摘要
本文是一篇Phoenix综述文章,不断更新中。
0x01 Phoenix基础概念
1.1 Phoenix是什么
- Phoenix最早是saleforce的一个开源项目,后来成为Apache基金的顶级项目。。
- Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC API而不是简陋的HBase API来对HBase数据进行操作。
- Phoenix查询引擎会将SQL转换为若干HBase查询,并编排执行。普通查询响应时间能达到毫秒级。
1.2 设计目标
通过定义明确的行业标准API,使得Phoenix成为Hadoop的OLTP和OLAP的可靠的数据平台。
0x02 Phoenix架构
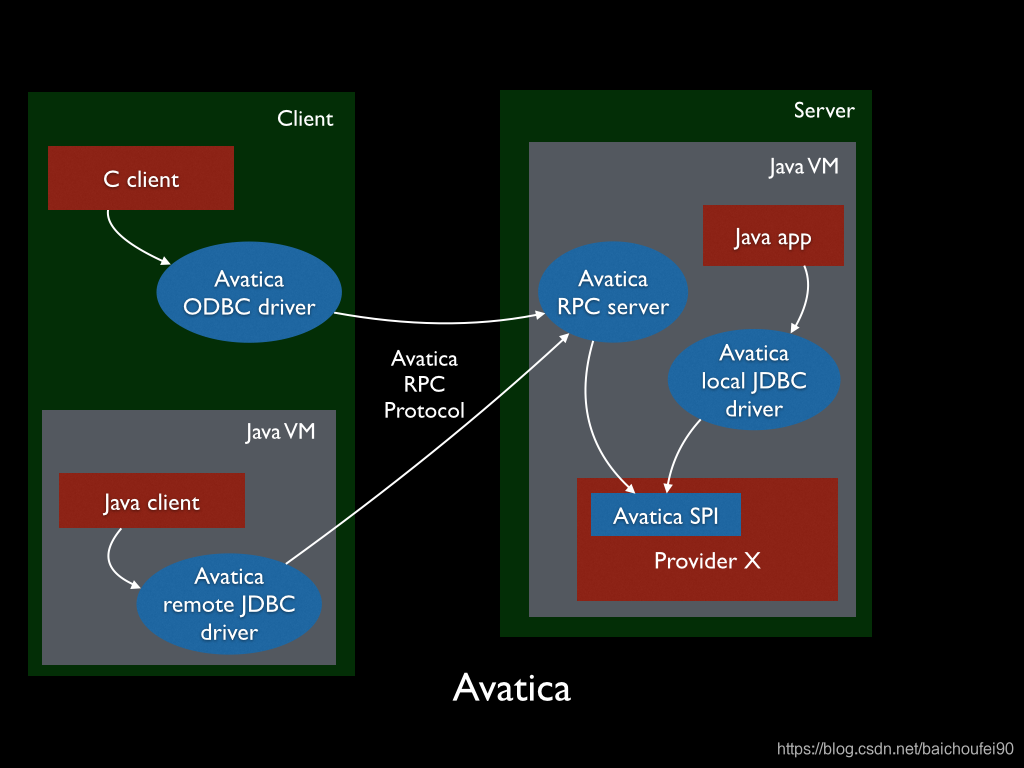
2.1 QueryServer
用户能通过Phoenix Query Server在Phoenix于HBase之间交互。该QueryServer属于StandAlone设计,服务对象是thin-client。
QueryServer使用了Apache Calcite的子项目Avatica实现Phoenix-JDBC。
-
Apache Calcite
是一个构建高性能数据库的基础框架,主要特性是- 标准的sql解析器,并带有验证器和JDBC Driver
- 查询优化:以关系代数来表示查询语句,使用执行计划规则进行转换,并根据成本模型进行优化(CBO)。
- 连接第三方数据源,方便浏览元数据,并以将计算推到数据侧的方式进行优化
- 子项目为
Avatica
-
Avatica
是一个构建数据库Driver的框架。其重要概念是wire API,可由JSON或Protobuf定义,服务于JDBC Driver客户端<->Http服务端。这样的设计可使得Client的实现语言不受约束。
0x03 Phoenix Schema
3.1 表创建
Phoenix用CREATE TABLE创建的表元数据存放在HBase。创建方式有以下两类:
- 创建全新的表
Phoenix会自动在HBase创建表和列族等 - 映射到已存在的HBase表。
需要注意,目标HBase表的RowKey和KeyValue的二进制格式必须满足Phoenix的数据类型约束,否则不行。可以创建两种类型:- 读写表
自动创建不存在的列族,并添加空KeyValue到现有行的第一个列族,以最小化查询投影的大小 - 只读视图(View)
所有列族必须已存在。还会在HBase表上增加Phoenix的协处理器,用来加速查询处理。因不可修改原表,所以查询性能可能低于创建读写Phoenix表。原因可回到上面看看读写表。
- 读写表
3.2 表修改
ALTER TABLE可修改表。4.7版本中可以在DDL中指定到HBase更新元数据的频率。
10分钟刷新元数据频率的表:
CREATE TABLE
FOO (k BIGINT PRIMARY KEY, v VARCHAR)
UPDATE_CACHE_FREQUENCY=600000;
0x04 SQL执行流程
0x05 Phoenix事务
HBase只支持行级事务,Phoenix通过与Apache Tephra集成,增加了对跨行、跨表的事务ACID语义的支持。 Tephra通MVCC提供并发事务的快照隔离。
0x06 其他重要概念
6.1 多租户(Multi tenancy)
通过多租户表及指定不同的租户连接(只能访问属于该租户的数据),实现数据访问的隔离。租户只能看到自己的多租户表中的数据,但非多租户表对所有租户可见。
还可以在做租户表上创建租户视图。
定义多租户表语句如下:
CREATE TABLE base.event (tenant_id VARCHAR, event_type CHAR(1), created_date DATE, event_id BIGINT)
MULTI_TENANT=true;
该表与多租户连接联合使用,第一个主键列代表租户,使得租户只能看到该表内租户id为当前连接租户的数据。而常规连接使用该类表没有限制。
6.2 Salted Tables
Phoenix Salted Table实现策略类似于之前提到过的HBase中的加盐,避免数据热点。
只需通过在创建表的时候指定:
CREATE TABLE test.chengc_0104 (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 5;;
会自动在集群region中划分RowKey 边界:
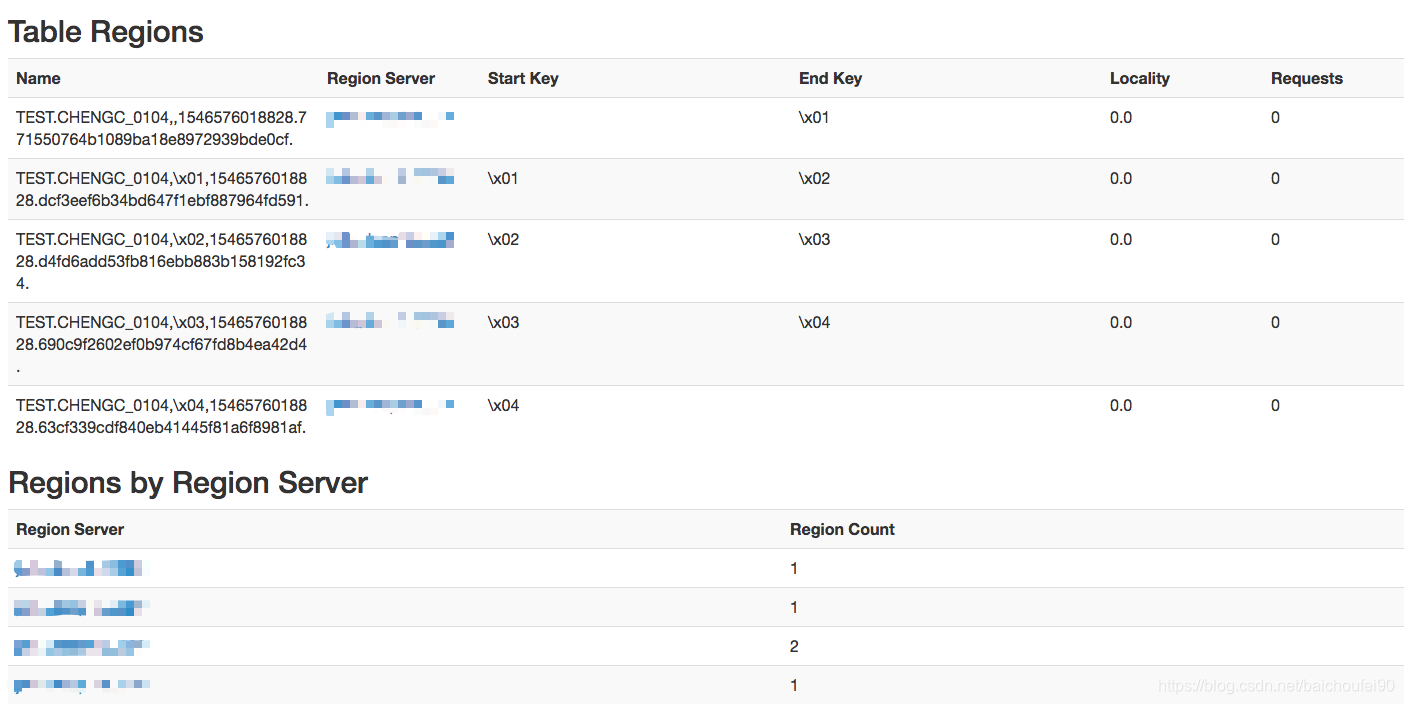
每个Region中的KeyValue拥有相同的salt byte,因此是排序的。当跨多个RegionServer执行并行的scan时,可以利用有序性的特点来在客户端执行归并排序,最终结果仍然有序。
使用RowKey排序的scan方法是在hbase-sites.xml中设置phoenix.query.rowKeyOrderSaltedTable为true。此时就不能再用户自定义加盐表的拆分点,也就是说Phoenix来设定拆分点,保证每个Region上的Key拥有相同salt byte。
使用Salted Table和预分区技术,可以使得数据写入均衡到各个RS中,大大提升写入性能,比起不使用该技术的表的性能提升达到80%。
6.3 二级索引
6.3.1 简介
在HBase中,只有单一的按字典序排列的rowKey作为索引。当查询使用rowKey速度很快,但不是用时会造成full scan,效率底下。
Phoenix中提供了二级索引,是一种rowKey之外的有效备选方案。他分为Covered Indexes(覆盖索引)、Functional Indexes(函数索引)。
6.3.2 Covered Indexes
覆盖索引行就已经包含目标数据,不用再回原表查询,效率很高。
下面这个sql就是在v1和v2上建立了覆盖索引,同时包含了v3列。
CREATE INDEX my_index ON my_table (v1,v2) INCLUDE(v3)
那么查询v1和v2时就不用再回原表找v3列了。
6.3.3 Functional Indexes
Phoeinx4.3以后开始支持函数索引。其索引不局限于列,还能用于任意的表达式,当在查询时用到了这些表达式时就直接返回表达式结果。
下面这个例子,创建了一个函数索引。
CREATE INDEX UPPER_NAME_IDX ON EMP (UPPER(FIRST_NAME||' '||LAST_NAME))
那么,就可以用以下函数直接在索引表查找FIRST_NAME+ ' ' + LAST_NAME并转为大写等于JOHN DOE的行,而不用回表查询。
SELECT EMP_ID FROM EMP WHERE UPPER(FIRST_NAME||' '||LAST_NAME)='JOHN DOE'
6.3.4 索引策略
目前Phoenix有Global Indexes(全局索引)、Local Indexes(本地索引)两种索引生成策略。
6.3.4.1 Global Indexes
- 全局索引适用于读很多的场景。
- 全局索引在数据写入时,拦截写入请求(DELETE和UPSERT),然后据此将相关的更改写入到所有相关的索引表。也就是说,全局索引的主要开销为写入时。
- 读数据时,Phoenix自动挑选那些能产生最快查询的索引表,然后直接在该索引表执行
scan操作。 - 需要注意的是,除非显示声明,否则当查询的列不在索引表列时不会使用全局索引。
- 全局索引主要开销为写入时
6.3.4.2 Local Indexes
- 本地索引适用于写很多、空间有限的场景
- 本地索引中的
本地,是指索引表的数据和原表数据在同一个RegionServer,可避免写入数据和索引时的数据传输带来的网络开销。特别是在Phoenix 4.8.0以后,直接将本地索引作为了原表的一个列族。 - 与全局索引相同,Phoenix会自动判定在进行查询时是否使用本地索引
- 与全局索引不同,当查询的若干列中的一部分属于索引表列时也会使用本地索引。其余列回原表查询。
- 使用本地索引读取数据时,必须检查每个Region,因为不能直接确定索引数据位置。所以这一点和全局索引不同,
- 本地索引在读取时也有不菲的开销
6.4 SCAN
Phoenix SCAN分为 RANGE SCAN, FULL SCAN, SKIP SCAN 及 DEGENERATE SCAN:
6.4.1 RANGE SCAN
RANGE SCAN是指,仅扫描表中的一部分行。如果您使用主键约束中的一个或多个前导列,则会发生这种情况。
比如DDL语句:
CREATE TABLE TEST
(pk1 char(1) not null, pk2 char(1) not null, pk3 char(1) not null,
non-pk varchar CONSTRAINT PK PRIMARY KEY(pk1, pk2, pk3));
那么下面的SQL就不是在前导主键列上使用过滤:
select * from test where pk2='x' and pk3='y';
此sql会导致FULL SCAN。
而下面的SQL则会使用RANGE SCAN:
select * from test where pk1='x' and pk2='y';
这就跟Mysql索引中的最左前缀的要求一样。解决方法是在pk2和pk3列上建立二级索引,就可以利用索引表使用RANGE SCAN了。
6.4.2 FULL SCAN
FULL SCAN意味着将扫描表的所有行(但如果sql中包含WHERE子句,则可能会应用过滤器)
6.4.3 SKIP SCAN
Phoenix使用SKIP_SCAN应对行内scan。当根据给定的一组键检索行时,与Range Scan相比能显着提高性能。
他的原理是利用了HBase Filter的SEEK_NEXT_USING_HINT。 它存储了每个列中正在被搜索的key set/range的信息。 然后它接收一个key(在过滤器评估期间传递给它),并确定该key是否在其中一个set或range内。 如果没有,它会计算出要跳到的下一个目标最大key值。
SkipScanFilter的输入是List <List <KeyRange >>。
- 最外层list表示RowKey中的每一列(即每个主键部分)
- 内部list表示对字节阵列边界进行OR运算。
考虑下面这个SQL:
SELECT * from T
WHERE ((KEY1 >='a' AND KEY1 <= 'b') OR (KEY1 > 'c' AND KEY1 <= 'e'))
AND KEY2 IN (1, 2)
那么以上这个sql对应的SkipScanFilter为[ [ [ a - b ], [ d - e ] ], [ 1, 2 ] ]
[ [ a - b ], [ d - e ] ]代表KEY1的范围
[ 1, 2 ] 代表KEY2范围

上图就是一个SKIP_SCAN示意图。
- 黄色代表满足SKIP_SCAN,并直接跳跃到下一个最高的key。
- 白色代表被直接跳过的key。
- 当[<KEY1,b>, <KEY2,1>]满足条件后,SKIP_SCAN会评估下一个最高key
[<KEY1,b>, <KEY2,2>],然后该row并不存在,所以直接跳到下一个最高的key[<KEY1,d>, <KEY2,1>]
如果前导主键列上没有过滤器,则不执行SKIP SCAN,但您可以使用/ + SKIP_SCAN /来强制执行。
在某些情况下,即当前导主键列的基数较低时,它将比FULL SCAN更有效。
6.4.4 DEGENERATE SCAN
DEGENERATE SCAN意味着查询不可能返回任何行。 如果我们可以在编译时确定,那么我们甚至可以不运行该``scan。
0x07 优化
7.1 Salting Table
前面已经提到过了,加盐表+预分区可以提升HBase集群负载均衡能力,大大提升读写能力。
示例:
CREATE TABLE TEST
(HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR)
SALT_BUCKETS=16
7.2 预分区
示例:
CREATE TABLE TEST
(HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR)
SPLIT ON ('CS','EU','NA')
7.3 使用若干列族
将经常查询、强相关的列放在一个列族,提升数据读取效率。
创建A B两个列族的sql:
CREATE TABLE TEST
(MYKEY VARCHAR NOT NULL PRIMARY KEY,
A.COL1 VARCHAR, A.COL2 VARCHAR,
B.COL3 VARCHAR)
7.4 压缩
对大表做磁盘压缩,实例:
CREATE TABLE TEST
(HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR)
COMPRESSION='GZ'
7.5 使用索引
7.6 HBase调优
7.7 Phoenix调优
0x08 HBase改造实践
8.1 数据多版本支持
8.2 语句严格模式
8.3 权限管理
8.4 系统核心指标统计
8.5 使用审计
8.6 慢查询统计
0x09 性能
0x10 Phoenix FAQ
完整版可参考Phoenix-FAQ
10.1 Phoenix有多快?为什么Phoenix这么快
- Phoenix对一亿行的表(中等大小的集群上的窄表),执行full scan 通常在20秒内返回。
- 如果查询包含了在主键列上的
filter,那查询时间会减少到毫秒级。 - 对于非主键列或非前导键列,可添加索引提升性能表现,甚至和对主键列key使用过滤器效果相当
10.2 为什么执行FULL SCAN依然很快?
- 并行执行查询
Phoenix使用Region的边界来将查询进行分块,并使用可配数量的线程在客户端上并行运行Phoenix使用Region的边界来将查询进行分块,并使用可配数量的线程在客户端上并行运行 - 协处理器处理数据聚合
聚合将在服务器端的协处理器中完成,大大减少返回给客户端的数据量。
10.3 应该使用PhoenixJDBC连接池吗?
不应该。
因为Phoenix的JDBC连接和大多JDBC客户端不同,他是一个很轻的组件,创建开销很低,底层是到HBase的连接。
如果重用Phoenix连接池,可能会因为前一个用户没有将底层使用的HBase连接保持健康状态,从而使得复用的用户使用该不健康的HBase连接导致意外的问题。
所以不要用连接池复用Phoenix连接。