目录
一、计算机分类导论
1.1 计算机视觉解决的基本问题
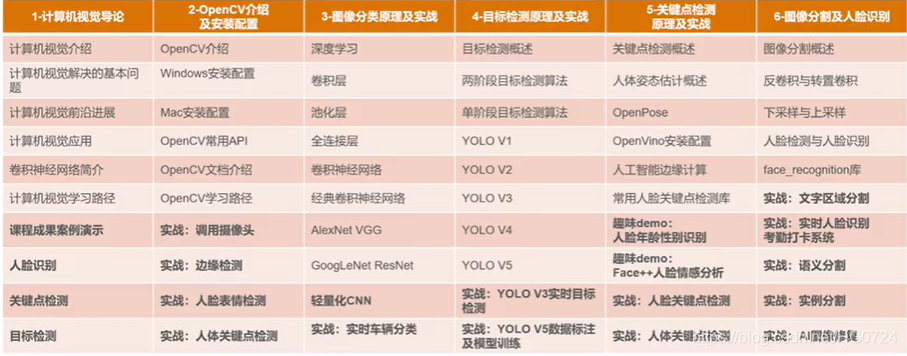
1.1.1 分类、检测、分割
- 如:现有一个识别1000个分类的模型,喂进去一张小猫图片,该模型可告诉我这是一只猫。即输入图像输出类别。这是一个黑箱子,也可以看作一个映射,从图像到类别的映射,类比函数y=ax+b(x:图片 y:类别[类别是离散的,可以是二分类也可以是多分类或是1000多种分类])。
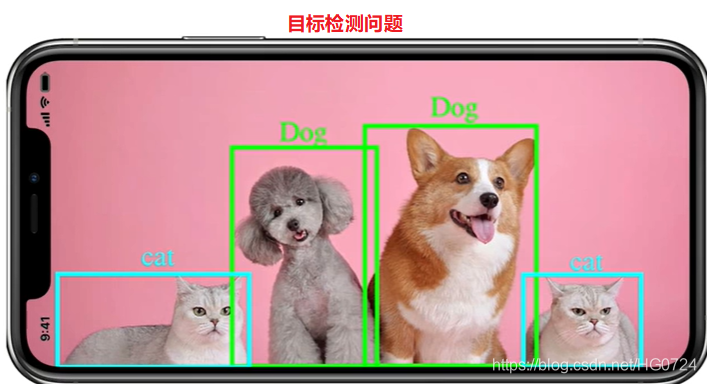
若不甘心与只得到类别信息,还想知道猫出现的位置(如画一个框框—>定位问题 Localization)定位问题往往图像中只有一只猫或者只有一个人或其他物体。若图像中有多个种类多个物体,那么只画一个框则不合适。
我们需要把不同种类的多个物体的框画出来,则该问题称为目标检测(Object Detection)(目标检测可以理解为画框框,这个框可以理解为每个物体的外接矩形/长方形,有了框我们就知道物体在图像中的定位信息。框只需要很少的参数就可以在图像中定位出来[四个参数:左上角(x,y)坐标、右下角(x,y)坐标即可画出框])。
框里的像素有的是真正的物体像素,有的是背景像素(这称之为冗余信息),我们不想要冗余信息,我们只想把物体的像素提取出来,像PS抠图一样,这样的问题称之为⭐分割问题Segmentation
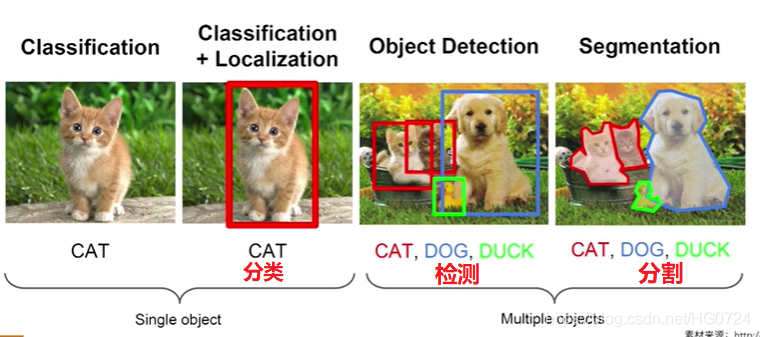
1.1.2 语义分割与实例分割
分割是对像素粒度进行分析(类似于PS抠图,每一个像素都需要精确到);
分类是对图像进行分析;
目标检测是对定位信息进行分析
检测和分割这种高级问题仍然需要依赖于分割模型的底层特征

-
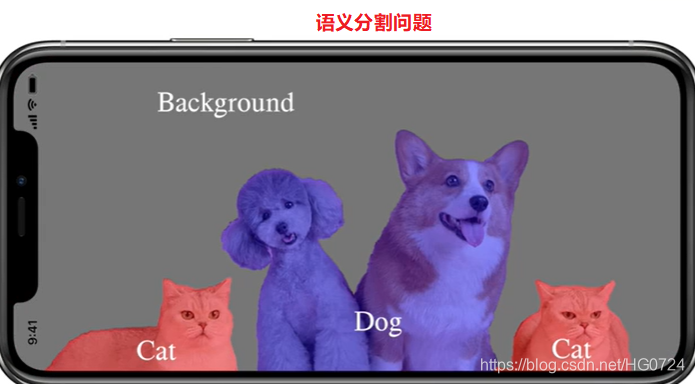
上图属于分类问题,输入一张图片输出它的类别。若分割的时候给每一个像素进行分类:即把所有属于猫的像素提取出来,所有的属于草地的像素提取出来,这样的分割属于语义分割(Semantic Segmentation)。在语义分割的场景下,如果有很多只猫,那么所有猫的像素被抠成一个颜色,我们并不知道图像中两只猫的分界线,而只知道图像中猫所属的类别。
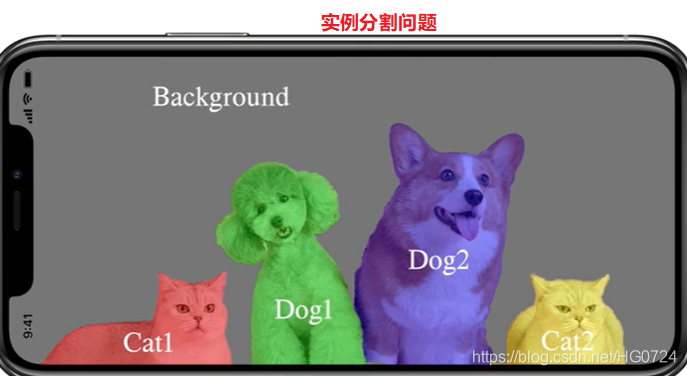
若图像中不同的物体抠成不同的颜色,则称为实例分割(Instance Segmentation)
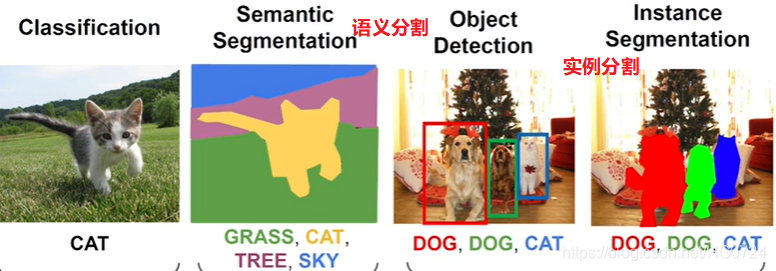
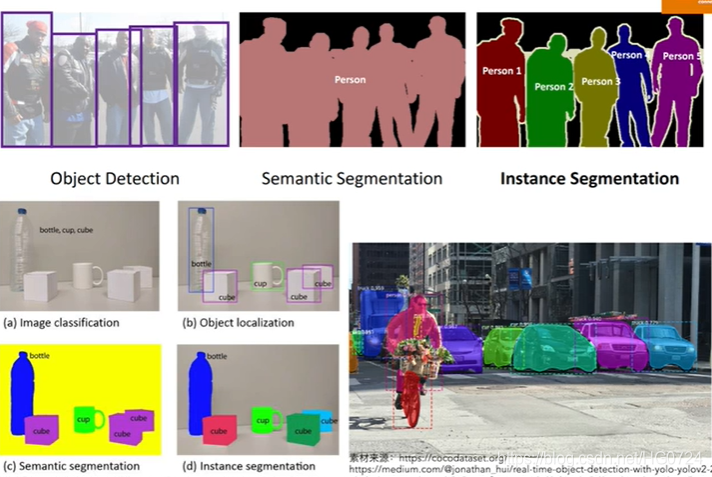
对于无人驾驶,实例分割甚至是全景分割非常的重要,我们需要让无人驾驶汽车知道哪里是马路牙子,哪里是其他车,哪里是行人,哪里是交通灯。

其实,语义分割和分类有些相似,实例分割和目标检测有些相似。
语义分割可以看作是对每个像素进行单独分类。除此之外,还有关键点检测,关键点检测:把图像中关键的点找到,例如人体的关节,找到把关键点连接起来,我们就会知道此时这个人在做些什么。

-
定位和目标检测的区别:
定位只需画一个框;
目标检测则需要多个物体画多个狂


- 人体姿态关键点检测应用:
养老院的摔倒检测
高尔夫球
投篮
3D动作的捕捉
。。。。
二、计算机视觉的前沿进展
深度学习,特别是计算机视觉是非常依赖海量的数据。
深度学习有三架马车:
- 计算机硬件的算力 :CPU、GPU、TPU、FPGA或者是更强的边缘计算的硬件
- 数据:特别是经过标注好的结构化的数据:ImageNet 数据集(有几百万张经过标注好的图片)
- 算法。如何高效的训练?如何防止过拟合?

- 以下为模型
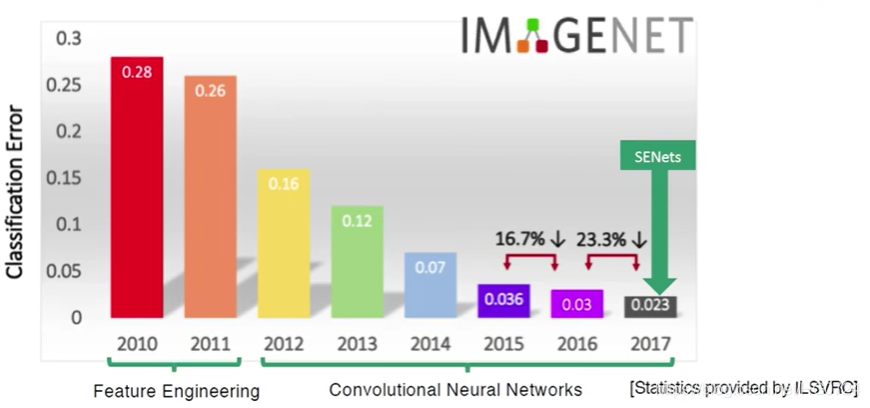
模型彼此各不相同,不同模型有不同准确率,参数数量,内存占用大小。
每一幅图片模型都会预测出很多个结果,这些结果是按照概率执行度从大到小的,模型先把他最认为的结果展示出来,再把第二个模型人文的结果展示出来,以此类推,直到把可能性最小的结果展示出来。
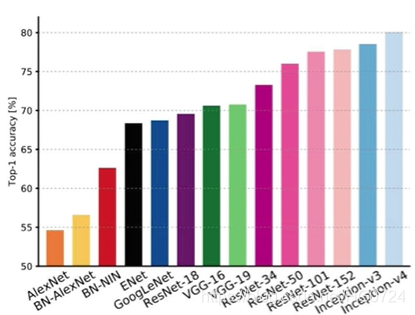
Top1表示模型认为最可能的结果正好就是答案结果。Top5表示模型预测的前5个结果里边包含正确答案的结果。
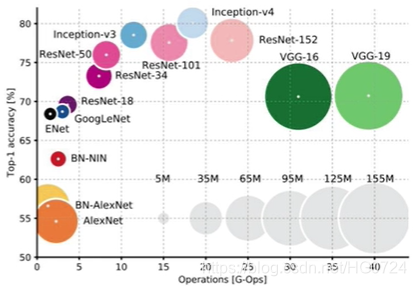
不同模型的计算量、参数数量、还有准确率之间的关系。圈越大表示参数量越多、圆心越靠右白哦是计算量越大、圆心越靠上准确率越高。
即:一个模型又靠左、又靠上、圈还小则是一个不错的模型。
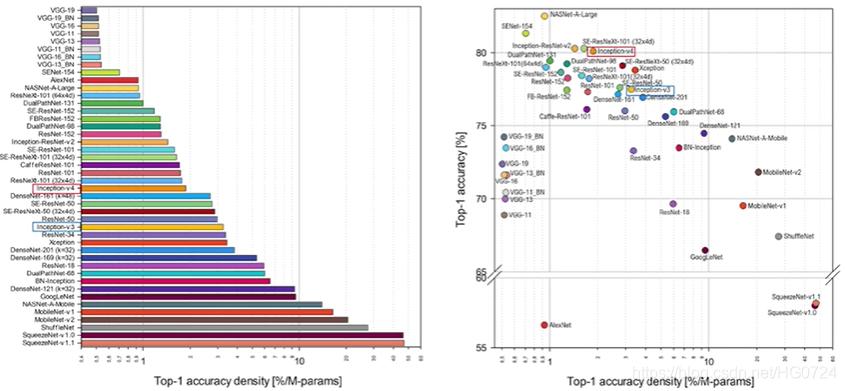
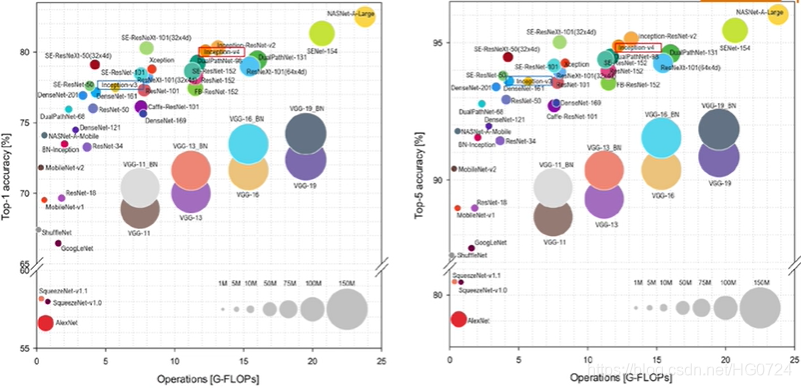
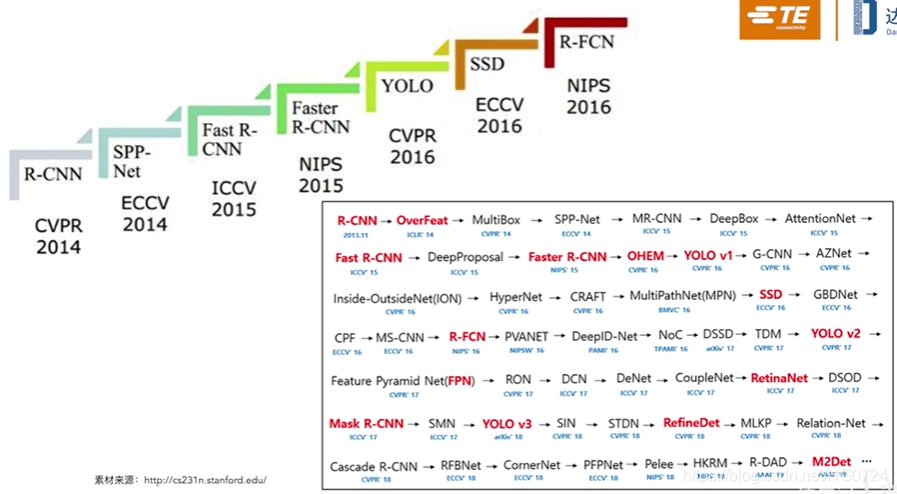
- 目标检测领域的方法主要分为两种:
第一种是两阶段方法。两阶段意思是我们需要先从图像中提取候选框,再对每一个候选框进行逐一的甄别,最终把置信度高的候选框筛选出来,展示出最后的结果。像R-CNN、SPP-NET、Faste R-CNN、Faster R-CNN。
优点:准确率高
缺点:速度慢。
第二种是单阶段方法。像YOLO、SSD。单阶段不需要提取候选框,只需要把图片喂进去,就能够生成结果。
好处:非常快,特别是⭐YOLO
(标红的是比较重要的模型)
- 计算机视觉该如何入门?
学习资料,ImageNet的提出者
参考资料 Reference:

三、课程成果案例演示
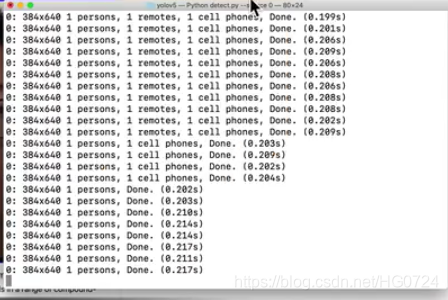
- YOLOV5实时目标检测
每一帧检测到的物体个数以及置信度都会显示到命令行,进行实时调试

-
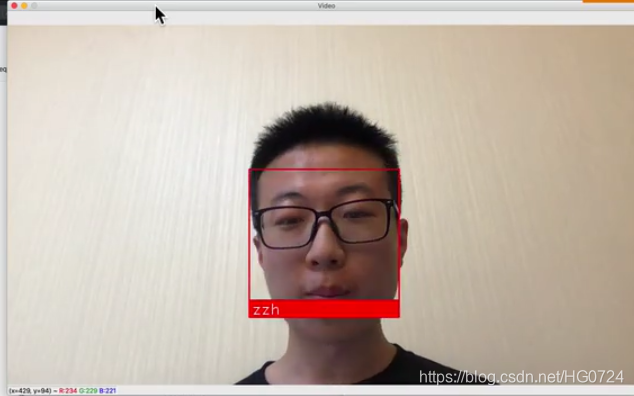
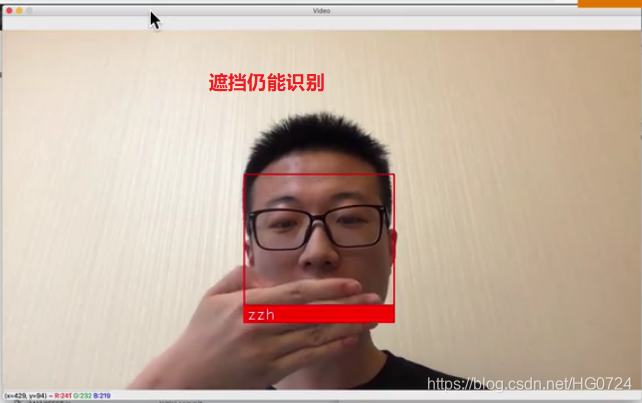
实时人脸识别


-
实时人体姿态关键点检测
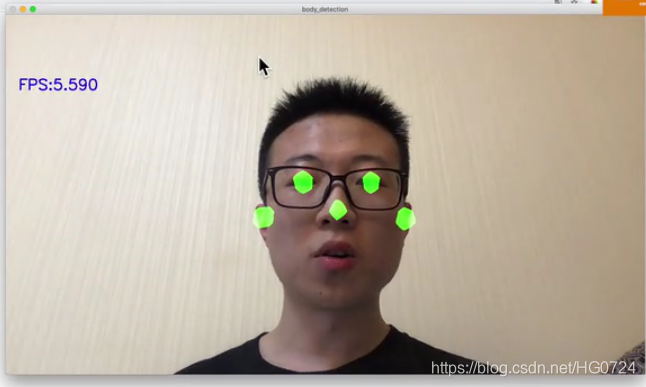
-
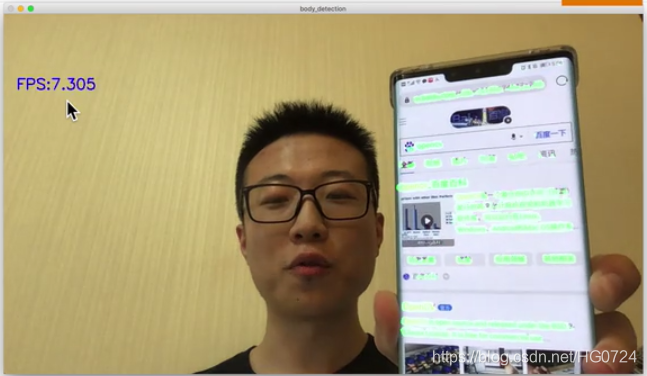
实时文字区域分割
FPS:每秒钟可以处理的帧数 (数字越高表示每秒钟可以处理的图像数越多)
应用场景:出国旅游的翻译软件
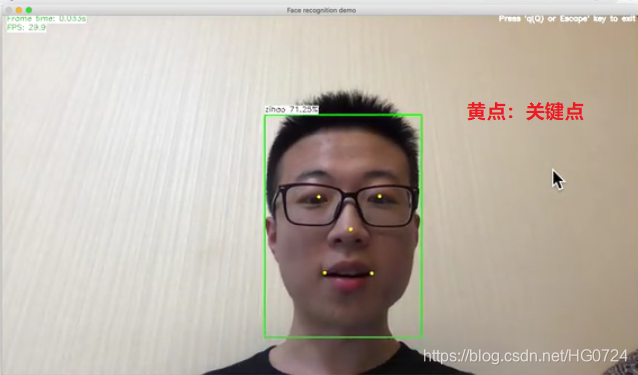
- 实时人脸检测、识别、关键点检测
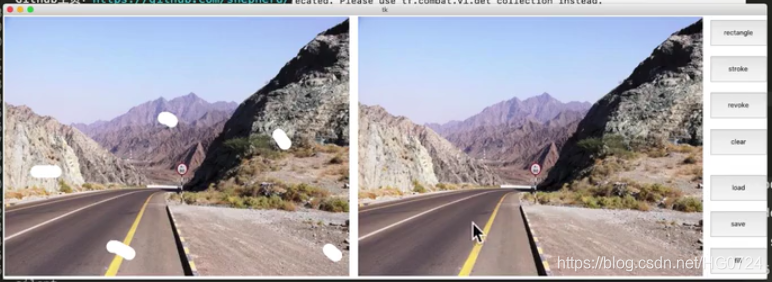
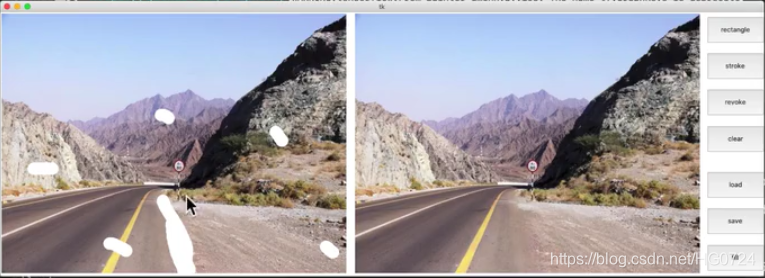
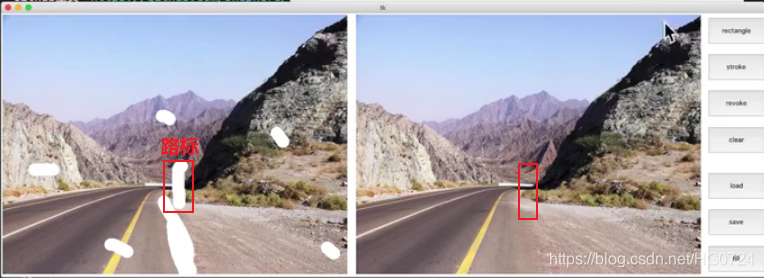
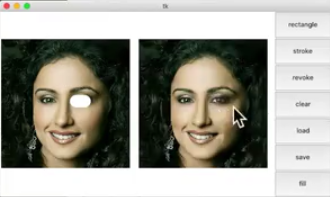
- AI图像修复
不仅用到了像素层面的信息,更用到了深度神经网络的机器学习的语义信息
总结
分类、检测、分割、定位是基础,要在理解的基础上掌握他们的差别。