能。会在比较空闲的时候观察每个Reids实例对应的slot数量,如果不平衡,就会自动进行迁移。
3.3.5 Codis的代价
不支持事务了,事务只能在单个redis实例中完成。
rename也很危险
单个集合结构的总字节容量不要超过1MB,如果放置社交关系数据,例如粉丝列表之类,可以考虑分桶存储,在业务上折中。
增加proxy作为中转层,多走一个网络节点,增加proxy的数量来弥补性能上的不足
集群配置中心需要zookeeper来实现
3.3.6 Codis的优点
Codis集群方案简单,将分布式的问题交给了第三方(zookeeper或etcd)去负责,自己就省去了复杂的分布式一致性代码的编写维护工作。
Reids cluster内部实现复杂,为了实现去中心化,混合使用了复杂的Raft和Gossip协议,还有大量的需要调优的配置参数
3.3.7mget指令的操作过程
可能会存在多个Redis实例中,Codis的策略是将key按照所分配的实例打散分组,然后依次对每个实例调用mget方法,最后将结果汇总为一个,在返回给客户端。
3.3.9 Codis的尴尬
被Redis官方牵着鼻子走,现在Redis cluster在业界已经逐渐流行起来。
3.3.10 Codis的后台管理
界面友好
3.4 众志成城----Cluster
Redis Cluster将所有数据划分为16348个槽位,它比Codis的1024个槽位划分的更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像Codis,不需要另外的分布式存储空间来存储节点槽位信息。
当RedisCluster客户端来连接集群时,也会得到一份集群的槽位配置信息,这样当客户端要查找某个key时,可以直接定位到目标节点。这一点不同于Codis,Codis需要通过proxy来定位目标节点,RedisCluster则直接定位。
客户端为了可以直接定位某个具体的key所在的节点,需要缓存槽位相关信息,这样才可以准确快速的定位到相应的节点。同时因为可能会存在客户端与服务器存储槽位信息不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
3.4.1 槽位定位算法
默认会对key使用crc16算法进行hash,得到一个整数值,然后对16384取余来得到具体槽位
RedisCluster还允许用户强制把某个key挂在特定槽位上。通过在key字符串里嵌入tag标记,这就可以强制key所挂的槽位等于tag所在的槽位
3.4.2 跳转
当客户端向一个错误的节点发出了指令后,该节点会发现指令的key所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连接这个节点以获取数据。
客户端在收到moved指令后,要立即纠正本地的槽位映射表。后续所有的key将使用新的槽位映射表。
3.4.3 迁移
在迁移过程中两个节点的槽位都存在部分key数据。客户端先尝试访问旧节点,如果对应的数据还在旧节点里面,那么旧节点正常处理。如果对应的数据不再旧节点里边,那么有两种情况,要么该数据在新节点里边,要不根本就不存在。旧节点不知道是哪种情况,所以它会向客户端返回一个-ASK targetNodeAssr的重定向指令。客户端收到这个重定向指令后,先去目标节点执行一个不带任何参数的ASKING指令,然后在目标节点再重新执行原先的操作指令。
3.4.5 网络抖动
RedisCluster提供了一种选项cluster-node-timeout,表示当某个节点持续timeout的时间失联时,才可以认定该节点出现故障,需要进行主从切换,如果没有这个选项,网络抖动会导致主从频繁切换(数据的重新复制)
还有一个选项cluster-slave-validity-factor作为倍乘系数放大这个超时时间来宽松容错的紧急程度。如果这个系数是0,那么主从切换是不会抗拒网络抖动的。如果这个系数大于1,它就变成了主从切换的松弛系数。
3.4.6 可能下线与确定下线
4 拓展篇
4.1 耳听八方----Stream
Redis5.0支持可持久化的消息队列
# *表示服务器自动生成ID
xadd codehole * name laoqian age 30
xadd codehole * name xiaoyu age 29
xlen codehole
# - 表示最小值, + 表示最大值
xrange codehole - +
# 指定最大消息Id的列表
xrange codehole - 1527849629172-0
xdel codehole 1527849609889-0
#长度不受影响
xlen codehole
# 删除整个stream
del codehole
4.1.4 独立消费
4.1.5 创建消费组
# 从头部开始消费
xgroup create codehole cg1 0-0
# 从尾部开始消费,只接受新消息,当前stream消息会全部忽略
xgroup create codehole cg2 $
# 获取stream信息
xinfo stream codehole
# 获取stream的消费组信息
xinfo groups codehole
4.1.6 消费
4.2 无所不知----info指令
info显示的信息分9大块
1.Server:服务器运行的环境参数
2.Clients:客户端相关的信息
3.Memory:服务器运行内存统计
4.Persistence:持久化信息
5.Stats: 通用统计数据
6.Replication:主从复制相关信息
7.CPU:CPU使用情况
8.Cluster:集群信息
9.KeySpace:键值对统计数量信息
info
info memory
into replication
4.2.1 Redis每秒执行多少次指令
redis-cli `在这里插入代码片`info stats | grep ops
redis-cli monitor
4.2.2 Redis连接了多少客户端
redis-cli info clients
4.2.3 Redis内存占用多大
redis-cli info memory | frep used |grep human
4.2.4 复制积压缓冲区多大
这个信息在replication块里
redis-cli info replication | grep backlog

4.3 拾遗补漏----再谈分布式锁
4.3.1 RedLock算法
加锁时,它会向过半节点发送set(key,value,nx=True,ex=xxx)指令,只要过半节点set成功,就认为加锁成功,释放锁时,需要向所有节点发送del指令
4.4 朝生暮死----过期策略
4.4.1 过期的key集合
Redis会为每个设置了过期时间的key放入一个独立的字典中,以后会定时遍历这个字典来删除到期的key。除了定时遍历外,还会使用惰性策略来删除过期的key。
Redis默认每秒进行10次过期扫描,过期扫描不会遍历过期字典中的所有的key,而是采用了一种贪婪的策略,步骤如下:
1.从过期字典中随机选出20个key
2.删除这10个key中已经过期的key
3.如果过期的key的比例超过1/4,就重复步骤一
同时,为了保证过期扫描不会出现循环调度,导致线程卡死的现象,算法还增加了扫描时间的上限,默认不会超过25ms。
4.4.3 从节点的过期策略
从节点不会进行过期扫描,从节点对过期的处理是被动的。主节点在key到期时,会在AOF文件里增加一条del指令,同步到所有的从节点,从节点通过执行这条del指令来删除过期的key
4.5 优胜略汰----LRU
在生产环境中我们是不允许Redis出现交换行为的,为了限制最大使用内存,Redis提供了配置参数maxmemory来限制内存超出期望大小。
当实际内存超出时,提供了几种可选策略:
1.noeviction:不会继续服务写请求,读请求可以继续进行。
2.volatile-lru:尝试淘汰设置了过期时间的key,最少使用的key优先被淘汰
3.volatile-ttl,比较key的剩余寿命,ttl越小越优先被淘汰
4.volatile-random:淘汰的key是过期key集合中随机的key。
5.allkeys-lru:要淘汰的key对象是全体的key集合
6.allkeys-random:随机key
4.6 平波缓进----懒惰删除
4.6.1 Redis为什么使用懒惰删除
del会直接释放对象的内存,
但是如果删除的key是个很大的对象,删除就会导致单线程卡顿。
引入了unlink指令,能对删除操作进行懒处理,丢给后台线程来异步回收内存
unlink key
4.6.2 flush
Redis提供了flushdb和flushall指令,用来清空数据库,这也是及其缓慢的操作,Redis4.0给这两个指令带来了异步化
flushall async
4.6.3 异步队列
4.6.4 AOF Sync也很慢
Redis需要每秒一次同步AOF日志到磁盘,确保消息尽量不丢失,也要用sync函数,这个操作比较耗时,会导致主线程的效率下降,所以Redis也将这个操作移到异步线程来执行。执行AOF Sync操作的线程是一个独立的异步线程,和前面的懒惰删除线程不是一个线程,同样他也有一个属于自己的任务队列,队列只用来存放AOF Sync任务。