个人微信公众号

1、深度学习基础
1、为什么需要做特征归一化、标准化
1.使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使得模型更准确率
2、加快算法的收敛速度
2、常用的归一化和标准化方法有哪些?
1、线性归一化(min-max标准化)
x’ = (x-min(x)) / (max(x)-min(x)),其中max是样本数据的最大值,min是样本数据的最小值
适用于数值比较集中的情况,可使用经验值常量来来代替max,min
2、标准差归一化(z-score 0均值标准化)
x’=(x-μ) / σ,其中μ为所有样本的均值,σ为所有样本的标准差
经过处理后符合标准正态分布,即均值为0,标准差为1
3、非线性归一化
使用非线性函数log、指数、正切等,如y = 1-e^(-x),在x∈[0, 6]变化较明显, 用在数据分化比较大的场景
介绍一下空洞卷积的原理和作用
空洞卷积也就膨胀卷积、扩展卷积,最初的提出是为了解决图像分割在用下采样(池化、卷积)增加感受野带来的特征图缩小,后再上采样回去的时候造成的精度上的损失。空洞卷积通过引入了一个扩张率的超参数,该参数定义了卷积核处理数据时各值的间距。
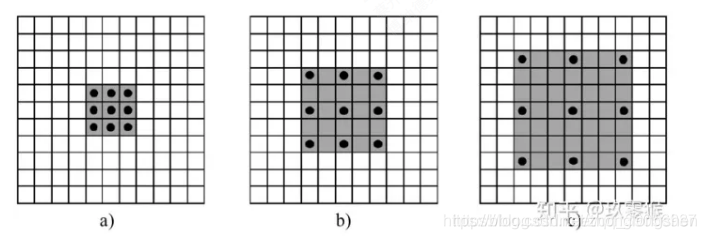
可以在增加感受野的同时保持特征图的尺寸不变,从而替换下采样和上采样,通过调整扩张率得到不同的感受野大小。
- a是普通的卷积过程(dilation rate = 1),卷积后的感受野为3
- b是dilation rate = 2的空洞卷积,卷积后的感受野为5
- c是dilation rate = 3的空洞卷积,卷积后的感受野为8
可以这么说,普通卷积是空洞卷积的一种特殊情况。
怎么判断模型是否过拟合,有哪些防止过拟合的策略?
在构建模型的过程中,通常会划分训练集、测试集。
当模型在训练集上精度很高,在测试集上精度很差时,模型过拟合;当模型在训练集和测试集上精度都很差时,模型欠拟合。
预防过拟合策略:
- 增加训练数据:获取更多数据,也可以使用数据增强、增样等。
- 使用合适的模型:使用减少网络的层数,降低网络参数量。
- Dropout:素以及抑制网络中的一部分神经元,使得每次训练都有一批神经元不参与模型训练。
- L1、L2正则化:训练时限制权值的大小,增加惩罚机制,使得网络更稀疏
- 数据清洗:去除问题数据,错误标签和噪声数据
- 限制网络训练时间:在训练时将训练集和测试集损失分别输出,当训练集损失持续下降,而验证集损失不在下降时,网络就开始出现过拟合,此时就可以停止训练了。
- 在网络中使用BN(Batch Normalization)也可以一定程度上防止过拟合
除了SGD和Adam之外,你还知道哪些优化算法?
主要有三大类:
1:基础梯度下降法:SGD,BGD
2:动量优化法:包括momentum、NAG等
3:自适应学习率优化法:包括Adam,AdaGrad,RMSProp等
训练神经网络有哪些调参技巧
阐述一下感受野的概念
感受野指的是卷积神经网络每一层输出的特征图上每个像素点映射会输入图像上的区域的大小,神经元感受野的范围越大表示其接触到的原始图像范围越大,也就意味着它能学习更为全局,语义层次更高的特征信息,相反,感受野范围越小则表示包含的特征越趋向局部和细节。因此感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显的知道网络越深,神经元的感受野越大。

卷积层的感受野大小与其之前层的卷积核尺寸和步长有关,与padding无关。
举例子说明:
感受野即CNN能看到的视野大小。比如,一个3x3的卷积层,卷积核个数=1,步长stride=1,padding=1,一个形状为(N, C, H, W)的张量tensor1,经过这个卷积层之后,变成了形状为(N, 1, H, W)的张量tensor2。那么新张量tensor2一个像素里包含了tensor1多少个像素的信息呢?3x3=9个。张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素9宫格像素的内容,也就是说张量tensor2感受野是3x3大小了。假如我把卷积层换成了1x1卷积层呢?那么只能“看到”原始特征图张量tensor1相同位置像素的内容,也就是说张量tensor2感受野是1x1大小。我再变点花样,tensor1经过了2个卷积层,第一个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,第二个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,tensor1经过了这2个卷积层变成了张量tensor2,敢问张量tensor2感受野大小?5x5,张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素附近5x5像素的内容。我再变点花样,tensor1经过了2个卷积层,第一个卷积层是3x3大小,卷积核个数=1,步长stride=2,padding=1,第二个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,tensor1经过了这2个卷积层变成了张量tensor2,敢问张量tensor2感受野大小?7x7,张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素附近7x7像素的内容。我们可以看到,叠加卷积层可以扩大感受野大小,卷积步长也会影响感受野大小。
下采样的作用是什么?通过有哪些方式?
下采样有两个作用,一个减少计算量,防止过拟合;二是增大感受野,是的后面的卷积核能够学到更过全局的信息,下采样的方式主要有两种:
1、采用stride为2的池化层,如Max-pooling和Average-pooliing。目前通常使用max-pooling,因为他计算简单而且能够很好的保留纹理特征。
2、采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来替换pooling可以得到更好的效果,当时同时也增加了一定的计算量。
上采样的原理和常用方式
在卷积神经网络中,由于输入图像通过卷积神经网络提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进一步的计算(如图像的语义分割),这个使得图像由小分辨率映射到大分辨率的操作,叫做上采样,它的实现一般有三种方式:
1:插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他差值方式复杂。但是相对于卷积计算可以说不值得 一提,其他插值方式还有最邻近插值,三线性插值。
2:转置卷积又或是反卷积,通过对输入feature map间隔填充为0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大。
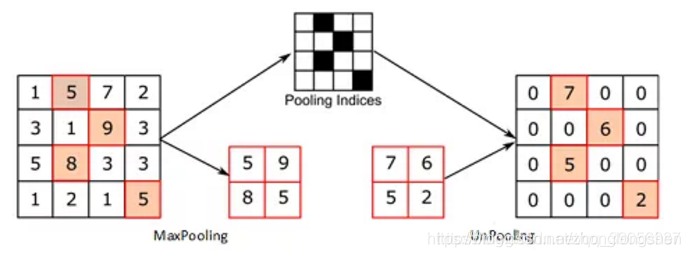
3:Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0;
模型的参数量指的是?怎么计算?
模型的FLOPS(计算量)指的是什么?怎么计算?
深度可分离卷积的概念和作用
深度可分离卷积将传统的卷积分两步进行,分别是depthwise和pointwise。首先按照通道进行