以chrome为例
微博页数的显示只有网址后面的page在变化,这个就很容易获取到每页动态的网址,当然直接get是获取不到的,记得带上cookie
最主要的是微博是网页分段加载的,没有办法一次性获取到全部内容,那么就要找到它中途又发送了那些请求

可以看到这个新的url,也就是我们需要的url
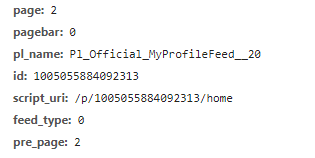
然后可以发现,区别就在于这个pagebar,pagebar的值在为0和1时分别又加载了一次网页,因此,我们发送请求时就要加上这个pagebar
page和pre_page数值相同,虽然在当前页面并没有改变,但是也还是不能忽略,要带着这两个参数,然后,就可以获得返回的json数据
之后就获取想要的内容就好了
代码样例为获取前十页每条动态的文字信息:
import requests
from lxml import etree
import json
headers = {
'Accept': '*/*',
'Connection': 'keep-alive',
'Cookie': 'SINAGLOBAL=7547742164796.669.1557814374521; wvr=6; UOR=vjudge.net,widget.weibo.com,www.baidu.com; Ugrow-G0=d52660735d1ea4ed313e0beb68c05fc5; login_sid_t=5355b1f41984fbcab1e7f06ce5e56348; cross_origin_proto=SSL; TC-V5-G0=28bf4f11899208be3dc10225cf7ad3c6; WBStorage=f54cf4e4362237da|undefined; _s_tentry=passport.weibo.com; Apache=137824208234.45386.1567069036053; ULV=1567069036066:8:4:2:137824208234.45386.1567069036053:1566997217080; wb_view_log=1366*7681; SCF=Ah0xAfGqEnBKvHeo0pUZh35Mu9kMRIv3xACyV4NhxHz6vEmrCbVYAZNMkq28jwwjv3izlLBbVs0-1wHJgB802KI.; SUB=_2A25wY-PeDeRhGeBH6lcQ9SrMyjmIHXVTGVIWrDV8PUNbmtAKLUfgkW9NQcb_zmmXRFBtE4vRVttRPlpfY4_u__na; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5PjVhlq3PienOo1MfYibdR5JpX5KzhUgL.Foq4eK-pSKB7eK-2dJLoIpzLxKMLBK-LBKBLxKqLBo.LB-zt; SUHB=0KAhxcJ_lXGMkr; ALF=1598605070; SSOLoginState=1567069071; wb_view_log_6915154015=1366*7681; webim_unReadCount=%7B%22time%22%3A1567069360213%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D; TC-Page-G0=ac3bb62966dad84dafa780689a4f7fc3|1567069357|1567069073', 'Host': 'weibo.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page={}'+'&pagebar={}'+'&pl_name=Pl_Official_MyProfileFeed__20&id=1005055884092313&script_uri=/p/1005055884092313/home&feed_type=0&pre_page={}'+'&domain_op=100505&__rnd=1567077491458'
url2 = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100505&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page={}&pl_name=Pl_Official_MyProfileFeed__20&id=1005055884092313&script_uri=/p/1005055884092313/home&feed_type=0&domain_op=100505&__rnd=1567077491458'
def parse_response(response,fp):
json_data=json.loads(response)
data = json_data['data']
tree = etree.HTML(data)
weibos = tree.xpath('//div[@class="WB_detail"]/div[@class="WB_text W_f14"]')
for i in range(len(weibos)):
content = weibos[i].xpath('string(.)')
content = str(content).strip()
fp.write(content+'\n\n')
def main():
fp = open('test.txt','w',encoding='utf-8')
global url, url2
for i in range(1,11):
response = requests.get(url=url2.format(i), headers=headers).text
parse_response(response, fp)
for page in range(2):
response = requests.get(url=url.format(i,page,i), headers=headers).text
parse_response(response, fp)
fp.close()
if __name__ == '__main__':
main()